我們在做監督式學習(Supervised Learning)的時候通常會耗費大量時間去訓練,且每個專案我們都必須重新開始,時間成本實在太高了,為了解決這個問題,遷移式學習的想法就誕生了。
我們利用"神經網路在前一個任務中學習到的知識"去學習下一個專案,稱之為"骨幹網路",舉例來說,假如你學習過高中的課程後,再讓你去學習國中的課程,雖然程度不一樣,但你利用先前學習過的知識,學習起來就會相對輕鬆,遷移式學習就是利用這個概念,讓網路學習過一些龐大的資料集,再將權重儲存起來,應用在不同的專案中。
這邊要介紹一些經典有名的資料集,我們常常會使用這些數據集所訓練出的權重來使用。
最著名的就是ImageNet,它是由普林斯頓大學的李飛飛教授所發起的一項專案,這項專案希望能蒐集到海量的圖片作為資料庫來做訓練,並以這份資料來訓練骨幹網路,該專案利用發起比賽來蒐集資料,擁有多達1400萬張的圖片、1000種類別的資料集。
圖片來源:https://cv.gluon.ai/build/examples_datasets/imagenet.html
其他還有像是MNIST(手寫數字的圖片)、cifar10(10種類別的圖片)等資料集,都是擁有上萬張圖片以上的資料庫,且都有提供開源下載,這些都是我們在做遷移式學習中相當好用的輔助資料集。我們使用這些資料集的權重加到網路上,再稍微修改程式和我們的資料集,這個動作就是微調(Fine-tune)
Keras提供了相當多的骨幹網路以及使用辦法,連結附在下方給大家參考:
Keras Applications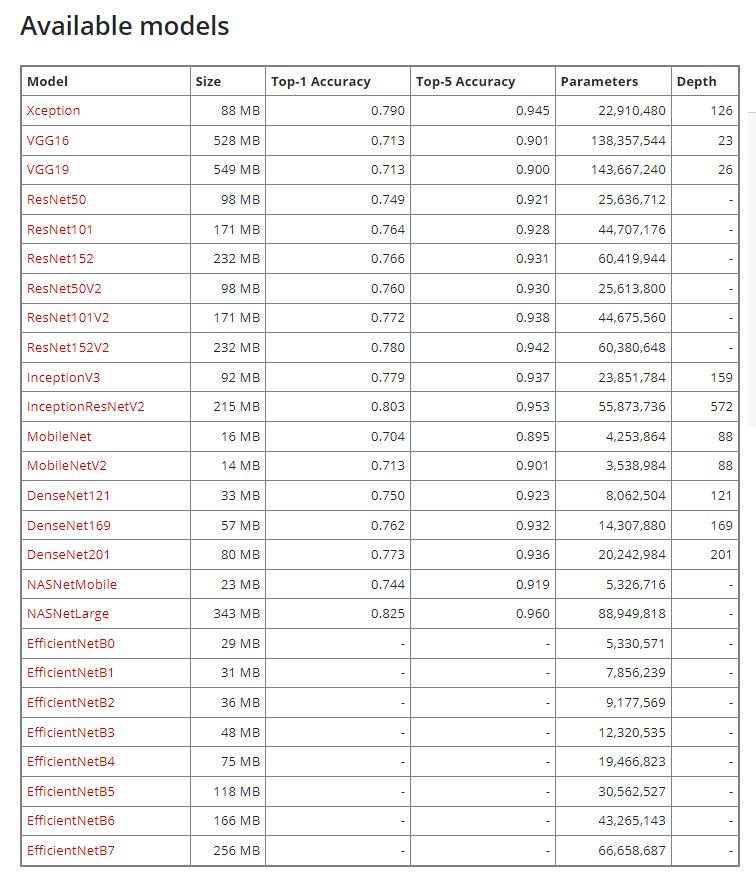
這裡補充解釋一下,上圖中的size代表模型大小Top-1 ;Accuracy代表預測一次的準確度、Top-5 Accuracy代表預測五次內正確的準確度;Parameters代表模型總參數量,Depth代表模型深度。

其中的weights="imagenet"就代表我們使用ImageNet的權重來做基底。
model.summary()
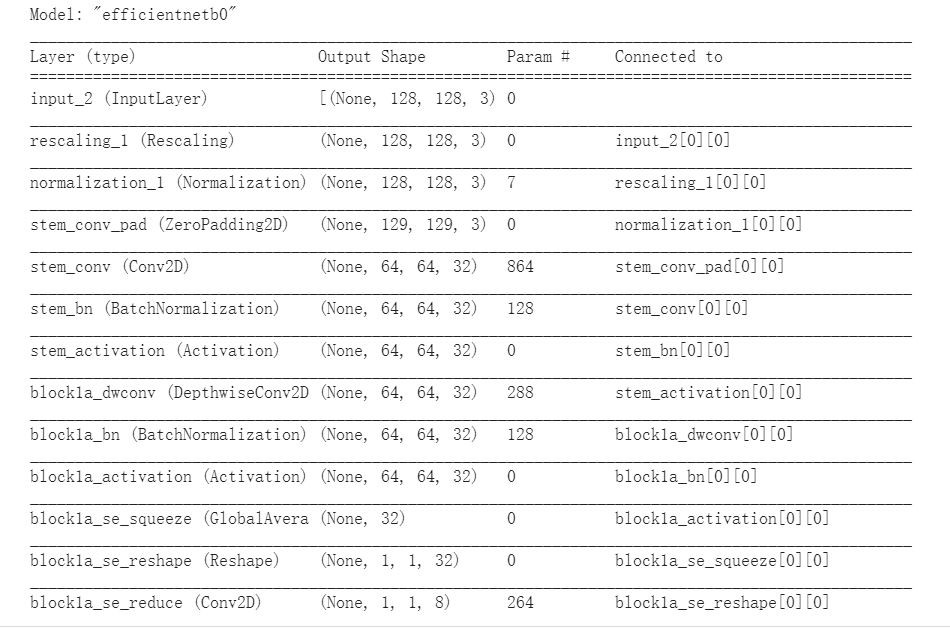
雖然我們使用了別人的網路,但我們還是有一些設計空間的,何況資料集還是我們自己的,因此要將這個網路的Input與Output改成資料及所對應的格式。
inputs = tf.keras.Input(shape=(3,))
x = tf.keras.layers.Dense(4, activation=tf.nn.relu)(inputs)
outputs = tf.keras.layers.Dense(5, activation=tf.nn.softmax)(x)
model = tf.keras.Model(inputs=inputs, outputs=outputs)
在使用預訓練模型時要注意是否和自己的資料集相差過大,避免使用錯誤的模型來訓練資料,而根據資料集的特性去微調模型的方法有以下幾點:
通常是我們的資料集與預訓練模型的資料集情況相當類似,我們就只需要修改輸入層與輸出層的結構就好,這也是最理想的方式。
假如這份資料集與預訓練模型的資料情況有些差異,我們需要的特徵可能就需要重新提取,但如果我們的資料集又不多,就可以選擇這種方式,凍結神經網路中前面幾層,不做權重的修改,而放開後面幾層重新做特徵的提取,這個方法往往要花較多時間嘗試凍結層數的平衡。
其實在一種情況下我們可以完全捨棄預訓練模型的權重,那就是我們的資料集足夠多的情況,且資料與預訓練權重的差異度又過大,這時我們完全有足夠的資料量讓神經網路學習,我們就可以從頭搭建網路來進行訓練。
以現階段來說,我們還是有極高的機會去使用到預訓練模型,因為我們實在很難蒐集到一份海量的資料集,透過使用前人留下的經驗,我們可已大大的優化自己的模型,今天程式實作的部分比較少,就留到之後的專案實作吧!

