我們的挑戰終於進行一半啦~前面經過漫長的資料前處理、特徵工程、挑選模型進行訓練後,我們把一個機器學習的模型建立出來了,接著我們要進行測試,也就是把測試檔丟入模型裡進行預測,那怎麼樣的結果會符合我們的期待呢?我們又要以什麼方法去評估這個結果呢?將會在今天來做介紹,那就廢話不多說,累狗 ~
一般我們在回歸問題上預測出來的結果會是數值,而預測值與實際值的差,就是"誤差",回歸問題用以評估的方法有以下幾點:
所有誤差的平方和取平均,越小代表越準確。
因為對誤差取平方,較容易看出離群的預測值,此評估方式較在乎誤差的大小。
所有誤差取絕對值後取平均,越小代表越準確。
求的是誤差離實際值的真實距離,較難看出離群值。
程式碼也非常簡單,利用Sklearn套件就可以輕鬆實現。
#MSE
from sklearn.metrics import mean_squared_error
y_true = [3, -0.5, 2, 7] #真實值
y_pred = [2.5, 0.0, 2, 8] #預測值
mean_squared_error(y_true, y_pred)
#MAE
from sklearn.metrics import mean_absolute_error
y_true = [3, -0.5, 2, 7] #真實值
y_pred = [2.5, 0.0, 2, 8] #預測值
mean_absolute_error(y_true, y_pred)
最常被用來評估分類問題的指標就是混淆矩陣,他簡單易懂,可解釋力高,我們以好壞分類作為示範,混淆矩陣示意圖如下:
(備註:矩陣會隨預測的標籤數增加,若標籤為n個,矩陣大小就為n*n)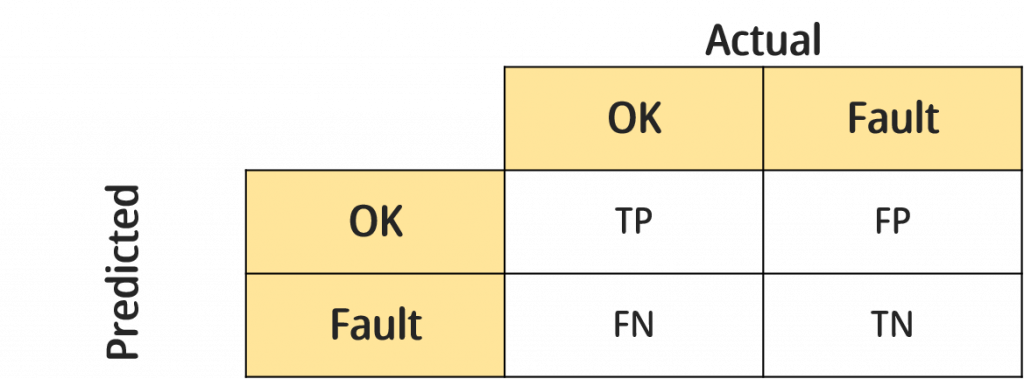
▲True Positive(TP):實際狀態為OK且預測狀態也為OK。
▲False Positive(FP):實際狀態為Fault但預測狀態為OK。
▲False Negative(FN):實際狀態為OK但預測狀態為Fault。
▲True Negative(TN):實際狀態為Fault且預測狀態為Fault。
由上可知,TP與TN是最好的,因為都屬於預測正確,而FP與FN都屬於預測錯誤,但有些許的不同。以下我們用產品的品質管理來舉例:
False Positive(FP)又稱偽陽性,明明產品是壞掉的,我們卻沒有檢驗出來,反而說它是好的,這在統計學的假設檢定中又稱為型一錯誤,品管中我們稱之為消費者風險(因為消費者會拿到壞的產品)。
False Negative(FN)又稱偽陰性,產品是正常的,我們卻說他是壞的,統計學的假設檢定中稱為型二錯誤,品管中稱為生產者風險(因為把好的產品挑出來浪費掉了)。
在品管或生管我們會比較看重型一錯誤,畢竟你產品自己浪費了沒關係,但如果送到消費者的手中就會影響產品的品質問題,這就是寧可錯殺,不願放過的概念,我們也可以用混淆矩陣來修正這幾個指標。
Accuracy:最單純的準確率,預測正確的比例。
計算方式:(TP+TN) / (TP+FP+TN+FN)
Precision:所有負樣本中,成功預測出負樣本的比例。
計算方式:TP / (TP+FP)
Recall:所有正樣本當中,成功預測出正樣本的比例。
計算方式:TP / (TP+FN)
F1-score:Recall以及Precision的調和公式
計算方式:2 * recall * precision / (recall+precision)
我們一樣使用Sklearn的套件來實作
from sklearn.metrics import confusion_matrix
y_true = [0, 0, 1, 1, 0, 1] #真實值
y_pred = [0, 1, 0, 0, 0, 1] #預測值
confusion_matrix(y_true, y_pred)
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
y_true = [0, 0, 1, 1, 0, 1] #真實值
y_pred = [0, 1, 0, 0, 0, 1] #預測值
# Accuracy
accuracy=accuracy_score(y_true,y_pred)
# Precision
precision=precision_score(y_true,y_pred)
# recall_score
recall=recall_score(y_true,y_pred)
# f1_score
f1_score=f1_score(y_true,y_pred)
今天介紹了一些評估模型的指標,到了這個步驟也代表整個資料分析的流程都Run過一遍了,明天開始會完整的呈現一個在Aidea上的專案,從頭帶大家複習一遍利用機器學習來做資料分析的過程,如果前幾個步驟的說明不夠詳細或是沒有實作的感覺,也歡迎試著一起來挑戰明天的專案喔~希望對大家有所幫助,再會啦!

