我們在 day28 介紹了 HttpRunner 的測試用例分層機制,
提到了TestSuite 層不應該有邏輯,而是為了把 測試案例和測試資料結合。
TestSuite 是 TestCase 的 無序 集合,集合中的測試用例應該都是相互獨立,不存在先後依賴關係的。
也就是說,TestSuite 應該只負責組織測試案例 和 組織測試資料,
今天將使用 day29 的 Code 來說明 HttpRunner 的 參數化資料驅動 測試機制。
在 TestSuite yml 裡可以用 parameters,設定 參數化資料驅動 變數。
P函數 引用 CSV 文件,這種方式需要準備 CSV 數據文件,適合數據量比較大的情況。debugtalk.py 中自定義的函數生成參數列表,這種方式最為靈活,可通過自定義 Python 函數實現任意場景的資料驅動機制,當需要動態生成參數列表時可選擇這種方式。keyword: ["httprunner", "testcafe"]config:
name: "testsuite google search"
base_url: ${ENV(base_url)}
testcases:
- name: call validate_title
testcase: testcases/validate_title.yml
parameters:
keyword: ["httprunner", "testcafe"]
cd day29
hrun testsuites/data-in-testsuite.yml
測試報告可以看到,完成2 個測試案例,validate title "httprunner",validate title "testcafe",這就是 HttpRunner 參數化資料驅動的威力,
使用 parameters 定義測試資料,就能利用資料完成多種測試情境。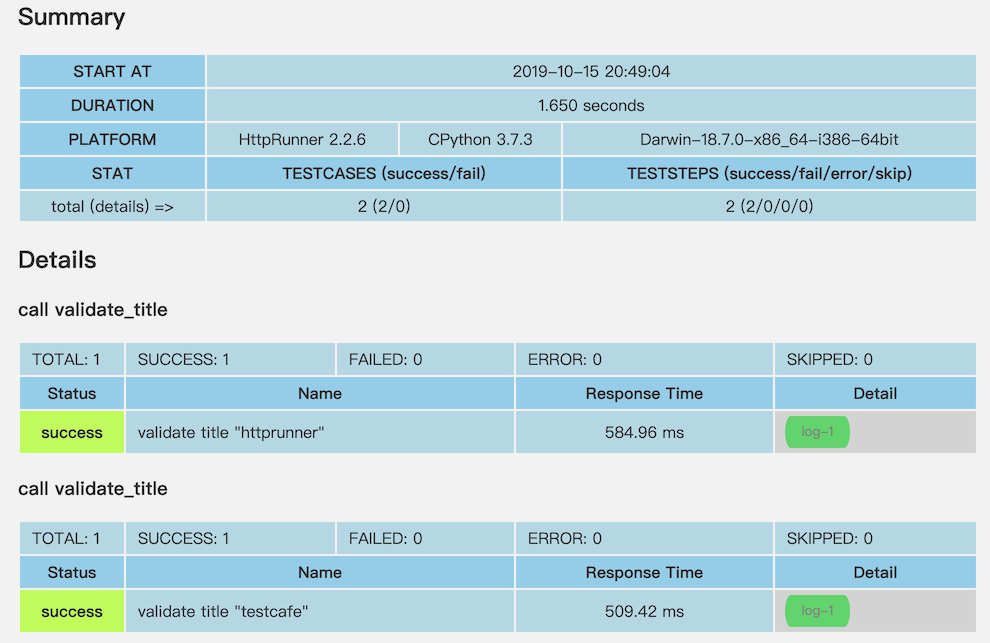
P函數 引用 CSV 文件config:
name: "testsuite google search"
base_url: ${ENV(base_url)}
testcases:
- name: call validate_title
testcase: testcases/validate_title.yml
parameters:
keyword: ${P(data/keyword.csv)}
來跑看看 data-in-csv.yml, keyword.csv 裡有三筆資料 YApi httprunner testcafe,
cd day29
hrun testsuites/data-in-csv.yml
測試報告可以看到,完成3 個測試案例,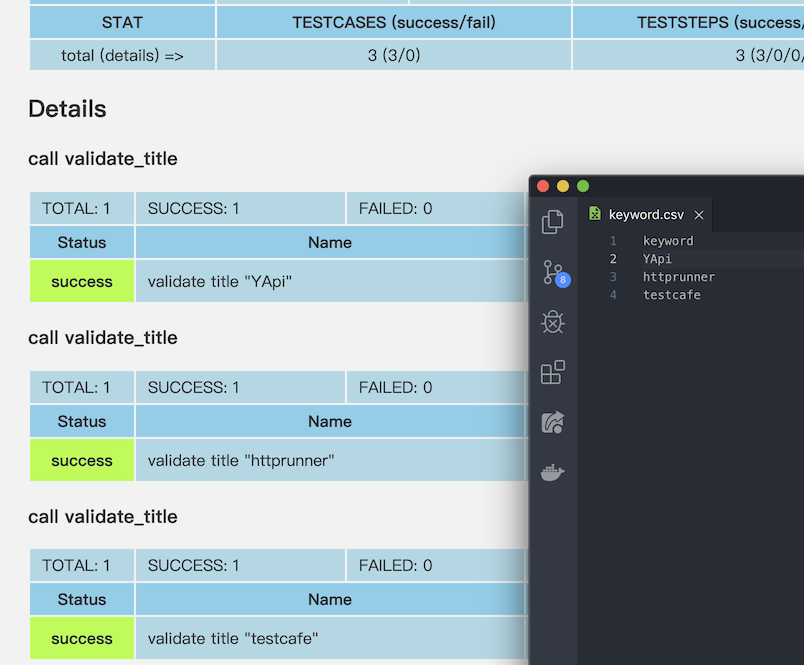
debugtalk.py 中自定義的函數,生成參數列表config:
name: "testsuite google search"
base_url: ${ENV(base_url)}
testcases:
- name: call validate_title
testcase: testcases/validate_title.yml
parameters:
keyword: ${get_keyword()}
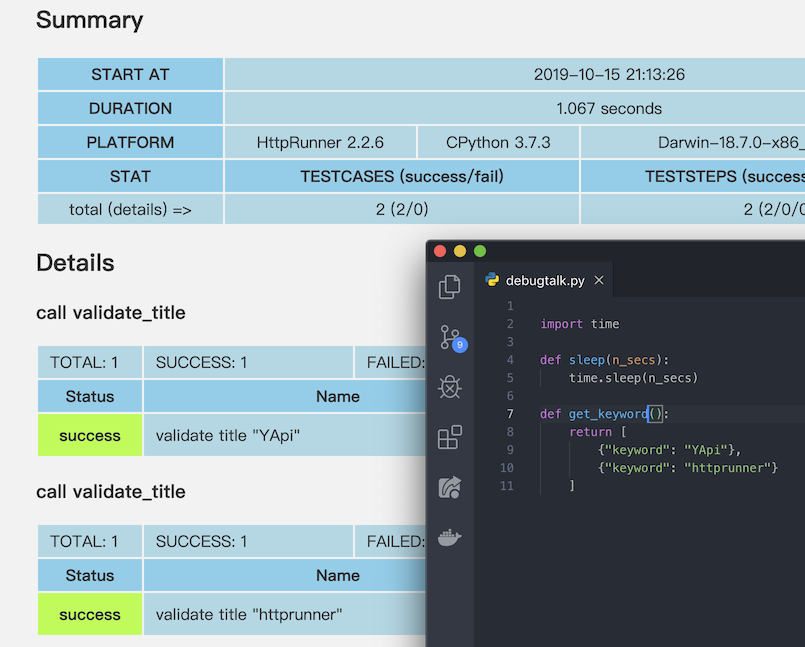
來跑看看 data-in-function.yml,debugtalk.py 裡定義了 get_keyword() 產生測試資料
def get_keyword():
return [
{"keyword": "YApi"},
{"keyword": "httprunner"}
]
cd day29
hrun testsuites/data-in-function.yml
測試報告可以看到,完成2 個測試案例,