今天我們不教程式,而是想帶大家讀一篇關於模型的論文,那為什麼會有這一Part呢?以前小編也不喜歡讀Paper,覺得了解理論很浪費時間,會實做比較重要,但慢慢到了一些更進階的專案時,你會發現懂得越少,就會越不了解怎麼增進自己的模型,所以讀Paper也算是找靈感的一種方式,那麼今天就帶大家一起讀這篇MobileNets的論文。
近年來神經網路一直在不斷的進步,但很多模型都只專注於準確度的提升,而忽略了讓網路更有效率的提升速度和大小,在真實世界中,很多識別任務是需要在計算量受限的裝置或平台上應用的,像是自動駕駛、機器人等等。
然而很多小型網路的論文又只注重在規模,而忽略了速度,這篇論文提出的MobileNets,就是兼顧了大小與速度的模型,並追求能在行動裝置(Mobile)上實行。
MobileNet主要是透過架構上的改變去降低它的模型大小和計算量,我們先來看一下一般的Convolution Layer是怎麼運作的: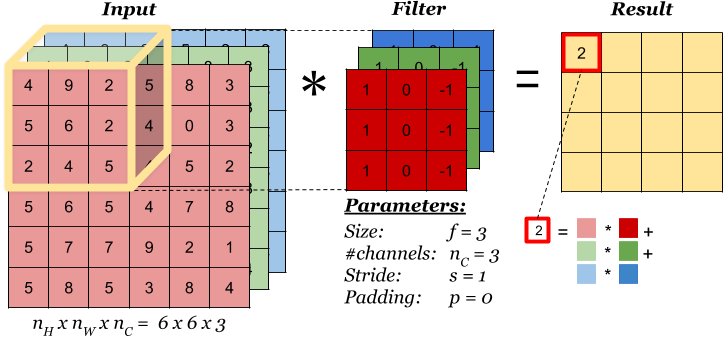
圖片來源:https://medium.com/daai/哇-convolution-neural-network-卷積神經網絡-這麼特別-36d02ce8b5fe
上圖中可以看到,一般的Convolution是將每個Channel都乘上Filter得到結果最後疊在一起成為Feature map,接著我們來看看MobileNet的作法。
MobileNet將捲積層拆分為兩部分,Depthwise Convolution以及Pointwise Convolution,其概念是在不影響網路輸出結構下減少運算量。
與一般的捲積運算不同,Depthwise Convolution針對輸入資料的每一個Channel都建立一個kk的Filter,各自分開做Convolution。
而為了維持輸出的維度不變,在做完Depthwise Convolution後每個Channel再去乘上一個11的Filter做捲積,疊起來後就會得到一樣的Feature map。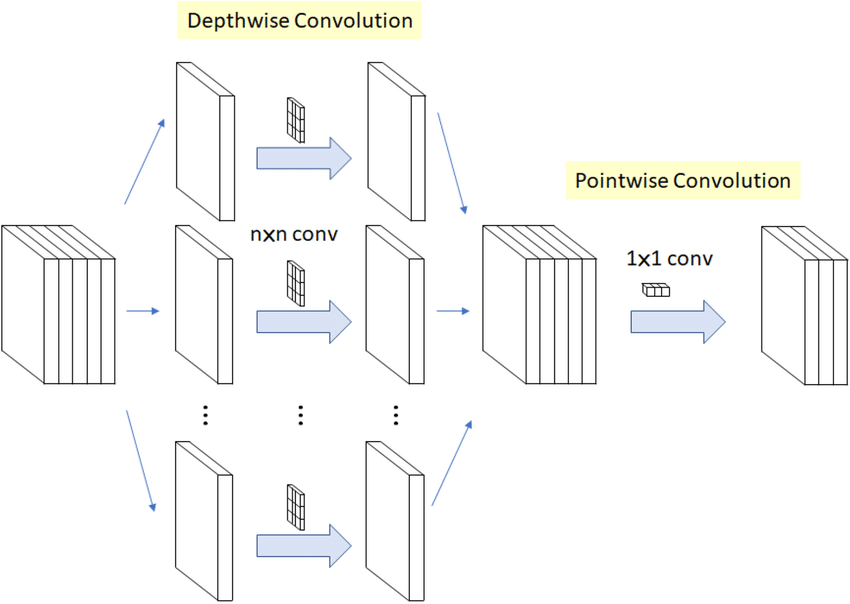
圖片來源:https://www.cnblogs.com/shine-lee/p/10243114.html
下圖是一般捲積運算(左)與Depthwise Seprarable Convolution(右)的架構差異,Depthwise Seprarable Convolution看似比較複雜,結構上比一般的捲積運算來的深,但其實運算量的差異是相反過來的。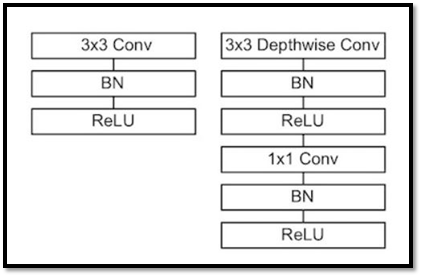
一般捲積計算量:
W_in * H_in * Nch* k * k * Nk
Depthwise Seprarable Convolution計算量:
W_in * H_in * Nch* k * k + Nch*Nk * W_in * H_in
差異:
除了架構上的優化,MobileNet還有兩個超參數可以調整,分別是Width Multiplier以及Resolution Multiplier。
用來讓模型縮得更小,方法是對網路的輸入輸出層的通道數乘上一個alpha值,值介於[0,1],較常見的值有1、0.75、0.5、0.25,輸入通道M會變為Malpha;輸出通道N會變為Nalpha,因此這個參數可以使計算量減少alpha^2,雖然這麼做也會導致準確度跟著下降,因此使用上還是要拿捏一下。
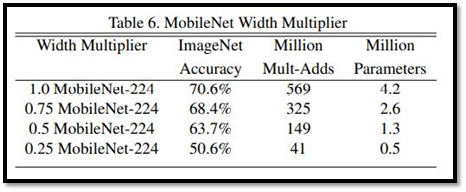
這也是一個控制模型大小的參數,方法是將輸入圖像縮小,降低計算量,常見的縮放值有[224,192,160,128],這麼做所降低的計算量為p^2,但參數量並不會減少。
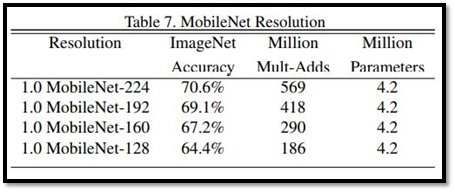
首先是比較使用Depthwise Seprarable Convolution(下)與使用一般的Convolution(上),下圖中可以看到無論是參數量還是計算量,使用Depthwise Seprarable Convolution都有非常顯著的進步,而且準確率這方面是差不多的。
下圖是MobileNet與其他幾個較著名的模型的比較,可以看到在維持準確率的同時,相較於其他網路MobileNet不論是計算量還是模型大小都表現得很出色。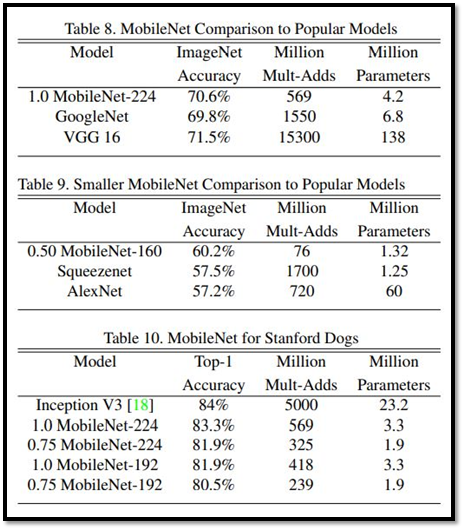
論文也提供了幾個研究,像是準確度與計算量、準確度與模型參數量的相關性,就像我們前面講的,計算量越高、參數量越高,準確率就會越高。
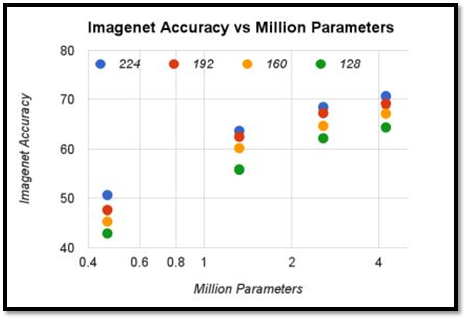
這篇論文提出了使用Depthwise Seprarable Convolution的新模型MobileNets,並且提供了兩個超參數去配合執行環境調整模型,研究結果也得知,MobileNets相較於其他模型,擁有速度更快,尺寸更小的優勢,實現了將深度學習模型部屬到一些行動裝置上。

