在自然語言處理的諸多課題如信息檢索( information retrieval )和文本探勘( text mining )當中,我們希望找出重要的單詞或文句。在過程中我們需要將文字進行量化(轉化為向量)以進行後續處理及篩選。常見的向量表示法有:
將詞彙表中的單詞進行 One-Hot 編碼
圖片來源:Shane Lynn
各個句子以BoW表示成向量
圖片來源:GDCoder
各個句子以1-grams (tokens) 與 2-grams 表示成向量
圖片來源:GDCoder
然而以上編碼原則皆有一個共通點:每個單詞都被視為一樣重要。然而文件當中通常夾雜許多停用詞如 a 、 the 、 be ,未能提供實際意義,卻往往非常大量地出現在文本當中,因此僅憑單詞出現的次數( occurrences )來說明該單詞在一份文件乃至於整個語料庫中的重要程度,是不具說服力的。今天我們要談的TF-IDF就是一種衡量單詞重要性的加權機制。
TF-IDF 全名為Term Frequency-Inverse Document Frequency,是一種決定單詞對於一份文件重要程度的衡量手法。它由兩個部分組成:詞頻(term frequecny, tf)與逆向文件頻率(inverse document frequency, idf),接下來我們分別來介紹這兩者。
在深入探tf與idf之前,為了避免讀者的困惑,我們先解釋語料庫((text) corpus)、文件(document)和單詞(term)之間的關係。
文件是由單詞構成,例如一篇文章、一首詩詞,在Python當中經常以字串的形式出現,其與單詞的從屬為「單詞屬於文件」;語料庫是多份文件的集合,例如詩集,在Python當中常以list的物件出現,其與文件的從處關係為「文件屬於文語料庫」。
詞頻,顧名思義就是單詞出現在一份文件的頻率。若某一單詞在一份文件當中出現的次數越多,我們會直覺地認為它愈是重要。然而我們不能光以「次數」來衡量,必須考慮文件的篇幅。因此我們需要進行正規化,將次數再除以文件長度,於是有了以「頻率」來衡量單詞重要性的定義方式:
在以上定義中, 表示單詞 t 在文件 d 當中的次數。
衡量單詞相對於文件重要程度的定義方式並不惟一,以下列舉出幾項由傳統詞頻衍生出的加權計算方式:
圖片來源:Wikipedia
有許多單詞,其詞頻非常高,卻不具重要性,如 a/an、 the 等停用詞(stop words)。因此由將單詞出現的次數正規化而得的詞頻還不足以衡量單詞在文本中的重要程度,我們仍需要考慮單詞對於語料庫的重要程度,其定義方式如下: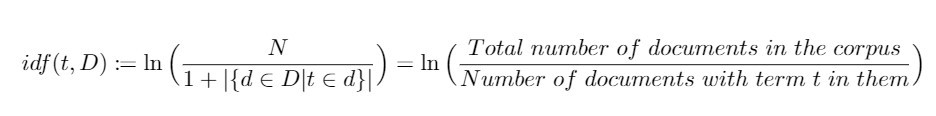
在上述定義當中, D 表示語料庫,其元素為文件 d 。而分母加上1則是為了避免由於單詞不在語料庫中而導致分母為零(division-by-zero)的狀況,是一種well-defined的表現。
藉由對數 ln() 嚴格遞增的特性,我們可以直言:若某個單詞愈是集中出現在某幾份文件中,則 idf 就愈大,其之於整個語料庫而言就愈重要。反之,當某個單詞在大量文件中都出現,idf就愈小,我們會認為這個單詞愈是一般。。
衡量單詞相對於整個語料庫重要程度的定義方式也不是惟一的,以下列舉出幾項由傳統IDF衍生出的加權計算方式:
圖片來源:Wikipedia
當我們將 tf 和 idf 相乘起來,就可以反映出一個單詞在語料庫中對於一份文件有多麼重要。於是我們可以來正式定義今日的主人公 tf-idf :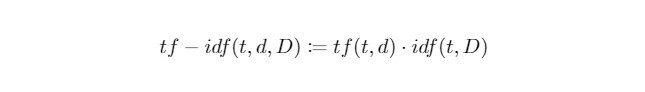
接下來我們示範如何計算單詞對於文件的 tf-idf 權重。
首先我們定義好含有三份文件(單一句子所構成的字串)的小型語料庫,並且對語料庫進行前處理:
from preprocessing import preprocess_text
# sample documents
document_1 = "This is the first sentence!"
document_2 = "This is my second sentence."
document_3 = "Is this my third sentence?"
# corpus of documents
corpus = [document_1, document_2, document_3]
# preprocess documents
processed_corpus = [preprocess_text(doc) for doc in corpus]
scikit-learn 函示庫中收錄了計算 tf-idf 的物件 TfidfVectorizer ,直接引入即可。將剛才前處理後的語料庫當作訓練資料進行擬合,我們即可得到每個單詞相對於各個文件的權重:
from sklearn.feature_extraction.text import TfidfVectorizer
# initialise TfidfVectorizer
vectoriser = TfidfVectorizer(norm = None)
# obtain weights of each term to each document in corpus (ie, tf-idf scores)
tf_idf_scores = vectoriser.fit_transform(processed_corpus)
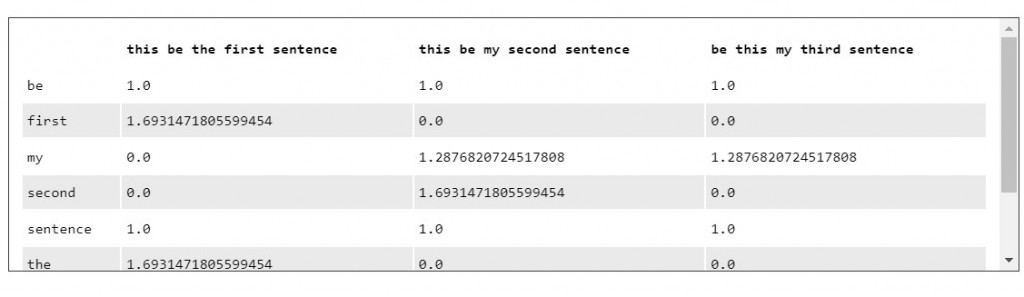
文件矩陣(term-document matrix)用來表示各個單詞在整個語料庫中之於文件的重要性,其由 tf-idf scores 所構成。
我們透過轉換為 pandas dataframe 將結果呈現出來:
# get vocabulary of terms
feature_names = vectoriser.get_feature_names()
corpus_index = [n for n in processed_corpus]
import pandas as pd
# create pandas DataFrame with tf-idf scores: Term-Document Matrix
df_tf_idf = pd.DataFrame(tf_idf_scores.T.todense(), index = feature_names, columns = corpus_index)
print(df_tf_idf)
時不我與,今天的介紹就到這邊,我們明天見!




