這應該也是學習深度學習時的基礎課程,
不確定跟圖像分類比,哪一個會先學到,
但是在接觸深度學習框架時,你應該是碰過迴歸分析預設的問題了。
參考頁面:https://www.tensorflow.org/tutorials/keras/regression?hl=zh_tw
首先是引入模組:
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.layers.experimental import preprocessing
讀取資料集,
這裡可以發現用pandas很神奇的讀取了一個url,
而該url直接下載的話,為一個csv,
url = 'http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data'
column_names = ['MPG', 'Cylinders', 'Displacement', 'Horsepower', 'Weight',
'Acceleration', 'Model Year', 'Origin']
raw_dataset = pd.read_csv(url, names=column_names,
na_values='?', comment='\t',
sep=' ', skipinitialspace=True)
我們可以查看有沒有缺失的數值:
dataset = raw_dataset.copy()
print(dataset.isna().sum())
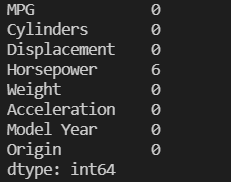
可以發現,馬力的欄位有六筆缺失,
我們丟棄有缺失的資料:
dataset = dataset.dropna()
將Origin欄位轉化為one-hot-encoding格式:
dataset['Origin'] = dataset['Origin'].map({1: 'USA', 2: 'Europe', 3: 'Japan'})
dataset = pd.get_dummies(dataset, columns=['Origin'], prefix='', prefix_sep='')
print(dataset.tail())

切分訓練集及測試集:
train_dataset = dataset.sample(frac=0.8, random_state=0)
test_dataset = dataset.drop(train_dataset.index)
我們可以做圖查看其他特徵與燃油效率(MPG)的關係:
sns.pairplot(train_dataset[['MPG', 'Cylinders', 'Displacement', 'Weight']], diag_kind='kde')
plt.show()

可以發現MPG與Displacement及Weight呈現反比。
將MPG設定成要預測的label:
train_features = train_dataset.copy()
test_features = test_dataset.copy()
train_labels = train_features.pop('MPG')
test_labels = test_features.pop('MPG')
再來,我們想先以單一特徵 馬力(Horsepower) 來預測 MPG ,
我們先將 馬力(Horsepower) 進行Normalization前處理,
horsepower = np.array(train_features['Horsepower'])
horsepower_normalizer = preprocessing.Normalization(input_shape=[1,], axis=None)
horsepower_normalizer.adapt(horsepower)
搭建model, layers.Dense(units=1)為輸出的預測(指預測MPG一個數值),設定好優化器及損失函數:
horsepower_model = tf.keras.Sequential([
horsepower_normalizer,
layers.Dense(units=1)
])
horsepower_model.compile(
optimizer=tf.optimizers.Adam(learning_rate=0.1),
loss='mean_absolute_error')
進行訓練:
history = horsepower_model.fit(
train_features['Horsepower'], train_labels,
epochs=100,
# suppress logging
verbose=0,
# Calculate validation results on 20% of the training data
validation_split = 0.2)
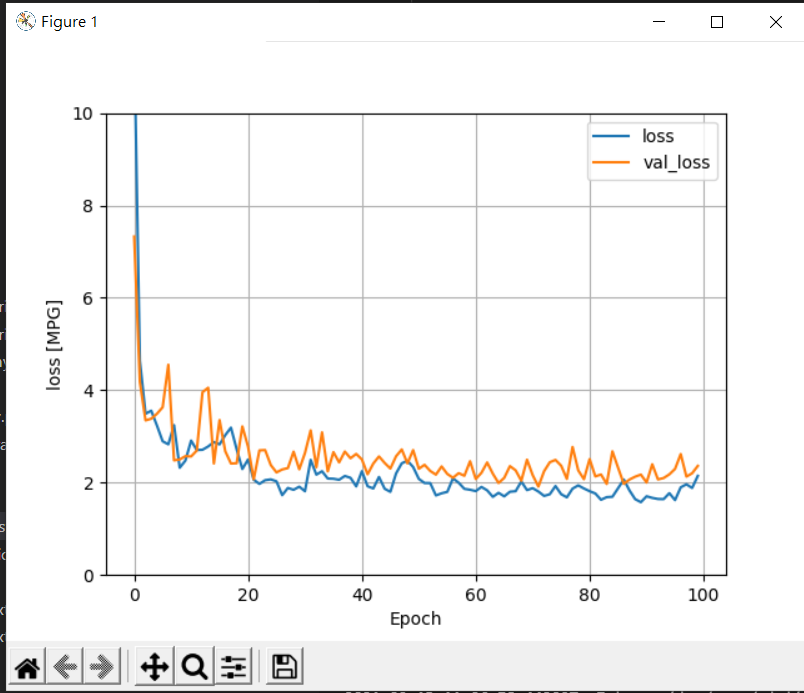
將損失函數作圖,看犯的錯誤是不是越來越少:
def plot_loss(history):
plt.plot(history.history['loss'], label='loss')
plt.plot(history.history['val_loss'], label='val_loss')
plt.ylim([0, 10])
plt.xlabel('Epoch')
plt.ylabel('Error [MPG]')
plt.legend()
plt.grid(True)
plt.show()

再來我們想將所有特徵都拿來進行預測,
先進行前處理
normalizer = preprocessing.Normalization(axis=-1)
normalizer.adapt(np.array(train_features))
# 在進行文字向量化、Normalization、CategoryEncoding等等前處理時,記得先call adapt這個方法
# 否則損失函數降不下來
# 參考資料: https://www.tensorflow.org/guide/keras/preprocessing_layers
建立model:
linear_model = tf.keras.Sequential([
normalizer,
layers.Dense(units=1)
])
linear_model.compile(
optimizer=tf.optimizers.Adam(learning_rate=0.1),
loss='mean_absolute_error')
訓練及作圖
history = linear_model.fit(
train_features, train_labels,
epochs=100,
# suppress logging
verbose=0,
# Calculate validation results on 20% of the training data
validation_split = 0.2)
plot_loss(history)
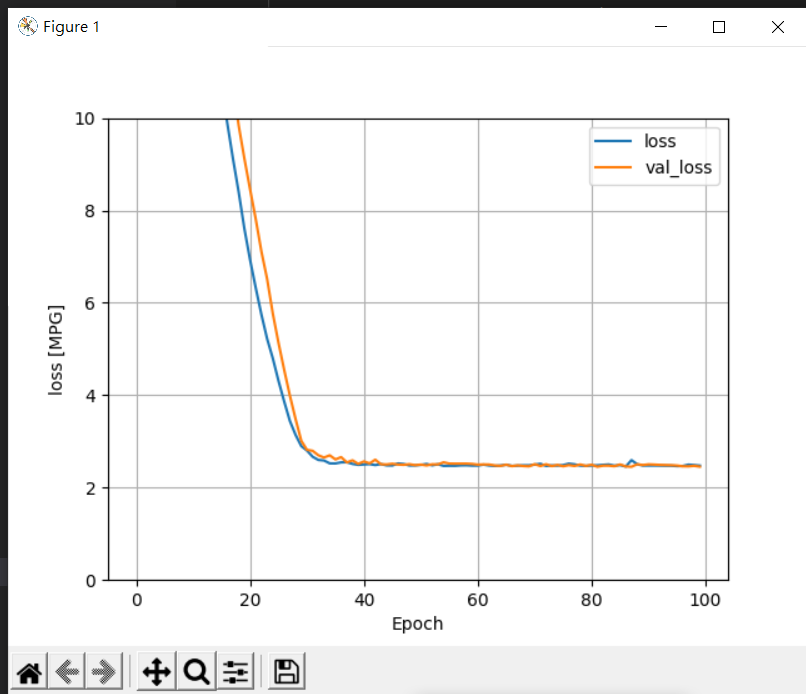
那我們也可以自行修改model layers的鋪設:
linear_model = tf.keras.Sequential([
normalizer,
layers.Dense(64, activation='relu'),
layers.Dense(32, activation='relu'),
layers.Dense(units=1)
])
察看結果: