今天來用decision tree做一個預測腫瘤是惡性還是良性的應用,在這裡就略過前期的資料處理與分割,直接從model應用開始,如果對這個分析有興趣,我有把kaggle連結放在下方可以參考。
剛開始我先寫了一個score function可以把model後續的訓練和測試跑完,最後回傳多種的準確率與Confusion Matrix來判斷模型的好壞。
from sklearn.metrics import accuracy_score, confusion_matrix, precision_score, recall_score, f1_score
def score(m, x_train, y_train, x_test, y_test, train=True):
if train:
pred=m.predict(x_train)
print('Train Result:\n')
print(f"Accuracy Score: {accuracy_score(y_train, pred)*100:.2f}%")
print(f"Precision Score: {precision_score(y_train, pred)*100:.2f}%")
print(f"Recall Score: {recall_score(y_train, pred)*100:.2f}%")
print(f"F1 score: {f1_score(y_train, pred)*100:.2f}%")
print(f"Confusion Matrix:\n {confusion_matrix(y_train, pred)}")
elif train == False:
pred=m.predict(x_test)
print('Test Result:\n')
print(f"Accuracy Score: {accuracy_score(y_test, pred)*100:.2f}%")
print(f"Precision Score: {precision_score(y_test, pred)*100:.2f}%")
print(f"Recall Score: {recall_score(y_test, pred)*100:.2f}%")
print(f"F1 score: {f1_score(y_test, pred)*100:.2f}%")
print(f"Confusion Matrix:\n {confusion_matrix(y_test, pred)}")
我們先建立一棵樹,參數完全使用原本預設的值,接下來看看training結果。
from sklearn import tree
tree1 = tree.DecisionTreeClassifier()
tree1 = tree1.fit(x_train, y_train)
score(tree1, x_train, y_train, x_test, y_test, train=True)

居然拿到了100%正確的預測,但testing的表現才是我們真正在意的,接下來看一下testing的結果,從回傳的結果可以看出model似乎有些overfitting的問題。
score(tree1, x_train, y_train, x_test, y_test, train=True)

要如何解決decision tree overfitting的問題呢?主要可以從參數上來做限制:
1.max_depth(default=None): 限制樹的最大深度,是非常常用的參數
2.min_samples_split(default=2):限制一個中間節點最少要包含幾個樣本才可以被分支(產生一個yes/no問題)
3.min_samples_leaf(default=1):限制分支後每個子節點要最少要包含幾個樣本
來用loop選擇最適合的max_depth:
#decide the tree depth!
depth_list = list(range(2,15))
depth_tuning = np.zeros((len(depth_list), 4))
depth_tuning[:,0] = depth_list
for index in range(len(depth_list)):
mytree = tree.DecisionTreeClassifier(max_depth=depth_list[index])
mytree = mytree.fit(x_train, y_train)
pred_test_Y = mytree.predict(x_test)
depth_tuning[index,1] = accuracy_score(y_test, pred_test_Y)
depth_tuning[index,2] = precision_score(y_test, pred_test_Y)
depth_tuning[index,3] = recall_score(y_test, pred_test_Y)
col_names = ['Max_Depth','Accuracy','Precision','Recall']
print(pd.DataFrame(depth_tuning, columns=col_names))
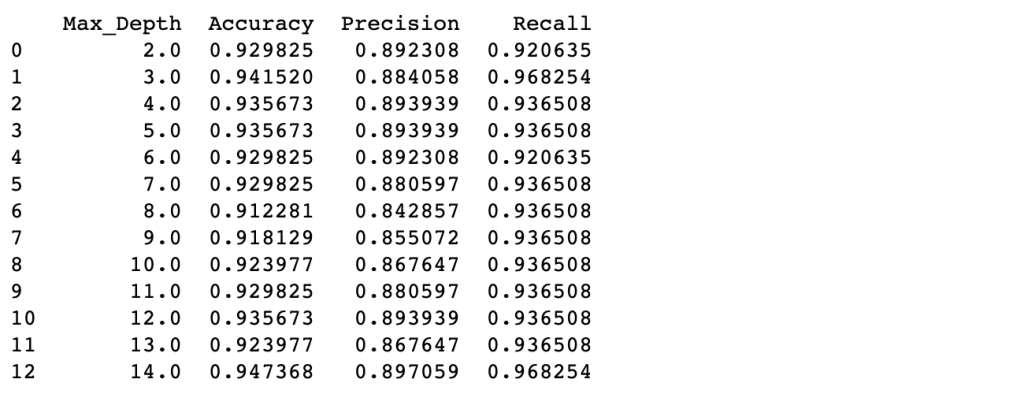
從上面的結果可以發現max_depth=3的時候就可以達到不錯的效果,接下來建一顆新的樹來看看:
tree2 = tree.DecisionTreeClassifier(max_depth=3)
tree2 = tree2.fit(x_train,y_train)
score(tree2, x_train, y_train, x_test, y_test, train=True)

score(tree2, x_train, y_train, x_test, y_test, train=False)

比起本來的樹,設定max_depth=3之後可以獲得更好的預測結果,tuning 成功!
reference:
https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html
http://www.taroballz.com/2019/05/15/ML_decision_tree_detail/
https://www.kaggle.com/nancysunxx/breast-cancer-prediction


 iThome鐵人賽
iThome鐵人賽