在前一天的最後有提到說透過類神經網路(DNN)使得從輸入端到輸出端只透過一個模型就完成語音辨識,像這樣的方法我們稱作端到端(end-to-end)。目前常見的方法有 Sequence to sequence (Seq2seq) 和 Connectionist Temporal Classification(CTC)。
Seq2seq 顧名思義就是輸入一個序列,模型會輸出另一個序列,這種模型架構最重要的地方在於輸入序列跟輸出序列的長度是可變動的。Seq2seq 模型主要包含了 encoder, decoder ,因此也被稱作 encoder-decoder framework,基本架構如下圖: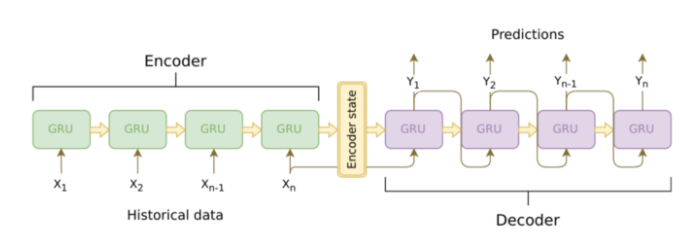
Seq2seq 架構圖,圖片來源: https://jeddy92.github.io/JEddy92.github.io/ts_seq2seq_intro/
Encoder 與 decoder 通常會採用遞迴神經網路(RNN)的架構,以上圖的例子就是採用 GRU (Gate Recurrent Unit)。
Encoder 是負責處理輸入的序列轉換成機器能夠理解的 encoder state (也被稱為 context vector, thought vector),而decoder 再將 encoder state 解碼成最後預測輸出的文字序列。
context vector 可以理解成是一個包含所有輸入序列訊息的向量並且負責 encoder 與 decoder 之間訊息的傳遞,在實際神經網路的運作過程中,context vector 也就是 encoder 中的最後一個 hidden state (如上圖encoder最後一個GRU的輸出)。因此 encoder 會將輸入序列轉換、壓縮成固定長度的 context vector。但如果輸入的序列的長度較長的話,固定長度的 context vector 所產生的辨識效果就會變差,為了解決此問題,研究人員研究出了注意力模型 (attention model)。
今天的內容就到這邊了,明天將會來介紹注意力模型(attention model)。

