



Precision和Recall同時關注的都是True Positive(都在分子),但是角度不一樣,Precision看的是在預測正向的情形下,實際的「精準度」是多少,而Recall則是看在實際情形為正向的狀況下,預測「能召回多少」實際正向的答案。一樣的,如果是門禁系統,我們希望Precision可以很高,Recall就相較比較不重要,我們比較在意的是預測正向(開門)的答對多少,比較不在意實際正向(是主人)的答對多少。如果是廣告投放,則Recall很重要,Precision就顯得沒這麼重要了,因為此時我們比較在意的是實際正向(是潛在客戶)的答對多少,而相對比較不在意預測正向(廣告投出)答對多少。
Precision和Recall都不去考慮True Negative,因為通常True Negative會是答對的Null Hypothesis,簡單講就是最無聊的正確結果。在門禁的解鎖問題就是陌生人按壓且門不開;在廣告投放的例子中就是廣告不投,結果那個人也不是潛在客戶:在信用卡盜刷的例子,機器人認為正常的刷卡紀錄,其實也正是正常的。在通常的命題之下,實際是正向的結果是比負向少的,理所當然預測正向的結果也要比負向少,所以True Negative通常是量最多的,也是最無聊的。
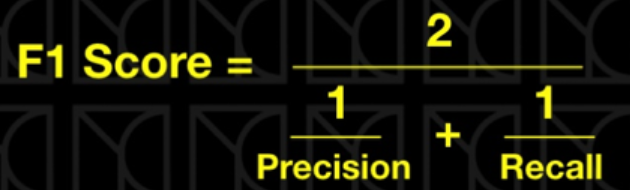
以上三種是基本常用的評估指標,可依照不同情境來決定要以哪個指標為主要的模型評估指標。那假設今天的情境是想同時考慮「precision」和「recall」(「accuracy」因有使用上的限制,暫且不考慮)的話,這時就可以考慮改用「F1-score」。
補充說明:
在F1-score中,會選用「調和平均數」而非「算數平均數」作為平均「precision」和「recall」的方式,是為了要強調較小值的重要性。
會這麼說是因為該二指標是互相制約的—不會有兩個指標同時很高或很低的狀況發生,這樣可以更加方便評價模型的好壞,以下範例說明何謂「強調較小值的重要性」:
當recall接近1、precision接近0
採用「調和平均數」的F1-score接近0 ➜ 等效於評價precision和recall的整體效果(代表模型的效果還有很大很大的進步空間)
採用「算數平均數」的F1-score為0.5左右
醫學上常用的指標,如果以人口當作所有的樣本,實際得病的患者所佔的比例就代表這個病的盛行情況。
如果今天有一個診斷方法可以判定病人是否有得此病,有兩個指標可以看,那就是Sensitivity和Specificity,Sensitivity就是Recall,它代表的是診斷方法是否夠靈敏可以將真正得病的人診斷出來,其實就是真正有病症的患者有多少可以被偵測出來,而Specificity則代表實際沒病症的人有多少被檢驗正確的。兩種指標都是越高越好。
通常在醫學上,會通過一些閥值來斷定病人是否有得此病,而這個閥值就會影響Sensitivity和Specificity,這個不同閥值Sensitivity和Specificity的分布情況可以畫成ROC Curve,而ROC Curve底下的面積稱為AUC,AUC越大越好。
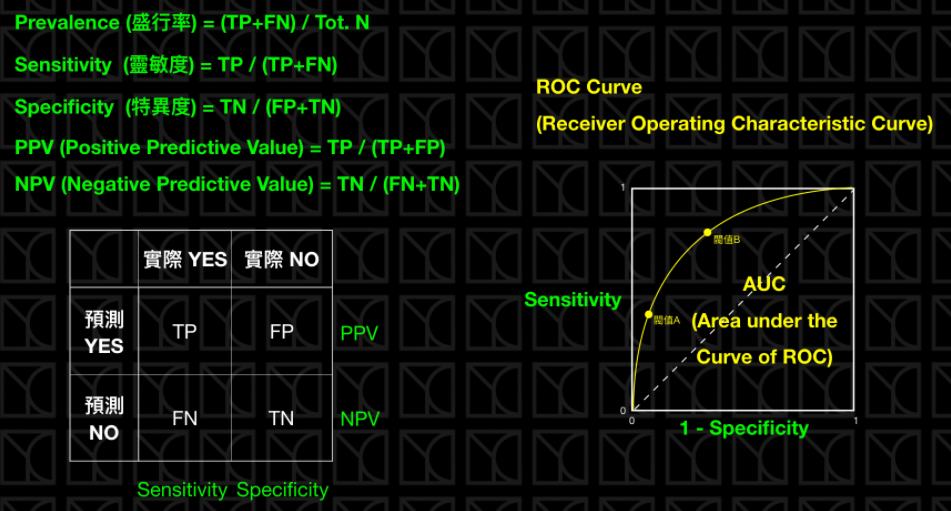
如何辨別機器學習模型的好壞?秒懂Confusion Matrix

