前面學了這麼多的方法,大家是不是在煩惱要怎麼使用?或是不知道該用在什麼地方?今天就由小編來帶大家進行專案實戰,讓大家輕鬆上手。
這次我們所用的資料是從Aidea平台上取得的,來到首頁後可以看到上面有練習場,直接點進去找“員工離職預測”就可以報名。在練習場的資料原本都是用來比賽的,在比完賽後主辦方會放在上面供大家練習。因為是比賽的資料,所以資料集都稍微有點難度,不過也因為是跟業界合作,拿到的資料都是真實資料~大家有興趣也可以下載其他議題的資料來做,那我們就開始吧!

通常比賽方會附上資料說明,告訴我們題目的目標是要做什麼,也會給出每個欄位的說明,要記得先讀懂,不然會不知道怎麼開始。
以這個資料為例,他要我們找到哪些員工未來可能離職,而我們就要根據他的資料去預測0(未離職)或1(離職),很顯然的這是個分類問題。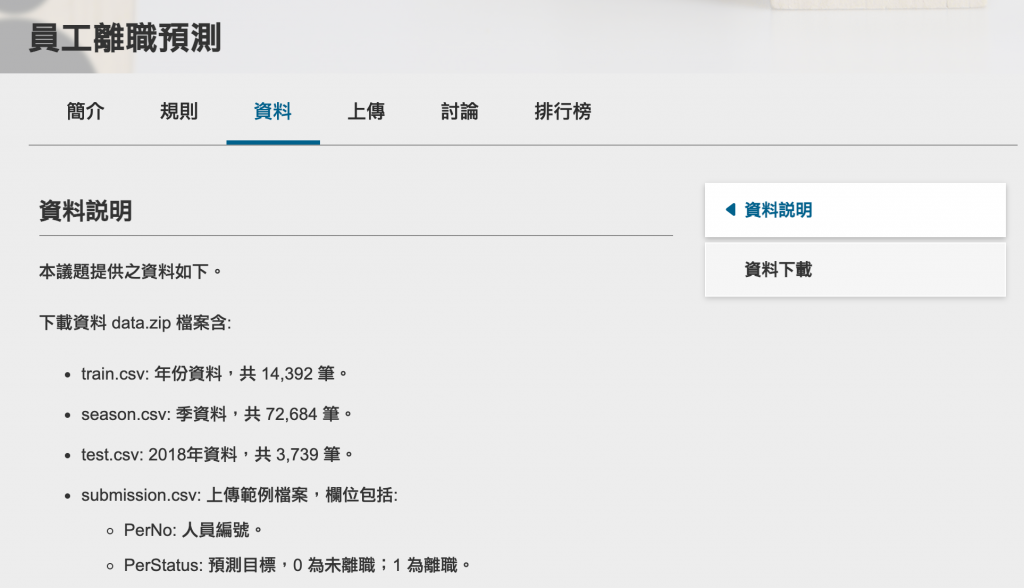
因為特徵數量太多,我只列出部分幾個:
df_train.isnull().sum()
年度績效等級B 73
年度績效等級C 73
年齡層級 73
婚姻狀況 73
年資層級A 73
年資層級B 73
年資層級C 73
任職前工作平均年數 73
最高學歷 5326
畢業學校類別 3841
畢業科系類別 73
眷屬量 73
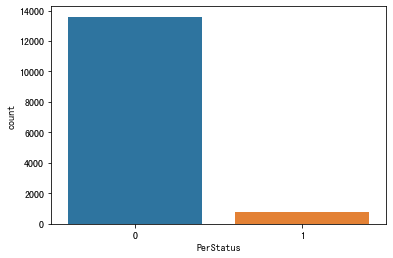
可以發現這是資料不平衡的資料集
ax = sns.countplot(x="PerStatus", data=df_train)
可以看到有些特徵在某部分離職率很高,例如我們可以看到廠區代碼,待在廠區六的離職率相對高很多,所以我們到時候特徵篩選的時候可以把這些納入考慮。
但在這裡我要跟讀者說抱歉,因為這是使用R語言畫的,所以這部分沒有提供程式碼,大家可以利用前面所學的試著去做視覺化,來訓練自身的畫圖能力喔~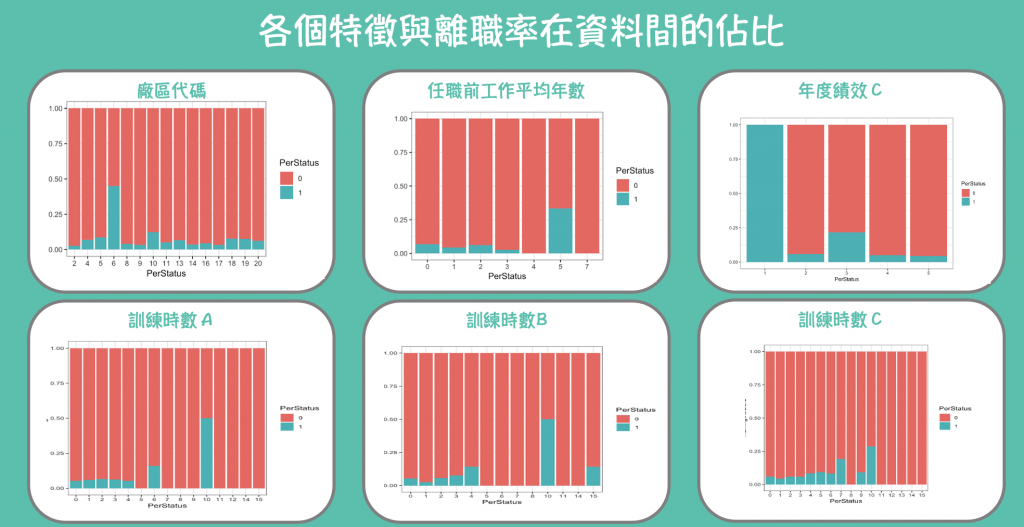
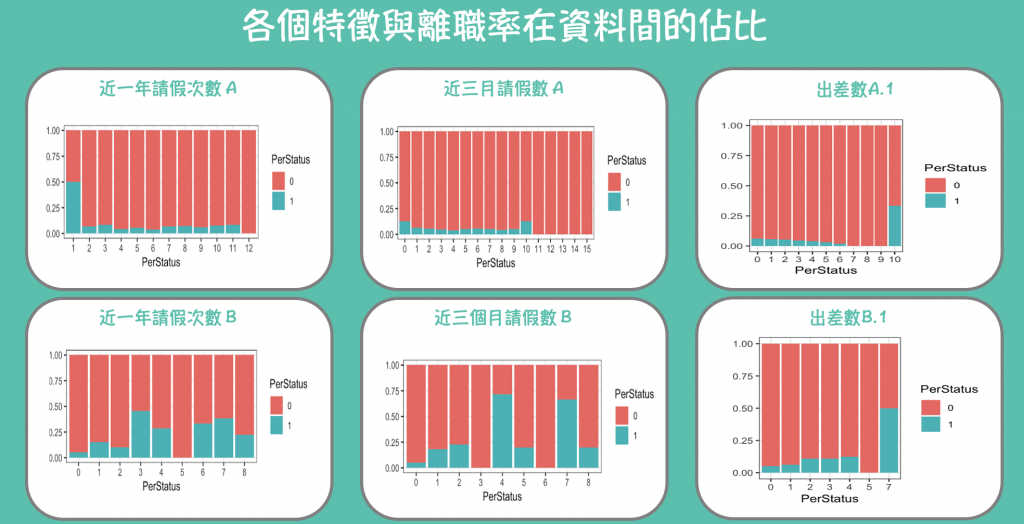
因為資料因為資料給的是同一個人四年的資料,因此我們用有離職的人當年減上一年去看看是什麼特徵出現變化導致他們離職。
結果我們發現有五個特徵的變化導致離職的比率比沒變化高。分別是:訓練時數c、生產總額、近三個月請假數A、近一年請假數A、年度績效等級c ,到時候我們在做特徵篩選時就可以把這五個特徵丟進去看看,看有沒有比較重要。
#畫出堆疊長條圖
data0=[]
data1=[]
data11=[]
for i in range(1,22):
data0.append((train[train.columns[i]]==0).sum())
data1.append((train[train.columns[i]]==1).sum())
data11.append((train[train.columns[i]]==-1).sum())
#%%
import numpy as np
import matplotlib.pyplot as plt
year=['專案時數變化', '專案總數變化', '特殊專案佔比變化', '訓練時數A變化', '訓練時數B變化',
'訓練時數C變化', '生產總額變化', '榮譽數變化', '是否升遷變化', '升遷速度變化', '近三月請假數A變化',
'近一年請假數A變化', '近三月請假數B變化', '近一年請假數B變化', '出差數A變化', '出差數B變化', '出差集中度變化',
'年度績效等級A變化', '年度績效等級B變化', '年度績效等級C變化', '加班數變化']
plt.figure(figsize=(9,7))
plt.bar(year,data0,color="green",label="沒變化")
plt.bar(year,data1,color="yellow",bottom=np.array(data0),label="變化增加導致離職")
plt.bar(year,data11,color="red",bottom=np.array(data0)+np.array(data1),label="變化減少導致離職")
plt.legend(loc="lower left",bbox_to_anchor=(0.8,1.0))
plt.xticks(rotation=30)
plt.show()
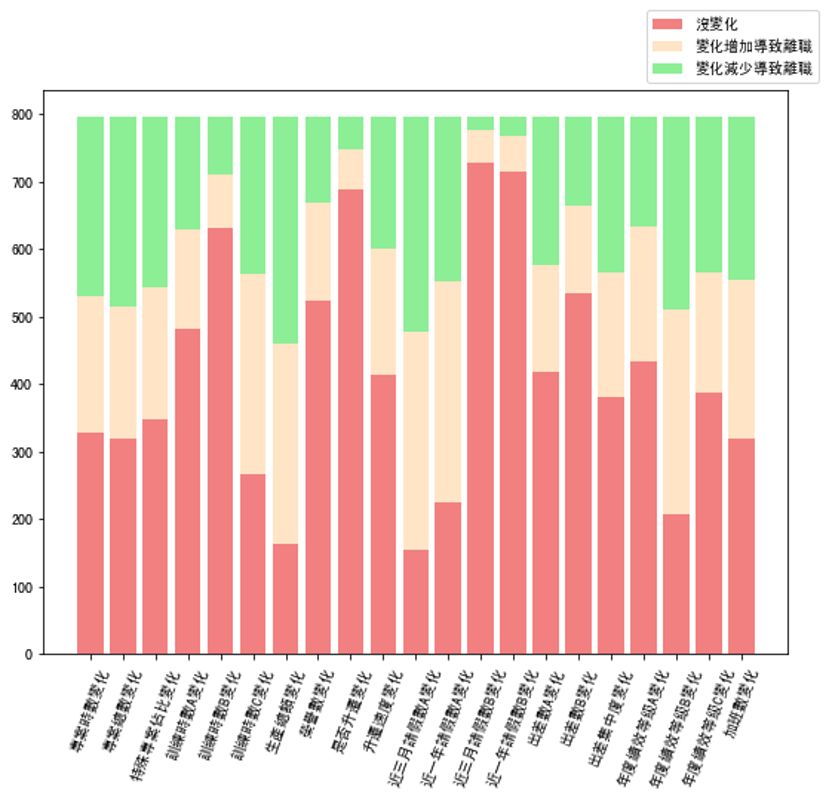
目前對資料大致的觀察就到這邊,每個人對資料的想法都不相同,不一定要照著小編的圖去畫,可能我還有一些特徵細節沒有發現,大家也可以自己去探索看看喔~做資料分析最重要的就是動手去嘗試看看,接下來我們就往資料前處理以及特徵工程的部分繼續邁進啦,我們下篇見~

