
今天繼續針對 Data Analytics Pipeline on AWS 中常見的 AWS 服務來做說明: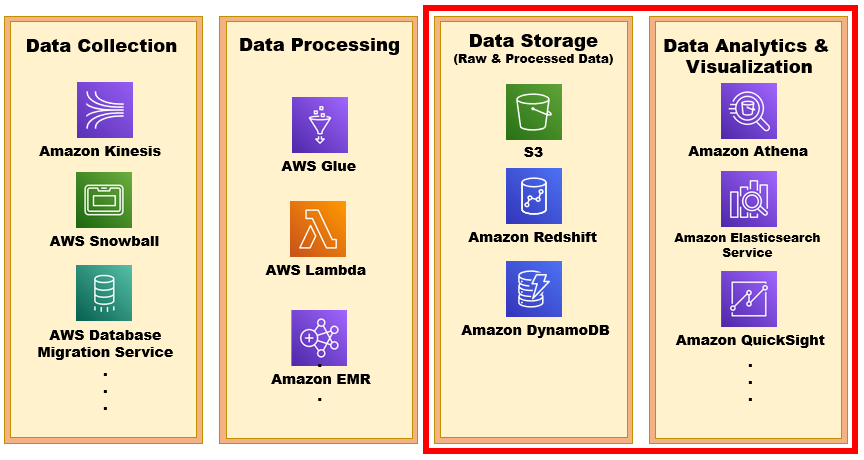
Data Storage Services:
Data Analytics & Visualization:
後續實作,我們也會透過這兩天介紹的這些 AWS 服務建立出合適的 Data Analytics Pipeline,快速簡單地蒐集處理資料以及進行視覺化分析
接著明天就會進入我們資料實作前戲-建置 WordPress on AWS 的部分囉! 我們明天見:)
如果有任何指點與建議,也歡迎留言交流,一起漫步在 Data on AWS 中。
參考&相關來源:
[1] AWS S3
https://aws.amazon.com/tw/s3/?nc=sn&loc=0
[2] AWS Redshift
https://aws.amazon.com/tw/redshift/?whats-new-cards.sort-by=item.additionalFields.postDateTime&whats-new-cards.sort-order=desc
[3] AWS Athena
https://aws.amazon.com/tw/athena/?whats-new-cards.sort-by=item.additionalFields.postDateTime&whats-new-cards.sort-order=desc
[4] AWS QuickSight
https://aws.amazon.com/tw/quicksight/?nc=sn&loc=0
[5] Amazon Elasticsearch Service
https://aws.amazon.com/tw/elasticsearch-service/
