數據集的使用,常常令人一頭霧水,舉例來說,iris dataset這個最常用的資料集。
用一行代碼就可以把資料集放進來了
iris = datasets.load_iris()
可是它到底長什麼樣子?
官方說明 給道指令 iris.DESCR() 就會列出一堆文字說明。
不過還是一頭霧水,看不到真面目。
原來,iris.csv是安裝完sklean之後,就放在你的資料夾裡的東西。
在安裝Anaconda3位置下x32 x64不同\lib\site-packages\sklean\datasets\data內
Iris.csv 打開來看,長這樣: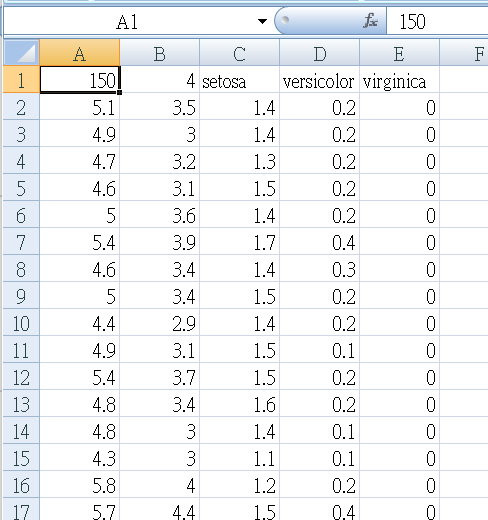
疑…欄位名稱怪怪的,原來第一列不是欄位名稱。
它意思是說有150筆資料,前4個欄位是特徵,
第五欄是結果target (三個數字代表三種品種:setosa、versicolor、virginica)。
我們把它改成看得懂的方式: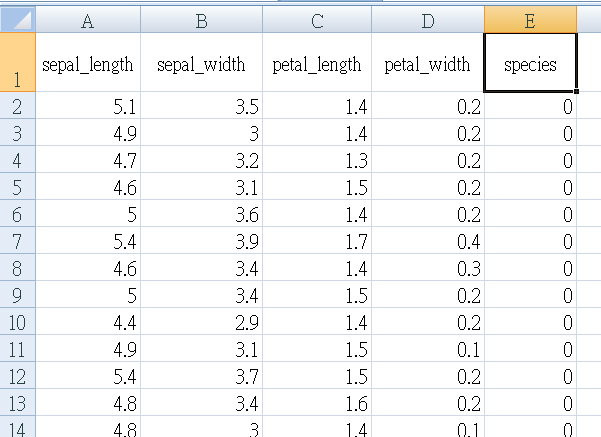
那麼,該如何讀取這個csv ?
我們把sklearn官網範例 K-means clustering 略做修改,讀取我們的irisC.csv ,其它的碼不變。
原先範例之讀取方式:
iris = datasets.load_iris()
X = iris.data # 大X 是四項特徵
y = iris.target # 小y 是target
iris = datasets.load_iris()
X = iris.data
y = iris.target
我們的讀取方式:
#--- modified part
#--- 讀取自定的 irisC.csv
iris = np.genfromtxt("irisC.csv",delimiter=',',dtype=np.float64)
r,c = iris.shape
print(f'row: {r} columns: {c}') # row 0 is header
X = iris[1:,0:4] # X.dtype float64
#print(X[0,:]) # X 0~3 column contents
y = iris[1:,4]
y = np.array(y,dtype= np.int32)
print(f'target type : {y[:].dtype}') # y.dtype int32
#--- 載入欄位名稱 ------
#--- 問題是 np 已設定為 dtype float64 ,所以header讀出來是 nan 無法使用
#--- 所以重新再讀一次,使用 Unicode string type 'U'
#--- 此處只是讀出欄位名稱,並未使用它
irisH = np.genfromtxt('irisC.csv',delimiter=',',dtype='U')
fld = []
# 首列是欄位名稱
for n in range(0,5):
fld.append(irisH[0,n])
print('欄位名稱 :',fld)
#-------------------------------------
雖然,碼長了點,不過可以自主處理自定的csv檔,也不錯。
其它的範例代碼不動它。
我們修改後的 Source Code + irisC.csv在此
 neocaffe
neocaffe
