經驗不夠,讀書來湊。
除非你的實戰經驗超級豐富,不然在面試時一定會遇到不熟悉的議題;面對無法回答的問題,我個人會老實向面試官表明自己沒有這方面的經驗,會持續學習,瞎掰答案容易讓對方覺得你以後進來公司也會這樣做事。
不過有些議題雖然實際碰過的人不多,但網路上有很多資源可以學習;如果剛好有研究過相關資料,筆者會回答:「雖然沒有在工作上使用過,但在下班後我有特別研究這個議題,如果思路上有不對的部分還請各位面試官批評指教。」
面對高流量的的系統,會採取哪些措施?
回答問題所需具備的知識
衍伸問題
如果面試的公司在做金融、電商、社交、媒體的系統,那這題算是該職缺所需具備的技術;儘管也可以透過後天培養,但如果有現成的人才,誰會想要花時間做訓練。
前後端我會用 Load Balance 緩解 Server 的壓力;在資料庫方面則採取主從式架構、讀寫分離來降低壓力。
如果經過上面的設計後,資料庫還是無法負荷,可以先用業務種類作為切分條件;以電商系統來說我會先做垂直切分(vertical-partition),像是將商品、訂單、明細拆成 3 個資料庫,以此大幅降低單一資料庫被存取的流量。
如果垂直切分後還是在某個資料庫遇到瓶頸,像是訂單的的資料庫內容遠大於其他資料庫;此時會再做水平切分(horizontal-partition),可能會依照訂單的地區再切分成幾個資料庫。
無論是電商還是媒體的系統,幾乎長時間都要面臨大流量的議題,想當然一台伺服器是無法承受高流量的。
而負載平衡(Load Balance)就是為了解決這個問題而誕生的,既然 1 台 Server 無法承受 10 萬流量;那我們就用 100 台 Server 來分散流量吧!
早期做法是先預估流量,然後開啟對應數量的 Server 來作分流;這樣的做法多開頂多浪費錢,但如果估計錯誤少開就可能導致系統當機。
所以像是 GCP、AWS 這類雲端廠商所提供的負載平衡(Load Balance),就有依照伺服器健康程度來做自動擴展(auto-scaling)的服務,讓大家不需要去猜要開多少台才合適;如果有使用 Kubernetes 並設定好相關參數,在遇到大流量時也會自動擴展 Pod 來應付。
有時會被問到你的系統過去遇到最高的 QPS 是多少,QPS 指的是每秒查詢率(Queries Per Second)。
上面提到的負載平衡只能做到讓網頁成功打開,如果資料庫 Server 沒有做對應的設計,這樣的大流量跟 DDOS 根本沒兩樣,足以讓資料庫 Server 陣亡;所以有時會發現進入某個網站後可以看到 UI 佈局,卻沒有資料顯示。
下面我們先探討主從式架構,目標是先讓資料庫 Server 能承受大流量的檢索,接著再來考慮寫入問題。
為什麼需要 Master Slave Replication 的架構?
無論哪個時段都會被大量檢索,如果資料庫只用一個 Server 來處理會無法負荷高流量。資料分析部門,他們也會隨時監控資料庫的變化來產生報表,但如果跟一般使用者一樣 query 同一台 Server,會使這台 Server 增加不必要的負荷,甚至導致使用者體驗下降。Master Slave Replication 為什麼能夠解決這些問題?
Master 負責資料寫入,Slave 提供資料檢索;這樣就把壓力分散到幾台 Server 上面。分散 Server 壓力外,資料也獲得了備份。Master Slave Replication 的架構
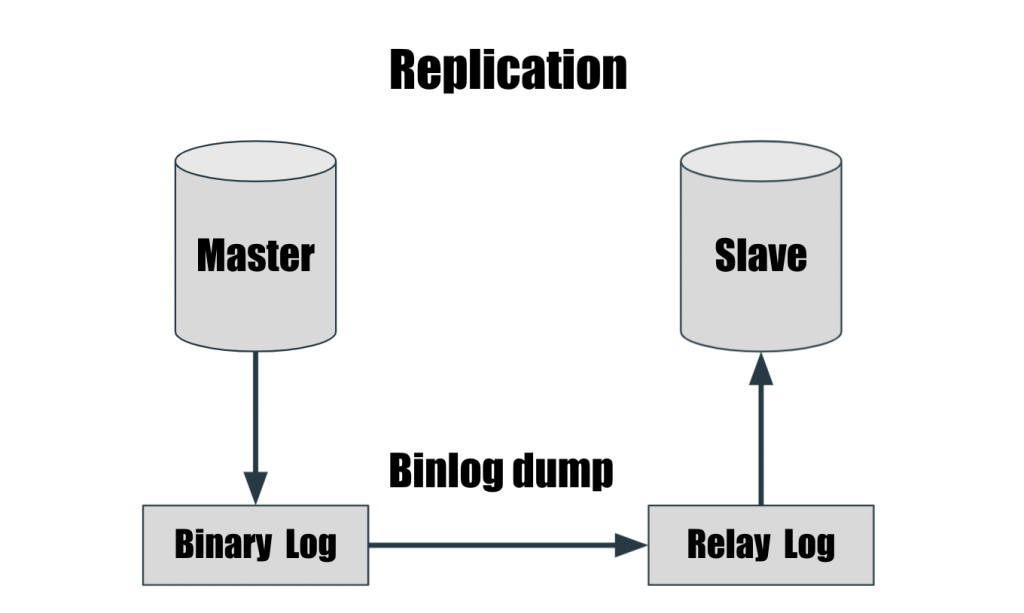
Relay Log 與 Binary Log 檔案格式、內容都一樣,不同在於 Slave 在執行完 Relay Log 的 SQL 之後,會自己刪除當前的 Relay Log。
我們知道 Master Server 是用來更新資料,Slave Server 是用來檢索資料;但它們都是獨立的 ip,使用者在存取資料庫的時候並不知道要使用哪一台 Server ,除非你的 Slave Server 只用來做資料分析。
因此我們要在中間設計一台 Proxy Server,準確地將 SQL 指令分流到正確的 Server。
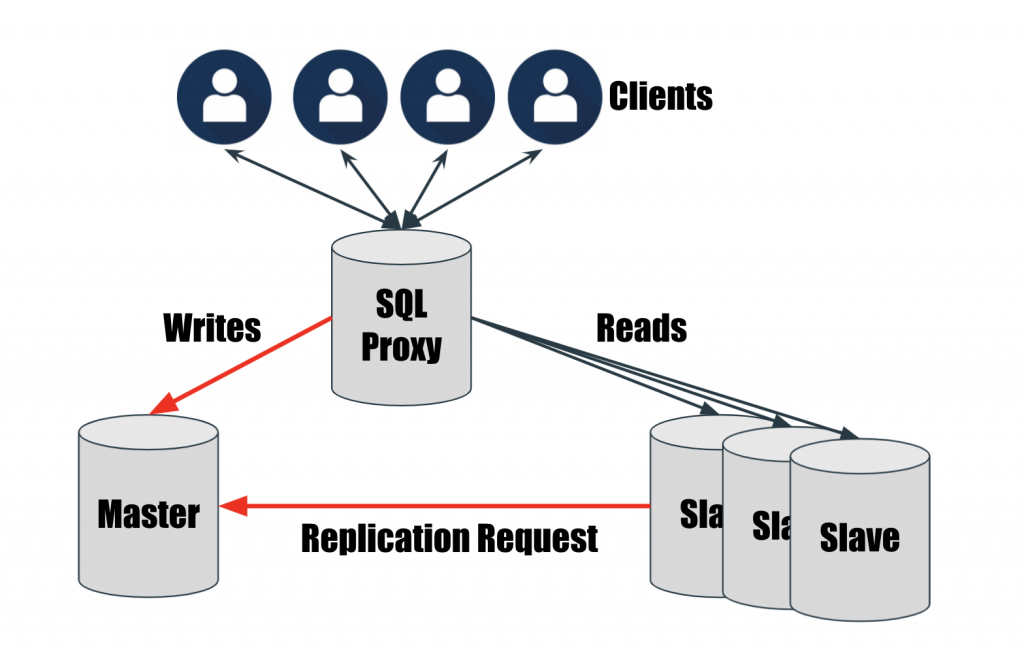
媒體類型的平台在讀的需求很高,寫的需求相對低;因此多會採用主從式架構做讀寫分離。
在讀寫分離後,儘管讀的部分沒有問題;但把寫入的工作交給一個資料庫負責還是會遇到瓶頸。
此時資料庫的垂直切分(vertical-partition)就派上用場了;以商城舉例,商品、訂單、付款明細各自的業務量都很大,所以我們可以先依照業務性質把它拆分成 3 個資料庫,如此設計可以分散資料庫被存取的流量,來提升系統穩定度。
在垂直切分後,有些資料庫還是會遇到瓶頸,像是訂單的資料庫可能遠遠大於其他資料庫。
這時我們就會需要做水平切分(horizontal-partition),將 DB 中同一類型的資料依據特定邏輯拆分成多個 DB;像是訂單可能來自於世界各地,所以我們可能就以地區(ex:亞洲、歐洲、美洲...)做切分的邏輯。
資料庫在經歷了垂直切分與水平切分後,寫入遇到的瓶頸就差不多解決了。
但接下來會遇到另外一個問題,Table 中的資料會隨著時間會不斷增長,如果資料量龐大到就算建立 Index 都無法提升效能;此時就要考慮將 Table 依照特定邏輯做切割,通常會選擇自動產生的 id、日期這類的欄位作為切割依據,在 Table 被切割後因為資料量變少,所以搜尋效能隨之提升。
特別提醒:如果這個 Table 有 Primary key 或是 Unique key,分區鍵(Partition Key)必須是 Primary key 或是 Unique key 組成的一個部分。
考點:瞭解求職者的實務經驗
當時我使用的是 MySQL 資料庫,用 sysbench 這個測試工具模擬短時間執行大量的 SQL command(ex:Table 內容大量更新、Index 建立);但去 Slave 的資料庫確認同步狀況時,卻發現並沒有完全同步 Master 的資料。
經過研究後發現 MySQL 預設的 Process 只有一個,因此累積了很多尚未同步的 SQL Command;將 MySQL 調整成多 Process後,Slave同步的效率就大幅提升了。
可透過修改「slave_parallel_type、slave_parallel_workers」這兩個變數來調整 Process數量。
考點:對分散式資料庫的認知程度
分擔流量,在 Master 資料庫發生問題也可以讓其他 Slave 資料庫轉成 Master,不影響整體系統。紙上得來終覺淺,絕知此事要躬行。 ── 陸游
如果大家想要親手實作今天的面試題,在參考資源中有分享一些實作流程喔!
感謝大家的閱讀,如果喜歡我的文章可以訂閱接收通知;如果有幫助到你,按Like可以讓我更有寫文的動力,我們明天見~
我在 Medium 平台 也分享了許多技術文章
❝ 主題涵蓋「MIS & DEVOPS、資料庫、前端、後端、MICROSFT 365、GOOGLE 雲端應用、自我修煉」希望可以幫助遇到相同問題、想自我成長的人。❞
在許多人的幫助下,本系列文章已成功出版,除了添加新的篇章,更完善了每個案例的應對進退;如果對現在的職涯感到迷茫,也許這本書能帶給你不一樣的觀點~


