由於公司中的長官想要看BERT的模型介紹以及使用方式,
因此,文章介紹的航行方向由時間序列預測,先改變為文字上的處理。
參考頁面:https://www.tensorflow.org/tutorials/load_data/text?hl=zh_tw
官網的攻略有分成兩個範例,我只會參考第一個範例。
第二個範例為用不同荷馬詩詞的翻譯作品,
來預測是哪一位作家翻譯的作品。load資料時使用tf.data.TextLineDataset()來載入巨型的資料,
並且使用詞頻的概念來進行預測,有興趣可以自行參觀一下。
在字詞量不是很大時,可以使用One Hot Encode 的方式來將文字轉換特徵:
原始資料
['cold' 'cold' 'warm' 'cold' 'hot' 'hot' 'warm' 'cold' 'warm' 'hot']
變成
[[ 1. 0. 0.]
[ 1. 0. 0.]
[ 0. 0. 1.]
[ 1. 0. 0.]
[ 0. 1. 0.]
[ 0. 1. 0.]
[ 0. 0. 1.]
[ 1. 0. 0.]
[ 0. 0. 1.]
[ 0. 1. 0.]]
但字詞量如果變多了,要運算的特徵會變成巨大的稀疏矩陣,
耗費效能,造成效率不夠快。
這個時候我們可以將文字轉為向量,進而進行運算。
由於運行的環境採用tf-nightly 2.7.0的版本,因此使用官網攻略提供的colab,
來執行程式:
https://colab.research.google.com/github/tensorflow/docs/blob/master/site/en/tutorials/load_data/text.ipynb?hl=zh_tw#scrollTo=sa6IKWvADqH7
載入模組:
下載資料集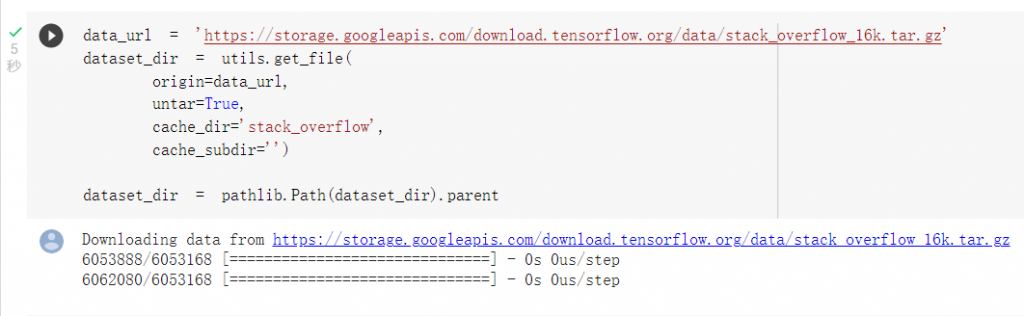
可以發現資料集已經區分了訓練集以及測試集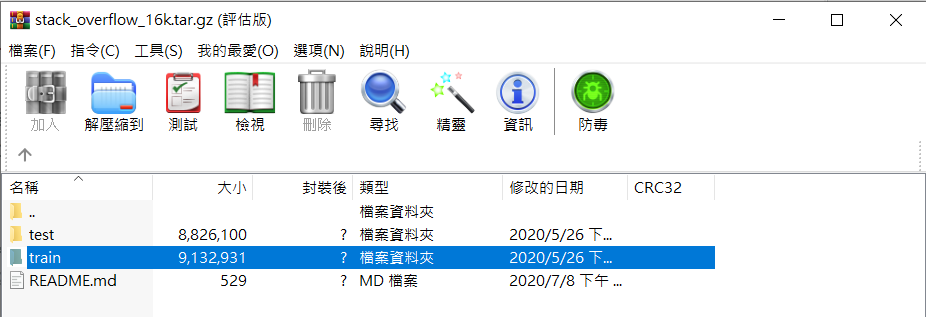
這裡要解決的問題是依照stack_overflow問題的文章內容,
來預測想要解決的程式語言為哪一個類別。
訓練集及測試集依照標籤(程式語言)來放置文章:
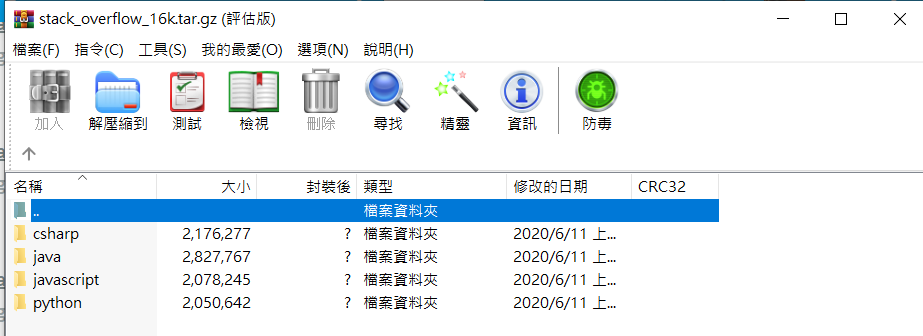
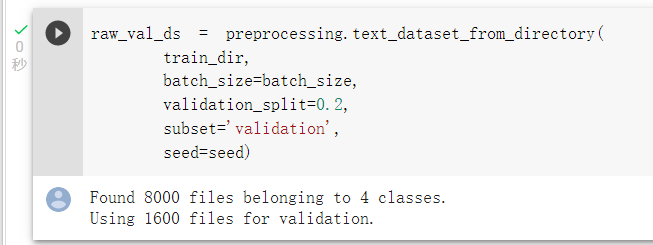
使用preprocessing.text_dataset_from_directory(),
來載入並且區分訓練集及驗證集: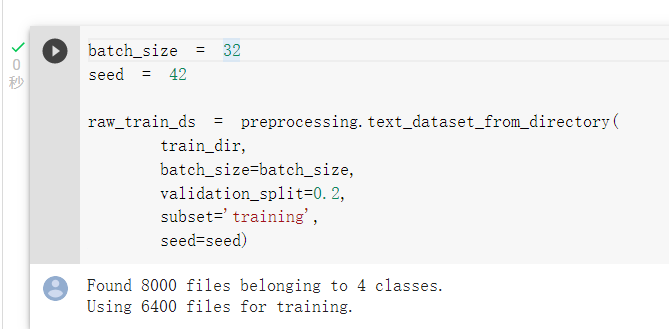
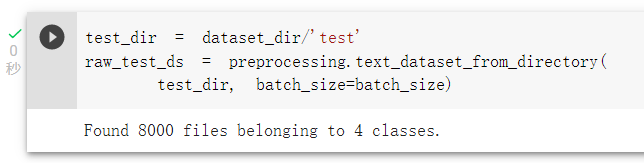
載入測試集:
這裡官網提供兩種將文字轉換為項量的方法:
第一種:詞袋法(特徵轉換為0或1的數值)該前處理層

第二種:轉換為整數數值向量 該前處理層

前處理層可以幫我們完成去除標點符號,斷詞,統整向量長度(以前還要自己padding,現在不用了),
將文字轉向量,簡單來說就是把工作全包了。
將前處理層適應訓練特徵(這步很重要,否則訓練完模型表現會很差)
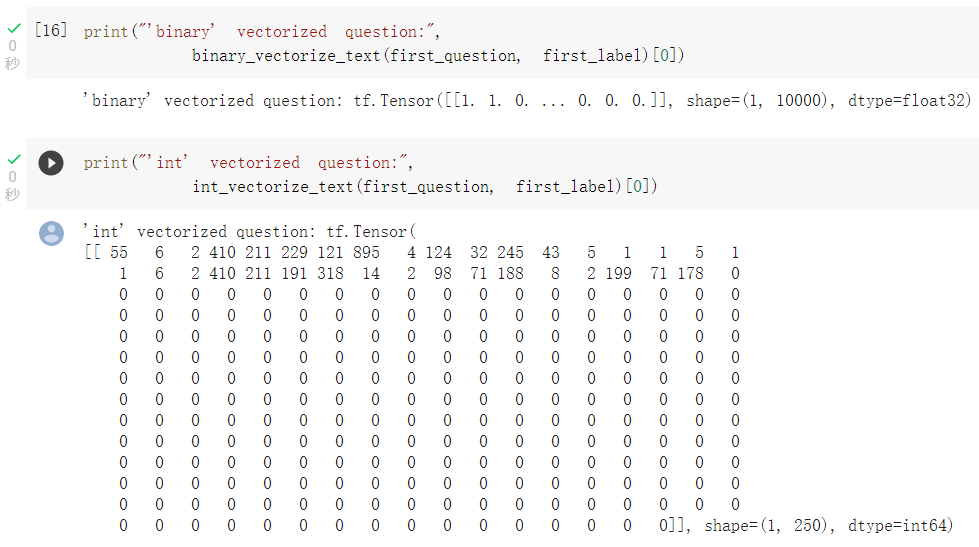
可以查看不同轉換法,轉換出來的向量格式:
將訓練、驗證、測試集都套用上方的function來轉換為向量:
使用緩存資料來加速訓練的速度:
使用詞袋法模型進行訓練: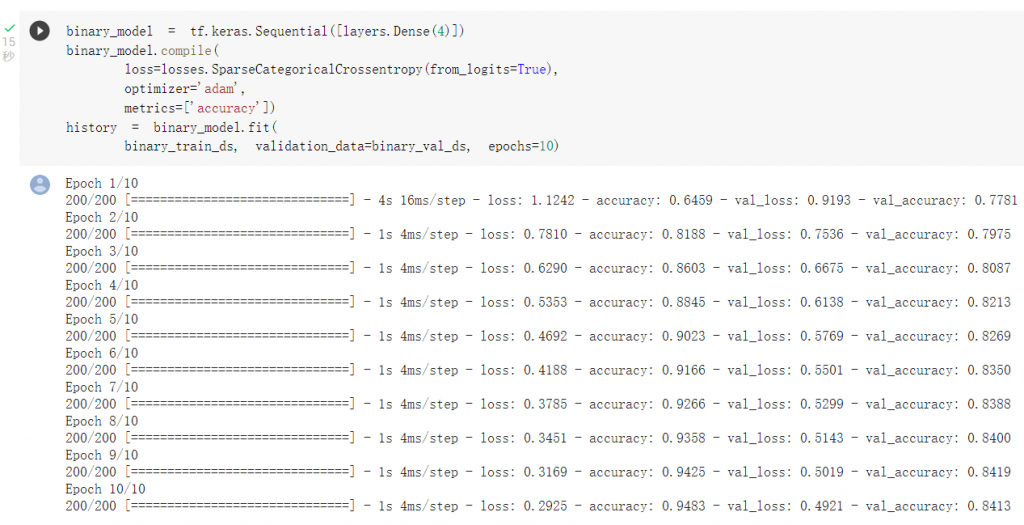
整數數值模型訓練: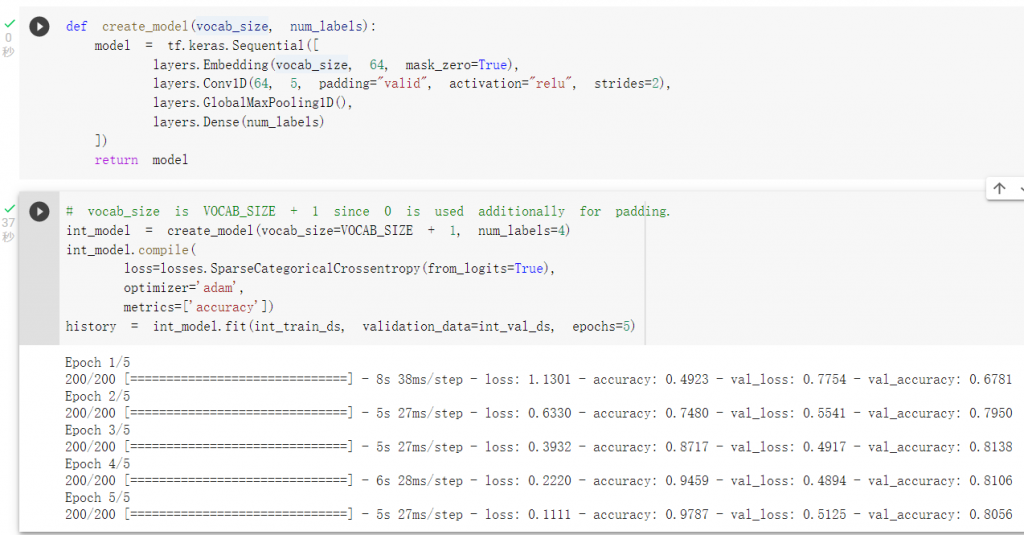
可以比較兩種模型的準確度: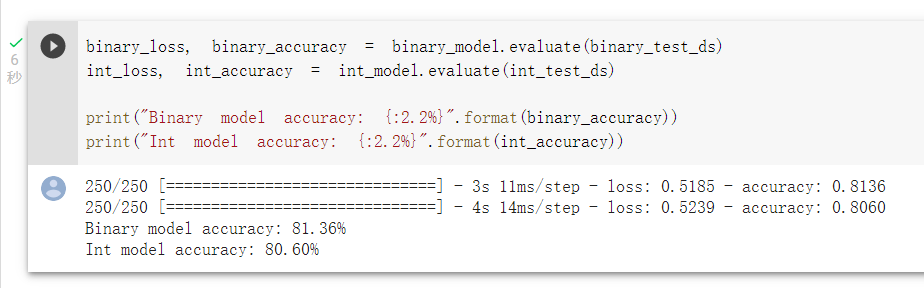
雖然詞袋法準確度較高1%,不過我以前的經驗比較少看到以詞袋法來建模的應用。
那我們可以將前處理層compile進模型,export_model可以供未來使用: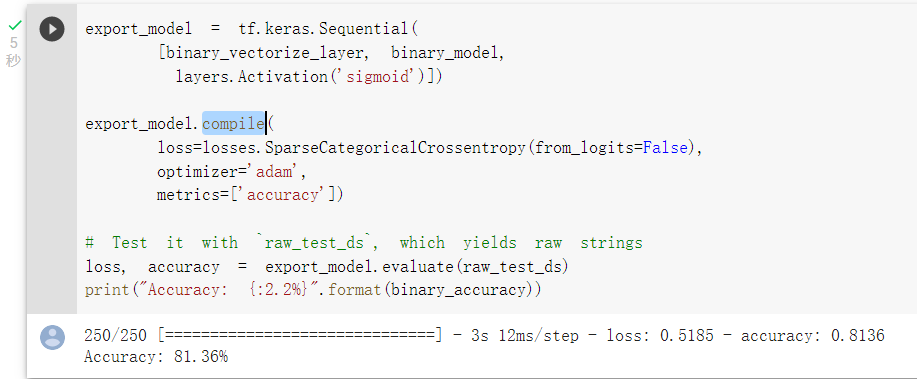
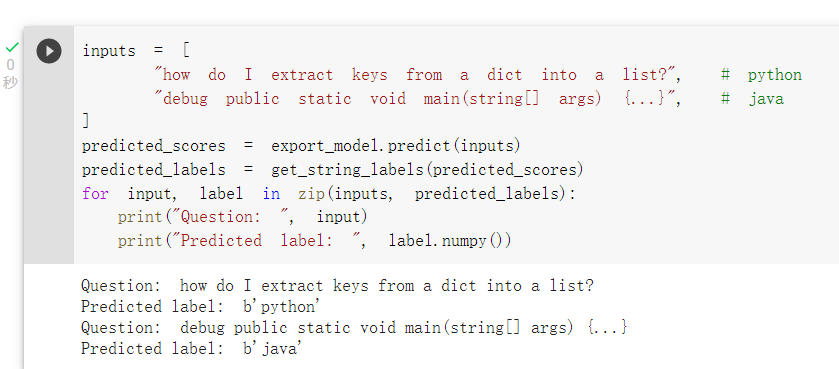
未來進行預測: