哈囉大家好,我是橘白卯咪,歡迎大家來看看我能不能撐過30天
接下來就來到模型訓練的階段
評估辛苦跑了好久的模型,到底是個寶還是根草,通常會使用混淆矩陣來評估
嗯沒錯,它就叫這麼令人困惑的名字 confusion matrix
一張混淆矩陣的圖通常會長這樣
顏色越深的代表機率越高,通常好的模型,深色區塊都會左上-右下的連成一線
為什麼呢?來看看每個部分代表的意義
先簡單一點,假設今天動作只有兩類: dab跟other,你會得到的混淆矩陣大概會長這樣:
| dab | 0.9 | 0.1 |
|---|---|---|
| other | 0.1 | 0.9 |
| dab | other | |
| 為了方便解說,我給每一格一個代號 | ||
| dab | A | B |
| --- | --- | --- |
| other | C | D |
| dab | other | |
| 混淆矩陣的左邊所列的類別標籤,都是資料的真實標籤(true label) | ||
| 下方所列的標籤,是將資料輸入模型後,模型給出的預測結果(predict label) | ||
| 所以A格所代表的數字,就是實際上是dab,模型也預測是dab的機率 | ||
| 以此類推,故左上-右下方向的數值(A格、D格),都是實際標籤與模型預測結果一致的機率 | ||
| B格則是:實際上是dab,模型預測成other的機率 | ||
| 又因為資料丟進模型裡,它只能判斷成dab跟other兩類,所以任一列、任一行數值相加=1 | ||
| (A+B=1,A+C=1,C+D當然也=1~~) | ||
而我們所謂"好模型",就是預測準確的模型,就是給他看山就判斷成山、見水就知道是水的聰明模型小朋友
即為實際標籤與模型預測結果一致的機率高的模型
通常為了方便判讀,會將混淆矩陣裡的資料視覺化,機率越高給予越深的顏色,越低則越淺
讓好模型的混淆矩陣呈現左上右下連成一線的賓果連線,一眼就看出這個模型好棒棒
所以來練習一下吧,看一下這一張混淆矩陣圖,我們要怎麼解讀它呢?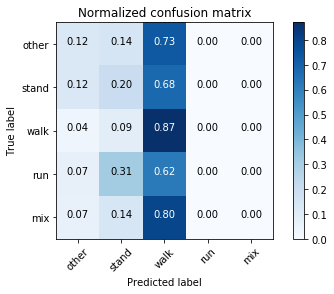
如果你已經理解混淆矩陣的意義,你應該會大聲的說
首先必須說,這個模型(或這張圖)怪怪的,任一行、任一列的數值加起來不為1
(真的怪怪的啦
從圖中可以看到這個模型被訓練了五個類別:other、stand、walk、run、mix
無論真實類別為何,都被判斷成了walk
通常在作圖的這段程式沒寫錯的狀況下,如果發生經常被判斷成某一類別的狀況
必須了解訓練樣本數是否有極大的偏差,例如walk的樣本數可能佔了7、8成
(嘛這很好理解,如果你知道答案通常是"以上皆是",那就多猜點"以上皆是"啦
或者是訓練資料不具代表性,做什麼都很像在走路
(這個資料集是邊走邊收集嗎??
再來更慘的,可能是訓練模型的人沒睡飽,資料放錯了
不過當你興緻高昂的捧著漂亮的混淆矩陣圖,去跟實驗室夥伴分享你訓練了一個好棒棒的模型,學長卻只回了你一句:
哪逆口咧(這是什麼),我需要的是數字!
明天,就讓我們來學習怎麼算、怎麼看模型準確度報告!
http://www.aihuau.com/a/25101016/296516.html
https://sparkydogx.github.io/2018/11/22/confusion-matrix-matplot/


