沒想到我成功撐過第一週,還有三週半繼續努力!
歡迎來到第八天,承接昨天,今天將要結合 Line API 完成整個推播功能。由於筆者使用的是 Python 作為主要的開發環境,Line 官方也有推出 Python 專用的 SDK 可以為整個開發流程省下不少時間,由於此系列文章並非在探討 Line Chat Bot 的技術,因此不會贅述 Line SDK 與 Flask 相關的程式碼。若想了解更多 Line Chat Bot、Flask 與 Deploy 的相關內容,請參考 ChatBot&Chatbase 系列。
從 Python 專用的 SDK 的 GitHub 中可以複製該範例程式碼,並首先透過 print(event.source.sender_id) 方式取得自己的 Line ID,以便在後續的 message push 功能進行推播。
@handler.add(MessageEvent, message=TextMessage)
def handle_message(event):
print(event.source.sender_id)
line_bot_api.reply_message(
event.reply_token,
TextSendMessage(text=event.message.text))
在更改範例程式碼後,你會發在終端機當中觀察到自己的 Line ID,例如下方,

接下來,Line 只是一個用來接收資訊的媒介,我們並不需要像聊天機器人那樣的回覆訊息,因此在拿到 User ID 後,就不再需要 Flask 等程式碼,只需要專注在 Line API 的串接及 push_message() 的運用,我們將昨天的爬蟲程式做結合,編寫一個新的函數 push_message()。
def push_message():
target_url = "https://ithelp.ithome.com.tw/questions"
today = datetime.date.today()
target_date = today.replace(day=today.day-2)
last_page = page_numbers(target_url)
articles = {}
for page in range(last_page):
response = requests.get(target_url,params = {'page':page+1})
html = etree.HTML(response.text)
articles = {**articles,**get_title_url(html,target_date)}
last_question_date = html.xpath("//div[@class='qa-list__info']/a[1]")[-1].text
if datetime.datetime.strptime(last_question_date,"%Y-%m-%d").date() < target_date:
break
if articles:
message ="今天的問題如下:\n"
for key in articles.keys():
message = f"{message}{key}\n{articles[key]}\n"
else:
message = "今天沒有符合條件的新問題"
line_bot_api.push_message("Your Line ID", TextSendMessage(text=message))
這樣就完成爬蟲程式與 Line Chat Bot 的結合,接下來只要將程式部署到伺服器上利用排程的功能,就可以每天收到最新的問題拉!請參照以下完整程式碼:
from time import sleep
import datetime
import requests
from lxml import etree
from linebot import (
LineBotApi, WebhookHandler
)
from linebot.models import TextSendMessage
line_bot_api = LineBotApi('YOUR_CHANNEL_ACCESS_TOKEN')
def push_message():
target_url = "https://ithelp.ithome.com.tw/questions"
today = datetime.date.today()
target_date = today.replace(day=today.day-1)
last_page = page_numbers(target_url)
articles = {}
for page in range(last_page):
response = requests.get(target_url,params = {'page':page+1})
html = etree.HTML(response.text)
articles = {**articles,**get_title_url(html,target_date)}
last_question_date = html.xpath("//div[@class='qa-list__info']/a[1]")[-1].text
if datetime.datetime.strptime(last_question_date,"%Y-%m-%d").date() < target_date:
break
if articles:
message ="今天的問題如下:\n"
for key in articles.keys():
message = f"{message}{key}\n{articles[key]}\n"
else:
message = "今天沒有符合條件的新問題"
line_bot_api.push_message("Your Line ID", TextSendMessage(text=message))
def page_numbers(url):
response = requests.get(url)
html = etree.HTML(response.text)
next_tag = html.xpath("//a[@rel='next']")[0] # 定位出下一頁
final_page = next_tag.getparent().getprevious().find('a').text # 下一頁按鈕的前一個按鈕及為最後一頁的數字
return int(final_page)
def get_title_url(html,target_date):
element_list = html.xpath("//div[@class = 'qa-list']")
answered_tag = "qa-condition qa-condition--has-answer qa-condition--had-answer " # 已有最佳解答
target_date = target_date.strftime("%Y-%m-%d")
articles = {}
for element in element_list:
tags = [t.text for t in element.findall("./div[@class = 'qa-list__content']/div[@class='qa-list__tags']/a")] # 列出所有 Tag
time = element.find("./div[@class = 'qa-list__content']/div[@class='qa-list__info']/a[1]").text # 定位出時間
answer_status = element.find("./div[@class = 'qa-list__condition']/a[2]").get('class') # 找出回答標籤的 class 內容
if answer_status != answered_tag and "python" in tags and time == target_date: # 若三個條件皆符合,則收入為目標問題
articles[element.find("./div[@class = 'qa-list__content']/h3/a").text] = element.find("./div[@class = 'qa-list__content']/h3/a").get("href")
return articles
if __name__ == "__main__":
push_message()
一旦排程被啟動,就會收到像下方的訊息,

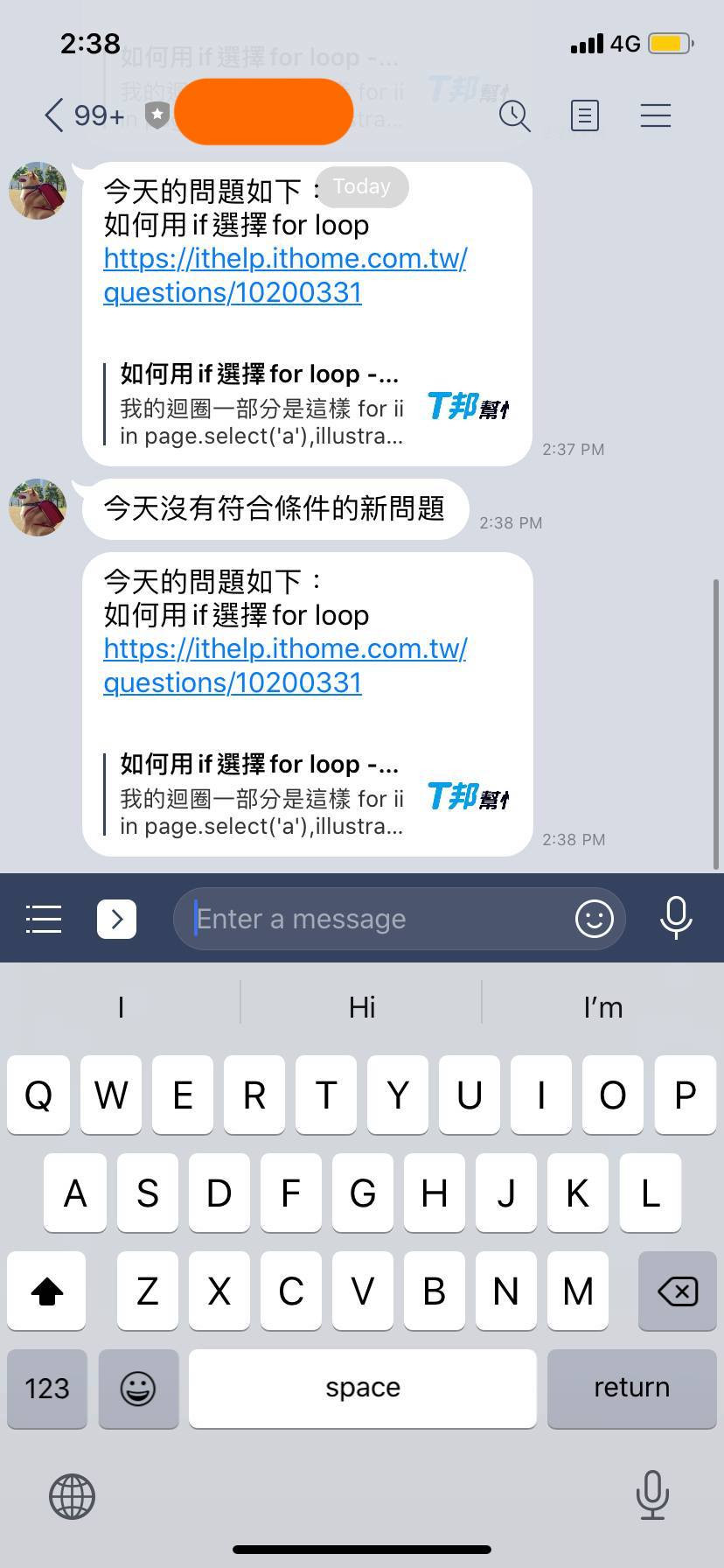
這樣就完成拉!明天開始就要進入動態網站爬蟲的部分,明天見!


 iThome鐵人賽
iThome鐵人賽