上一篇用R寫論文做到信度分析,後面就是效度分析,本想繼續寫下去但要講到KOM、球形、CFA、SEM等檢定方法,若是寫下去各位程度都沒問題一定都看得懂,但小弟必須將研究方法上下學期筆記拿起來在K一遍,消化完再用言簡意賅寫出來,心想天都亮了!再者,後面的效度分析以及建構因子,有在寫論文的人比較用得到,對於商業的應用比較少,比較多的是上一篇的信度分析及基本分析,經過幾番思量用R寫論文就到上一篇就告一段落,就像寫論文題目太大寫的人很辛苦,看的人也很累,因此本篇就以我母親的抱怨為題目吧!
本篇系列的資料集來自政府資料公開平台中,在搜尋欄位輸入農產品交易,會出現各縣市的農產品交易,但我們以農委會所產的資料為主。但近一個月的觀察農委會將每日交易行情在中午12點以前PO到資料公開平台,所以我就翻遍資料公開平台所有連結,就是要找到網址界接,並使用for迴圈撈一個月的資料,但怎麼都沒看到,所以採用每日單點下載,所以日期會跳日不過這不會影響我們的分析,資料下載點:https://drive.google.com/file/d/1dMXFMZ5WhfR03bWbNMmm0c0CxutoeJVH/view?usp=sharing
解壓縮後會看到一堆csv檔案,所以我們會用list.file()函式將資料夾內的csv檔案彙整為一個資料集,其時我個人很喜歡這個函式,因為在平常會有很多的檔案要做分析,稍做整理就能成為一個資料集,注意資料夾就只有本次的csv檔案不要參雜其他的csv檔案,程式碼如下
Agricultural <- list.files(path = "D:/工作區/我的筆記/程式筆記/R/Ironman Challenge/Agricultural",pattern="*.csv",full.names=TRUE) %>%
map_df(~read_csv(.))
str(Agricultural)
View(Agricultural)
看一下資料結構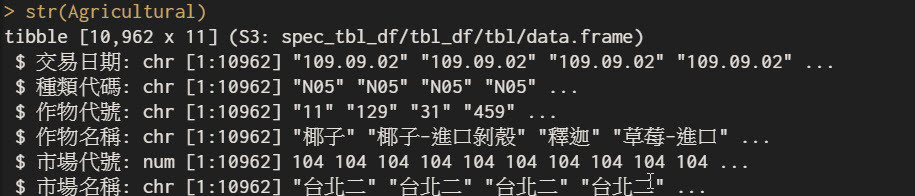
我們可以看到資料集為tibble為dataframe的延伸換言之式繼承了dateframe,所以使用起來很靈活,本次資料集為10962筆資料11個變數,但變數名稱為中文字,不過沒關係因為原始資料就是如此,若是正式的話還是建議將變數名稱改為英文,接著瀏覽一下資料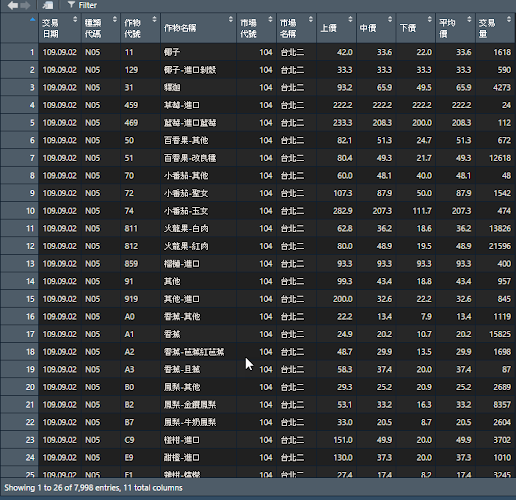
看完資料不得要稱讚一下農委會資料很乾淨,當然啦!若是你用execl開不會如此的井然有序,所以本次的資料集不須進行整理,但該如何分析?....首先我們可以看到光9/2號就有很多的交易為其一,其二市場名稱有多少個市場?是全台灣嗎?其三每個做物名稱都有上、中、下、平均、交易等。
首先我就看總共有多少日的交易,以及多少個市場,全日的總交易及總評均價,先從此部分做個探索
AgriculturalTrans <- Agricultural %>%
group_by(交易日期,市場名稱) %>%
summarise(TotalTransaction = sum(交易量),
TotalMeanPrices = sum(平均價)) %>%
ungroup()
View(AgriculturalTrans)
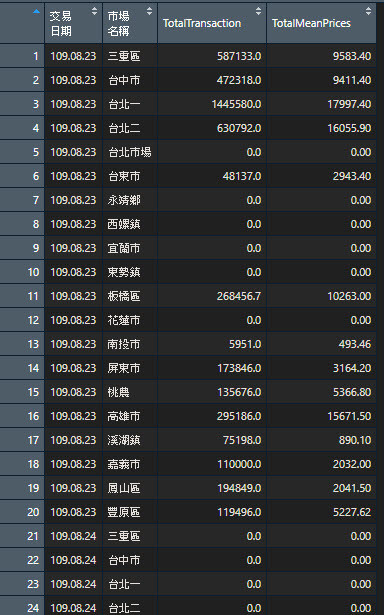
看起來市場為全台灣,而全台灣最近的市場,當天每交易金額為0,劃一下統計圖程式如下
options(scipen = 200)
ggplot(data = AgriculturalTrans)+
geom_bar(aes(x=交易日期,y=TotalTransaction,fill=市場名稱),
stat="identity")
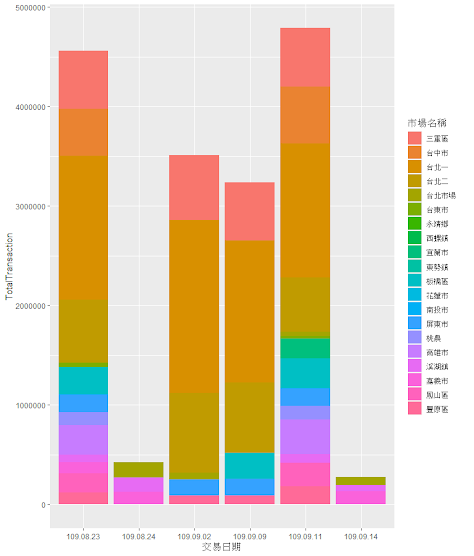
所以交易日共計六天,其中9/11交易量最高次之為8/23日,從市場來看台北一、台北二、三重,為全國交易量最多,次之為台中市,相對南部的市場交易並不是很多。
在上述程式中 options(scipen = 200)主要功能為呈現正確數字,而不是用科學數字呈現,各位可試一下。
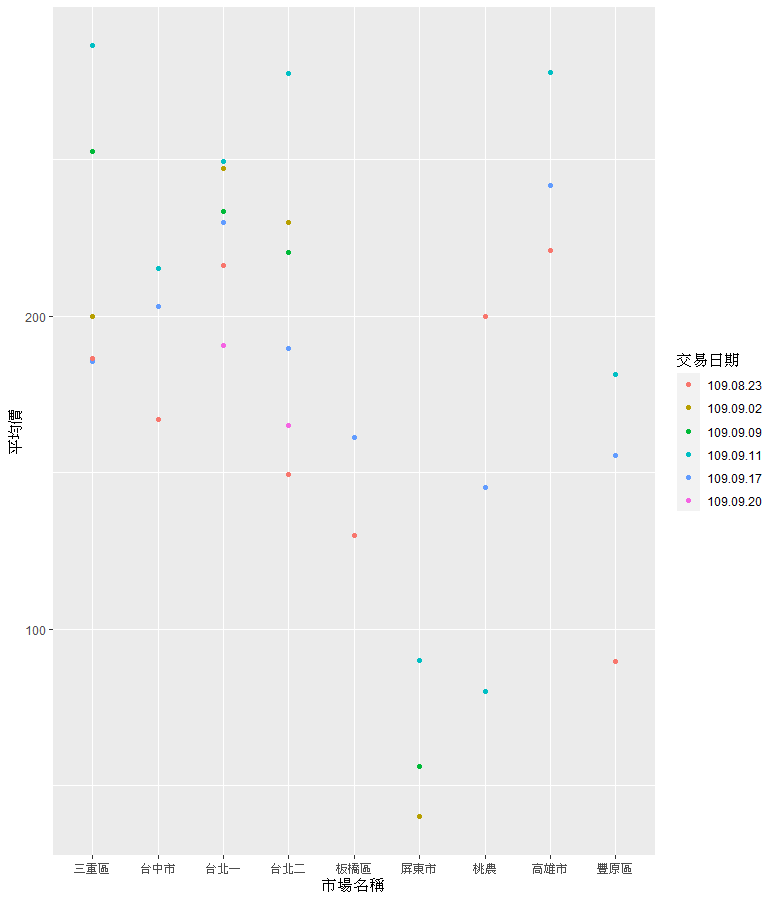
最後看一下最近很紅的蒜頭每個市場的平均價錢,在程式中我使用grep()函式以文字的方式做搜尋在將搜尋完成的行加入一個新的變數(稍微較麻煩),但也可使用作物代號使用filter()派何pipleline語法較為簡單
A <- grep("蒜頭",Agricultural$作物名稱)
View(A)
Garlic <- Agricultural[A,]
View(Garlic)
ggplot(Garlic, aes(x = 市場名稱, y = 平均價)) +
geom_point(mapping = aes(color = 交易日期))