上回提到了人工智慧就是指電腦具有智慧的表現,並且粗略的討論何謂有智慧的表現,「智慧」除了可以被具體表現量化的部分,像是多元智能理論提到的八種智能,還有部分現今仍無法明確定義的地方,討論最多的也就是所謂「自我意識」的概念,另外,我們電腦如何表現可以稱之為有智慧的表現也是需要討論的,所以今天要介紹人工智慧的分類與測試方式。
Can machines think?
-- Alan Turing, 1950
對於人工智慧,大家最爭論不休的就是機器能不能思考、會不會有「自主意識」,進而就會有像是「人工智慧要覆滅人類」之類的言論出現。在 1980 年時,美國加州柏克萊大學哲學家希爾勒(John R. Searle)便提出將人工智慧區分成「弱人工智慧」與「強人工智慧」兩種不同的主張。
弱人工智慧(Weak AI, Narrow AI, or Artificial Narrow Intelligence, ANI)
弱人工智慧只能模擬人類的思維與行為表現,但缺乏真正的推理與解決問題的能力,也不具有自主意識,並不具備人類的思考能力。它只專注於完成某個特定的任務,例如:圖像辨識、語言翻譯、玩圍棋遊戲等,只能用於解決特定問題,並沒有達到模擬人類思維的程度,不會有自主意識,所以弱人工智慧仍然屬於「工具」的範疇,與所謂的「產品」在本質上並無區別。
強人工智慧(Strong AI, General AI, or Artificial General Intelligence, AGI)
強人工智慧指電腦具有與人相同程度的智慧,在各方面都能和人類比肩。上面提到的各種能力像是學習能力、思考、語言表達、邏輯數學推理、抽象思維、創造等等,都可以和人類一樣,機器除了可以自我學習,並處理前所未見的細節,還能與人類相互交流學習,並具備「人格」的基本條件,或者說「自我意識」,可以像人一樣獨立思考與決策。
而我們要如何探討機器能否具備智慧存在著許多討論,接下來我們要先介紹兩個關於人工智慧的測試方法:圖林測試與中文房實驗。
如果一台機器能夠利用電傳設備與人類對話,而無法辨認是機器還是人,或是誤判機器是人,則這部機器便通過了圖林測試,可視為具有智慧。
在 1950 年,圖靈(Alan Turing)《計算機器與智能》(Computing Machinery and Intelligence )中提出「模仿遊戲」(The Imitation Game),也就是現在有名的圖靈測試來測試一部機器是否具有智慧,也是判斷機器是否具有智慧最為人熟知的方法。
假設有三個房間,有一個房間裡面坐著一個人,另一個房間有一部具有「人工智慧」的機器,而你坐在第三個房間,假設你能透過鍵盤、螢幕或甚至聲音與其他兩個房間溝通。你能隨意決定談話的時間、談話的內容並提出各種問題。但是記住另外一個房間的「人」會想盡辦法,讓你誤認他是一部「機器」;相反的來自另一個房間的「機器」想盡辦法,要你相信他是一個「人」,在經過適當的溝通與對話後,你必須決定剛剛談話的對象,那一個房間是人,那一個房間是機器。假如你無法辨認或誤判「機器」是人,則這部機器通過圖林測試而具有智慧。
到了1991 年,有位熱衷於人工智慧的洛布納(Hugh Loebner)博士,提供十萬美元給通過圖林測試的機器設計者,舉辦叫洛布納獎的圖林測試比賽,才開始有機器實際來挑戰圖林測試,但是,直到目前為止,還沒有任何一部機器通過圖林測試。目前的機器離這個境界還很遙遠,因此,洛布納獎每年只頒發一千五百美元獎金獎勵最接近人工智慧的機器。

(圖片來自:[2])
即使通過圖靈測試也不代表就有智慧,因為只有程式規則不能產生智慧,只有語言的文法不能產生語言意義。
在 1980 年,美國哲學家希爾勒(John R. Searle)發表一篇《心靈、大腦與程序》(Minds, Brains, and Programs)的文章,首次提出了著名的「中文房實驗」(Chinese room experiment)。
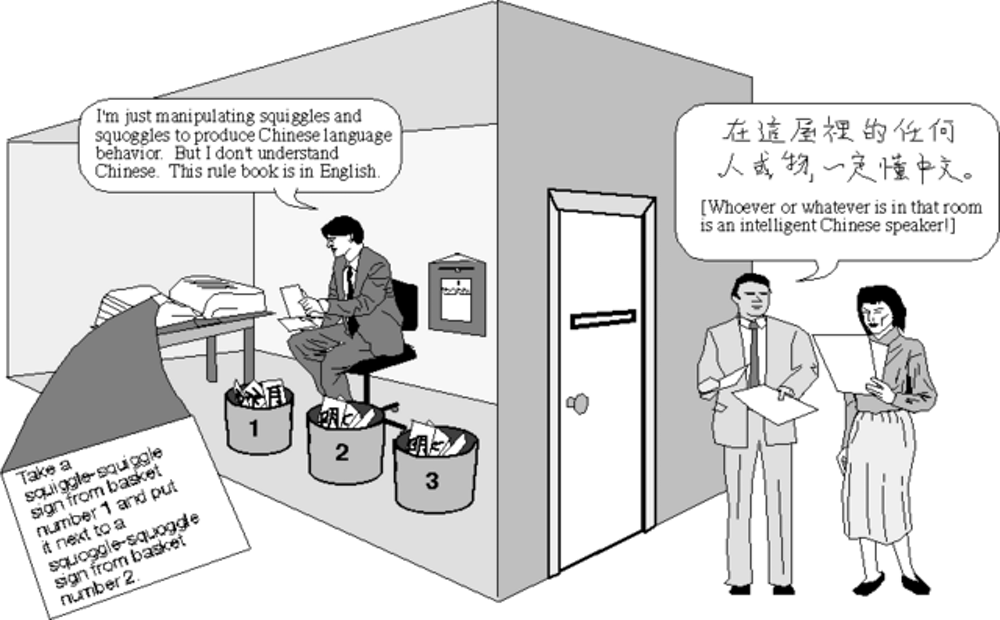
在這個實驗中,希爾勒設想一間裝滿了中文字卡的房間,房中還有一本由英文寫成的手冊和一個只懂英文而完全不懂中文的人,現在假設房外有人不斷以字卡的形式把一些中文寫成的問題透過一道窄縫送入房,中文房中的人則按照輸入的字卡和手冊指示,把一些對應的字卡順序從窄縫擲回房外。重要的是,手冊中的指示從來沒有解釋任何一個中文字的意義,指示的形式永遠只是「如果收到某某編號的字卡,則交回某某編號的字卡」或是「若收到某一組字卡,則交回另一組字卡」等。假設房外輸入的問題是一些有關唐詩的賞析或儒家哲學的討論,而由房中輸出的,則是相應這些問題的精闢答案,那麼房外的人必會認為房內的人不單通曉中文,而且對中國文化有深厚認識,可是房內的人不要說中國文化,就是連一個中文字也不認識!
中文字房就好比電腦,而房中的手冊則是電腦程式,假設這樣神奇的手冊真的存在,當我們有天能夠寫出這樣的電腦程式,那是否電腦就可以思考了呢?答案顯然不是!正如中文字房裡的人不懂中文,電腦對於問題也沒有任何的理解,永遠只會「語法」(syntax)而沒有「語義」(semantics),也就是只有語言的文法不能產生語言的意義(syntax doesn’t suffice for semantics),而這正是機器和人類的分別所在。
另外很顯然的,這中文房實驗中的這一部機器是通過了人工智慧的圖林測試,但是中文房的表現行為並沒有任何智慧存在, 所以通過圖林測試的機器,決不表示就有智慧或有意識。中文房實驗說明,如果機器僅僅是對數據進行轉換,而數據本身是對某些事情的一種編碼表現,那麼在不理解這一編碼和這實際事情之間的對應關係的前提下,機器不可能對其處理的數據有任何理解。基於這一論點,希爾勒認為即使有機器通過了圖林測試,也不能以此說明機器就真的如同人類一樣地具有思維和意識。
(圖片來自:[2])
除了弱人工智慧與強人工智慧,後來還有「超人工智慧」(Artificial Super Intelligence,ASI),指得是各方面都超越人類,而這些最根本的問題都回歸到「機器可以思考嗎?」,是否具備「自我意識」,這還是未來需要研究的方向,另外,如何驗證機器是否有智慧的測試也尚未定論,除了圖靈測試以及中文房驗證,其實後續還有許多的討論,像是皇帝的新心靈等,在此就先不談了。
[1] Strong AI 與 Weak AI
[2] 人類如何製造智慧?圖靈測試、中文房間論證,及人工智慧發展的三個難題
[3] 是人?還是機器?圖靈的模仿遊戲-《創新者們》

