
| 模型 | 進度 |
|---|---|
| VGG Net | (完成) |
| ResNet | (完成) |
| DensNet | (此篇) |
| MobileNet | (未完成) |
| EfficientNet | (未完成) |
大家都知道模型越深就越有潛力達到更高的準確率。
但是隨著深度增加,梯度消失的問題就更嚴重,
ResNet的設計就是用來減緩這個問題,
而DenseNet就是在ResNet的基礎上去做改良。
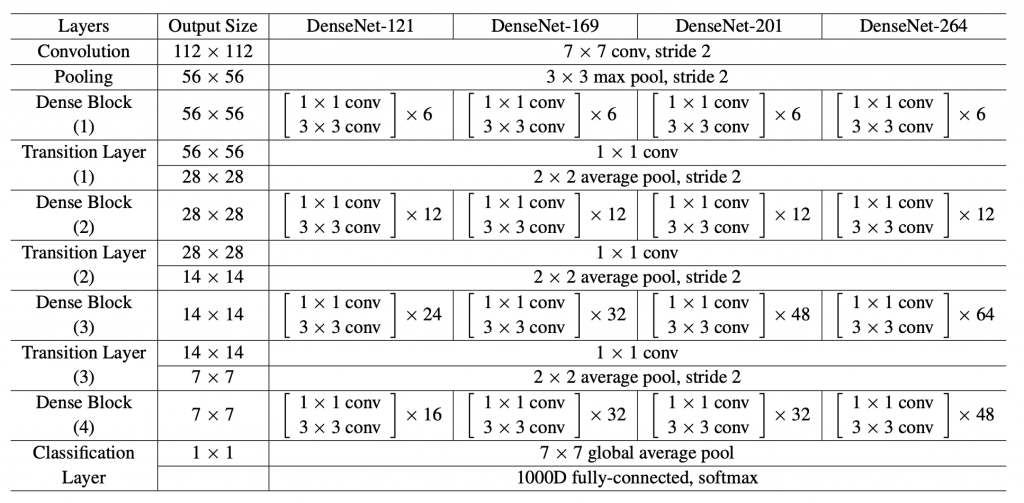
DenseNet 全名為 Densely Connected Convolutional Network。
由許多個Dense Block組成,每個Block皆採用bottleneck結構。
而Dense Block用了許多「層與層的連結」來達到特徵重用性。
其論文開門見山地說:
Recent work has shown that convolutional networks can be
substantially deeper, more accurate, and efficient to train
if they containshorter connections
between layers close to the input and those close to the output.
這個shorter connections就是指ResNet中的直連通路,
ResNet只是在block的最頂端拉一條線出來,
做identity connection傳到block的最底端。
但是DenseNet更狠!直接讓每一層的輸出傳遞到之後的每一層,
相當於是做了超多次identity connection。
假如我們有L層卷積神經網路,那就有個(層與層之間的)連結。
但是DenseNet設計成有個連結。
如下圖所示: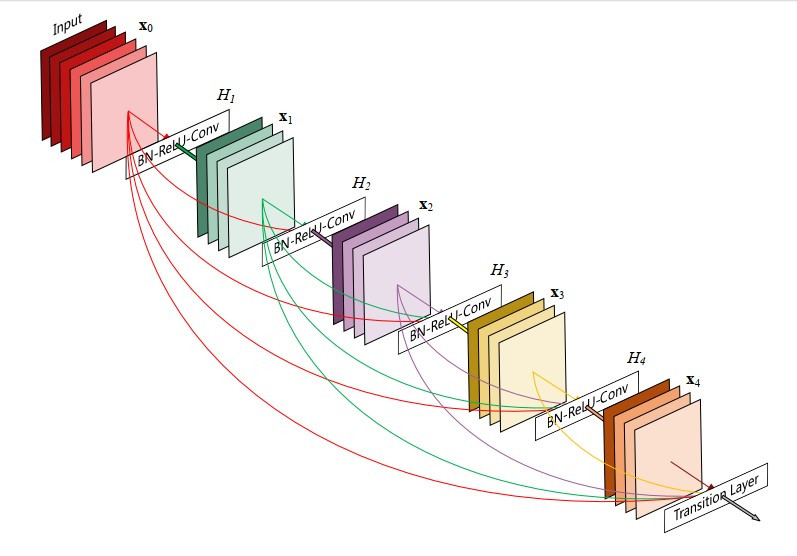
寫成數學式子就長這樣:
這個所謂「拉一條線出來做連結」其實就是在避免模型太「寬」。
我們可以發現當年的模型基本上都在追求又寬又深(又大又圓),像是GoogLeNet。
但是DenseNet不屑透過加深和加寬網路來增強圖像表徵能力,
DenseNet利用"特徵重用性"來做到這件事。
這個專有名詞是指卷積層中卷積核的數量(k),
在DenseNet的實驗中發現設k=12也能夠獲得和其他state-of-the-art一樣的效果。
所以DenseNet是可以很「窄」(narrow)的。
更加減緩梯度消失問題:
由於Densely connected,反向梯度傳播十分容易,模型收斂效果佳。
特徵重用性:
從低階特徵到高階特徵都會被直連到最後一層卷積層,
這讓下一層接受到更全面的圖像資訊。
減少參數量:
這很反直覺,這麼多連結卻減少參數量?
那是因為對於舊的特徵圖(feature-map)是不需要再去重新學習的,
而且因為growth-rate不用設很大,所以減少許多參數。
看起來DenseNet稍微減緩了人們對於模型寬度的追求,
但不得不說,每個人在調整模型架構的時候都是先往加深加寬的方向。
而沒有去考慮用更有效的層與層之間的連接方式。
我想我們應該要去思考:
有沒有一種模型架構是可以容許我們用少少的深度和寬度,
就可以獲得跟DensNet一樣的效果呢?
因為Dense Block的結構很簡單,
所以我練習用keras實現它,
如果我寫錯了...還請大家幫忙debug
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense, BatchNormalization, ReLU
from tensorflow.keras.layers import Concatenate, Dropout
from tensorflow.keras.layers import Conv2D, AveragePooling2D, MaxPooling2D
from tensorflow.keras.layers import GlobalAveragePooling2D
def DenseLayer(x, growthRate, dropRate=0):
# bottleneck
x = BatchNormalization(axis=3)(x)
x = ReLU(x)
x = Conv2D(4*growthRate, kernel_size=(1, 1), padding='same')(x)
# composition
x = BatchNormalization(axis=3)(x)
x = ReLU(x)
x = Conv2D(growthRate, kernel_size=(3, 3), padding='same')(x)
# dropout
x = Dropout(dropRate)(x)
return x
def DenseBlock(x, num_layers, growthRate, dropRate=0):
for i in range(num_layers):
featureMap = DenseLayer(x, growthRate, dropRate)
x = Concatenate([x, featureMap], axis=3)
return x
def TransitionLayer(x, ratio):
growthRate = int(x.shape[-1]*ratio)
x = BatchNormalization(axis=3)(x)
x = ReLU(x)
x = Conv2D(growthRate, kernel_size=(1, 1),
strides=(2, 2), padding='same')(x)
x = AveragePooling2D(pool_size=(2, 2), strides=(2, 2))(x)
return x
def DenseNet121(numClass=1000, inputShape=(224, 224, 3), growthRate=12):
x_in = Input(inputShape)
x = Conv2D(growthRate*2, (3, 3), padding='same')(x_in)
x = MaxPooling2D(pool_size=(2, 2), strides=(2, 2))(x)
x = TransitionLayer(DenseBlock(
x, num_layers=6, growthRate=12, dropRate=0.2))
x = TransitionLayer(DenseBlock(
x, num_layers=12, growthRate=12, dropRate=0.2))
x = TransitionLayer(DenseBlock(
x, num_layers=24, growthRate=12, dropRate=0.2))
x = DenseBlock(x, num_layers=16, growthRate=12, dropRate=0.2)
x = GlobalAveragePooling2D()(x)
x_out = Dense(numClass=1000, activation='softmax')(x)
model = Model(x_in, x_out)
model.compile(optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.CategoricalCrossentropy(), metrics=['accuracy'])
model.summary()
return model
