今天來用前幾天使用判斷腫瘤良性惡性的例子來執行random forest,一開始我們一樣先建立score function方便之後比較不同models:
#from sklearn.metrics import accuracy_score, confusion_matrix, precision_score, recall_score, f1_score
def score(m, x_train, y_train, x_test, y_test, train=True):
if train:
pred=m.predict(x_train)
print('Train Result:\n')
print(f"Accuracy Score: {accuracy_score(y_train, pred)*100:.2f}%")
print(f"Precision Score: {precision_score(y_train, pred)*100:.2f}%")
1. 1. print(f"Recall Score: {recall_score(y_train, pred)*100:.2f}%")
print(f"F1 score: {f1_score(y_train, pred)*100:.2f}%")
print(f"Confusion Matrix:\n {confusion_matrix(y_train, pred)}")
elif train == False:
pred=m.predict(x_test)
print('Test Result:\n')
print(f"Accuracy Score: {accuracy_score(y_test, pred)*100:.2f}%")
print(f"Precision Score: {precision_score(y_test, pred)*100:.2f}%")
print(f"Recall Score: {recall_score(y_test, pred)*100:.2f}%")
print(f"F1 score: {f1_score(y_test, pred)*100:.2f}%")
print(f"Confusion Matrix:\n {confusion_matrix(y_test, pred)}")
在random forest的模型裡,重要的參數包括:
隨後我們先來建一個最簡單的random forest,並看看testing後的結果:
from sklearn.ensemble import RandomForestClassifier
forest = RandomForestClassifier(n_estimators=1000, random_state= 42)
forest = forest.fit(x_train,y_train)
score(forest, x_train, y_train, x_test, y_test, train=False)

接下來試試看tuning,這裡我們用cross validation來尋找最適合的參數組合,使用的function為RandomizedSearchCV,可以把想要調整的參數們各自設定區間,接下來會隨機在這些區間裡選出參數組合去建模,用cross validation來衡量結果並回傳最好的參數組合,RandomizedSearchCV重要的參數有:
from sklearn.model_selection import RandomizedSearchCV
#建立參數的各自區間
n_estimators = [int(x) for x in np.linspace(start=200, stop=2000, num=10)]
max_features = ['auto', 'sqrt']
max_depth = [int(x) for x in np.linspace(10, 110, num=11)]
max_depth.append(None)
min_samples_split = [2, 5, 10]
min_samples_leaf = [1, 2, 4]
bootstrap = [True, False]
random_grid = {'n_estimators': n_estimators, 'max_features': max_features,
'max_depth': max_depth, 'min_samples_split': min_samples_split,
'min_samples_leaf': min_samples_leaf, 'bootstrap': bootstrap}
random_grid

forest2 = RandomForestClassifier(random_state=42)
rf_random = RandomizedSearchCV(estimator = forest2, param_distributions=random_grid,
n_iter=100, cv=3, verbose=2, random_state=42, n_jobs=-1)
rf_random.fit(x_train,y_train)
rf_random.best_params_

接下來使用回傳的參數組合來建最後的model囉!
forest3 = RandomForestClassifier(bootstrap=True,
max_depth=20,
max_features='sqrt',
min_samples_leaf=2,
min_samples_split=2,
n_estimators=1200)
forest3 = forest3.fit(x_train, y_train)
score(forest3, x_train, y_train, x_test, y_test, train=False)
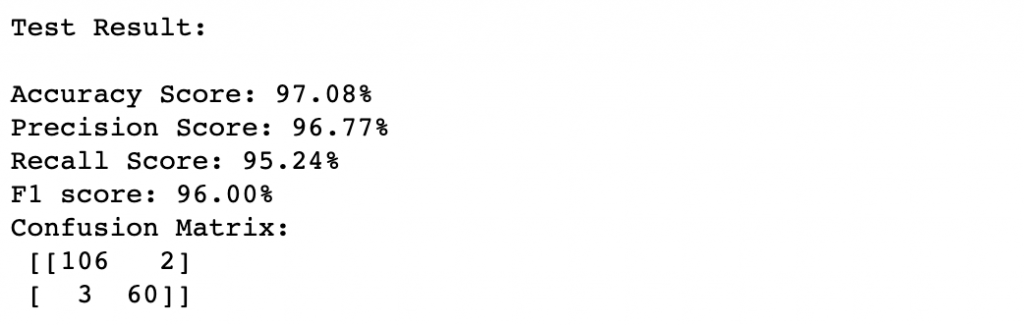
比較一下turning前後其實發現結果相差不大,我們可以再調整參數區間重複嘗試,但這裡想要說的是:很多時候比起去不停調整model參數,在建立model之前的feature engineering以及EDA過程,通常會對model表現帶來更大的影響呦!


 iThome鐵人賽
iThome鐵人賽