在我們每日使用的語言當中,我們經常能根據單詞所表的意義區分出同義詞與反義詞,例如英文中形容詞 thoughtful 與 attentive 、 considerate 同義,與 thoughtless 、 unthinking 反義。而當提及現任美國總統 Joe Biden 時,我們也許會在腦中浮現同在政壇上具有影響力的德國總理 Angela Merkel ,然而我們不容易聯想到已故知名球星 Kobe Bryant,這是因為 Joe Biden 這個人名經常出現在國際政治相關的語境中。我們可以粗略地說, Joe Biden 與 Angela Merkel 較為接近,與 Kobe Bryant 較為疏遠,儘管他們都具有美國籍。這裡所探討的親疏關係,指的是語意上的相似度(Semantic Similarity)。
在自然語言處理中,我們會透過將單詞乃至文本量化以近一步表示文字之間的「距離」。之前我們介紹過三種文字的向量表示法: Bag of Words (BoW) 、 Bag of N-Grams (BoN) 和 One-Hot Encoding ,雖然皆容易理解也很好實踐,然而他們卻有以下致命的缺點:
既然以上的向量表示法皆無法乘載語意相似度資訊,我們另尋資訊稠密且維度低的向量表示法。
「物以類聚」是我們耳熟能詳的一句諺語。在語言學的脈絡裡,語言學家則認為在相同上下文中一起出現的兩個單詞會有相似的意義,這就是著名的分布假說( distributional hypothesis )。
Distributional Hypotheis:
Linguistic items with similar distributions have similar meanings.
-Harris, Z (1954)
"You shall know a word by the company it keeps."
-John Rupert Firth (1957)
詞嵌入( word embedding )也是一種文字的向量表示法,使得在相同上下文中愈常共同出現的單詞能夠被表示成在向量空間中距離愈靠近的向量;反之,愈少共同出現的單詞,其向量距離就愈遠。因此 word embedding 藉由更高的維度將語意相似度的資訊保留了起來。
word embedding 表示法具有兩項優勢:維度縮減( diemension reduction )、上下文相似性( context similarity )
在命名實體識別( Named-Entity Recognition, NER )、情感分析( sentiment anaylsis )和推薦系統( recommendation system )等自然語言處理的課題中皆使用了 word embedding 的技術。
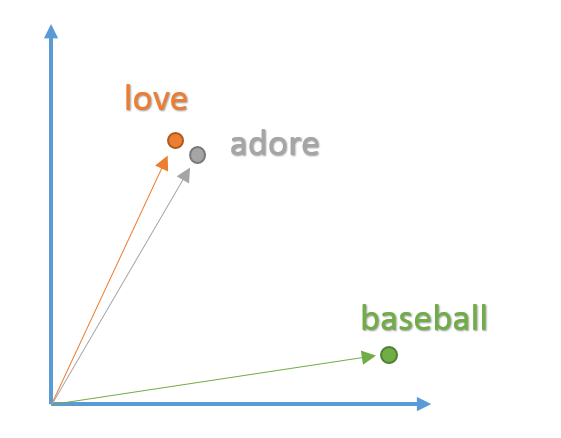
意義相近的單詞其向量在空間中也會更靠近
圖片來源:O'Reilly
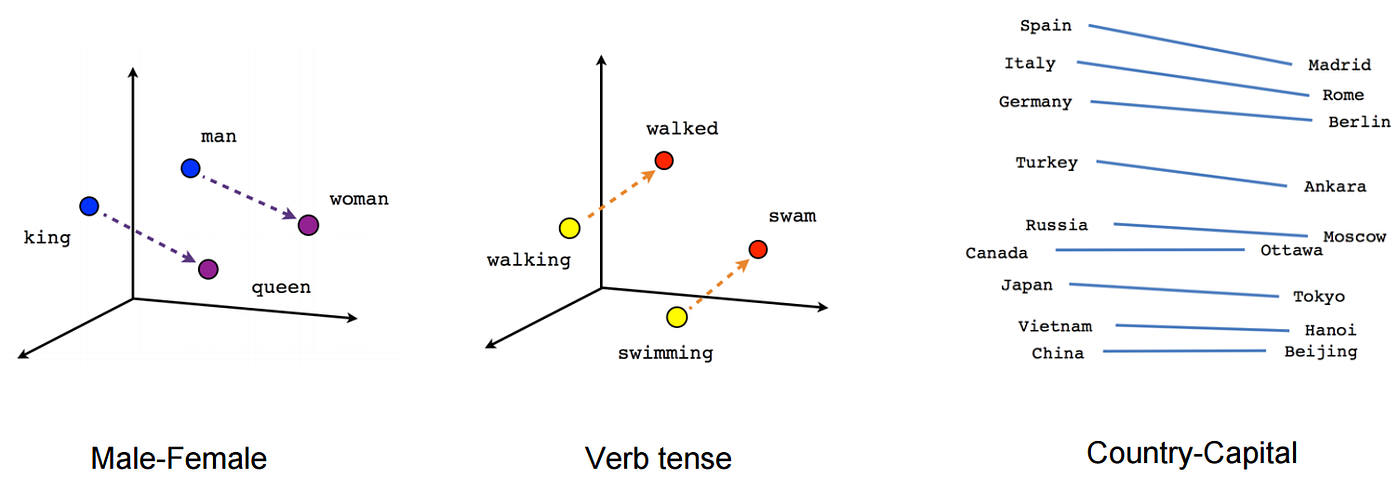
在不同語境中相依與相對單詞的向量分佈
圖片來源:Medium
在深入探討 word embedding 的架構之前,我們使用開源的 Python 套件 spaCy 中已經訓練好的 word embedding models 來進行文字的向量化並檢視其維度。 spaCy 內建了多國語言模型,支援英文、德文、法文等歐洲語言,亦包含中文和日文,甚至提供多語言( multi-language )模型。
spaCy支援多國語言
spaCy 現行版本有四個英文詞嵌入模型,我們選擇最輕量的 en_core_web_sm。
第一步:在終端機下載 spaCy 並安裝模型
$ pip install -U spacy
$ python -m spacy download en_core_web_sm
接著來到 Python 編輯環境,首先引入 spaCy 模組,並載入剛才下載好的語言模型:
import spacy
# Load an English word embedding model
nlp = spacy.load("en_core_web_sm")
重頭戲登場,依照自己的喜好輸入英文字詞,並透過模型的 vector 屬性將單詞表示成向量:
# vector representation of word "python"
python_vec = nlp("python").vector
print("Word Embedding Representation of 'Python': {}".format(python_vec))
檢視一下 python 這個單詞的向量表示: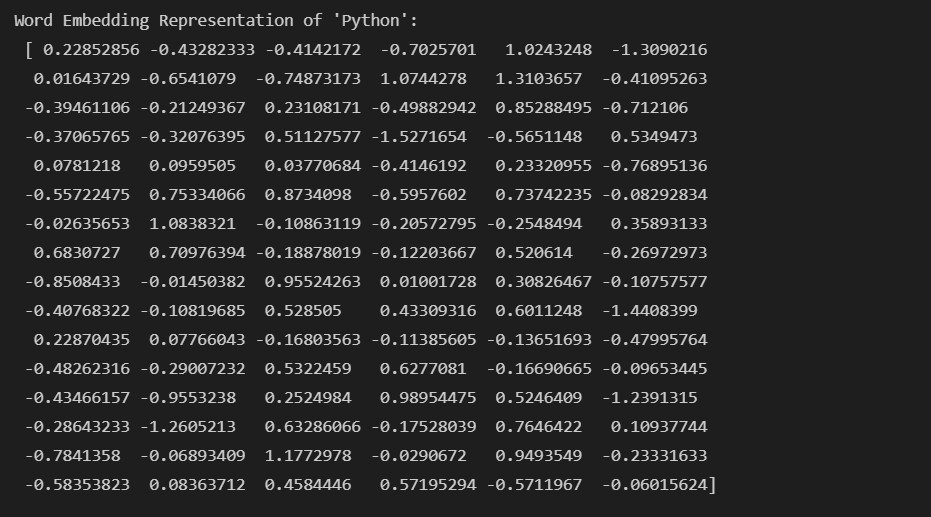
我們好奇向量的維度(不同模型會依照使用的語料庫建構出不同維度的向量空間),可以使用 len(python_vec) 取出向量的維度:
# obtain vector size
vector_length = len(python_vec)
print("We have a {}-dim vector.".format(vector_length)) # We have a 96-dim vector.
Hmmm... 96維的向量!乍看之下維度非常高,但記得, BoW 、 One-Hot Encoding 表示法會因著所需的詞彙增多而使得向量的維度飆漲,所以使用 word embedding 模型已經大幅縮減向量空間的維度了!
講到這裡,我們還沒見識到 word embedding 的真正威力-語意相似度。別急著敲碗,明天將會介紹如何衡量向量之間的距離,敬請期待下一篇,晚安!