1982 年在由大衛.赫索霍夫主演的電視影集《霹靂遊俠》裡,能自動駕駛又會說話的汽車讓人藉由好萊塢的影集瞭解什麼是影像及語言辨識技術。李麥克那輛稱為「夥計」(KITT)的人工智慧車,將以搭配卷積神經網路(CNN)和循環神經網路(RNN)的深度學習技術來觀察四周車況、聽聲及說話。
原因在於機器現在使用 CNN 來消化處理影像,以辨識不同物體,其相當於眼睛的角色;而 RNN 是數學計算引擎,用以解析各種語言模式,相當於耳朵和嘴巴的角色。
若拿掉那輛時髦感十足、又會自動駕駛的黑色龐蒂克火鳥跑車上的 RNN,那個聰明的電腦語音就不會再揶揄李麥克這個單身漢,更不用說也無法用法文和西班牙文來操控夥計。
毫無疑問的是,RNN 加快了語音方面運算革命的發展腳步。RNN 是處理自然語言的大腦,讓 Amazon 的 Alexa、Google 的 Assistant 及 Apple 的 Siri 擁有耳朵和嘴巴,可以聽取和發出語音;也為 Google 的自動填入功能提供未卜先知般的能力,當你在搜尋時它會自動填入字句。
RNN:從通俗到深入(1)
RNN,也即是循環神經網絡,RNN是為了對序列數據進行建模而產生的。其中文本是字母和詞彙的序列;語音是音節的序列;視頻是圖像的序列;氣象觀測數據、股票交易數據等等,也都是序列數據。
註: 序列數據意指連續型資料且前後有關連,例如
Because I am hungry , I want to eat an apple.
Because I am thirsty , I want to drink water.
RNN背後的核心理念是利用序列的信息。傳統的神經網絡常常假設輸入(輸出)是獨立於彼此的,這對於某些應用來說是不可行的。RNN之中的recurrent就是循環往復的意思,網絡對於序列數據的每個元素進行同樣的操作,網絡的輸出取決於之前的計算。以下是RNN的典型結構:
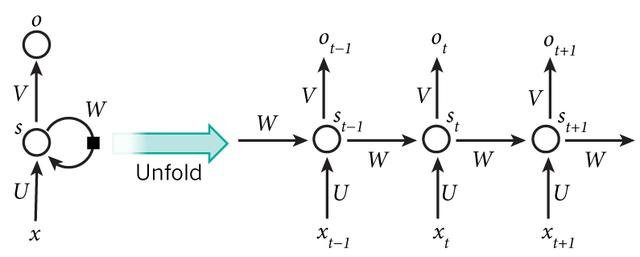
可見:(t+1)時刻網絡的最終結果O(t+1)是該時刻輸入和所有歷史共同作用的結果。以上的結構將RNN展開成完整的網絡。例如,我們需要處理一個5層的序列,那麼就需要展開成5層:每層對應一個詞。
x指的是某一時刻網絡的輸入;
s是隱藏狀態,代表著網絡的「記憶」;
o代表輸出。
對於以上有幾點需要提示:
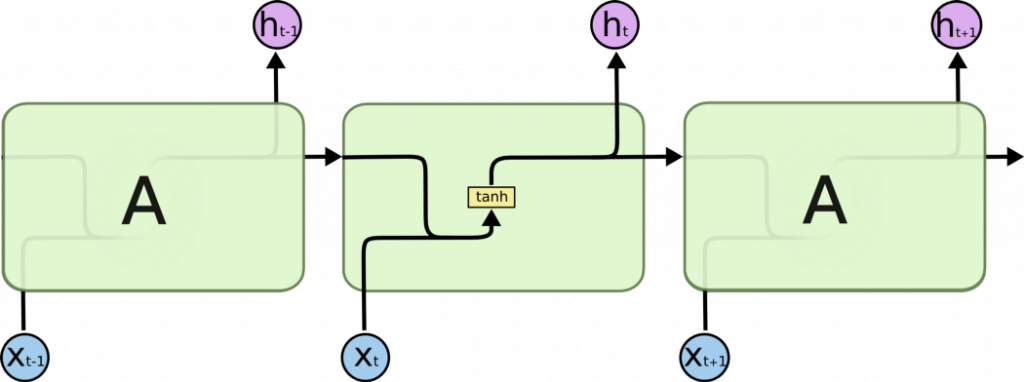
我們可以把隱藏狀態s看成是網絡的「記憶」,其捕捉到在之前所有時間的信息。輸出o只取決於在當前時刻的記憶,而在實際上由於長期依賴問題,s很難捕捉到很長時間以前的信息。
RNN每個step中的參數(U, V, W)是相同的,這使得學習的代價減小許多。
取決於實際任務,我們不一定需要每個step都有輸入和輸出。
若再加一層由後向前推估的模型,兩者綜合,即為雙向, 因為『要考慮前言後語,以免斷章取義』,而RNN只考慮前面的資料,沒有考慮後面的資料。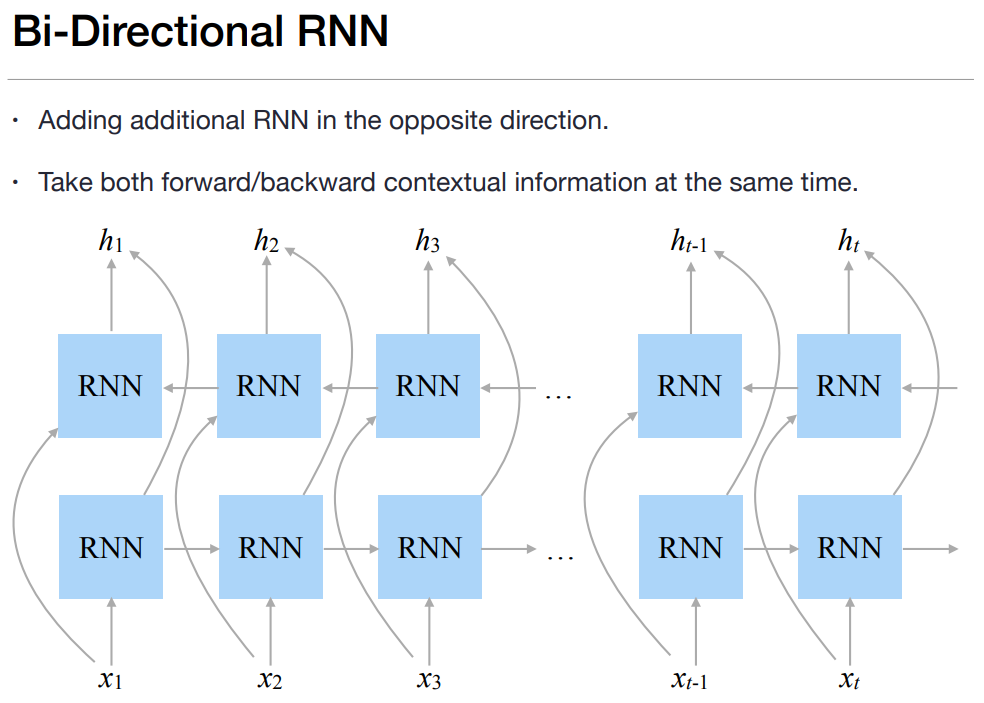
遞歸神經網路 (RNN) 不論是在研究或是實務上的應用,在解決一些問題例如語音轉文字或是翻譯上,都已經展現出相當好的效果。然而,卻沒有任何好的效果是透過簡單的 RNN 模型 (vanilla RNN) 所達成的,決大部分都會再改良其中的循環神經單元,其中最有名的,就是LSTM。
遞歸神經網絡是一種深度神經網絡,它是通過對結構化輸入遞歸地應用同一組權重,以通過遍歷給定的結構來生成對大小可變的輸入結構的結構化預測或對其的標量預測的方法。再透過拓撲順序呈現。遞歸神經網絡(有時縮寫為RvNN)已經取得了成功,例如,在自然語言處理的學習序列和樹結構中,主要是基於詞嵌入的短語和句子連續表示。
recurrent: (Elman, 1990) 時間維度的展開,代表信息在時間維度從前往後的的傳遞和積累,可以類比markov假設,後面的信息的概率建立在前面信息的基礎上,在神經網絡結構上表現為後面的神經網絡的隱藏層的輸入是前面的神經網絡的隱藏層的輸出。
recursive: (Goller & Küchler, 1996) 空間維度的展開,是一個樹結構,比如nlp裡某句話,用recurrent neural network來建模的話就是假設句子後面的詞的信息和前面的詞有關,而用recurxive neural network來建模的話,就是假設句子是一個樹狀結構,由幾個部分(主語,謂語,賓語)組成,而每個部分又可以在分成幾個小部分,即某一部分的信息由它的子樹的信息組合而來,換句話說,整句話的信息由組成這句話的幾個部分組合而來。
作者:理查德帕克 链接
Recurrent networks (Elman, 1990) are designed to model sequences, while recursive networks (Goller & Küchler, 1996) are generalizations of recurrent networks that can handle trees. ---Yoav Goldberg 《Oct. 2015 , page 4, A Primer on Neural Network Models for Natural Language Processing》

