昨天體驗到 Automated ML 的威力了,它可以自動地幫我們跑一大堆模型,找出最好的解法,省下一大堆時間,真的是資料科學家的神器。
今天我們就來把昨天找到的最佳解,給部署起來吧!
不過大家要注意一點是,AutoML找出來的最佳解,不一定是可以直接 production 的,建議還是要再測試過。
回到我們昨天 Automated ML,這個 experiment,點擊下面的 Run 1 進去。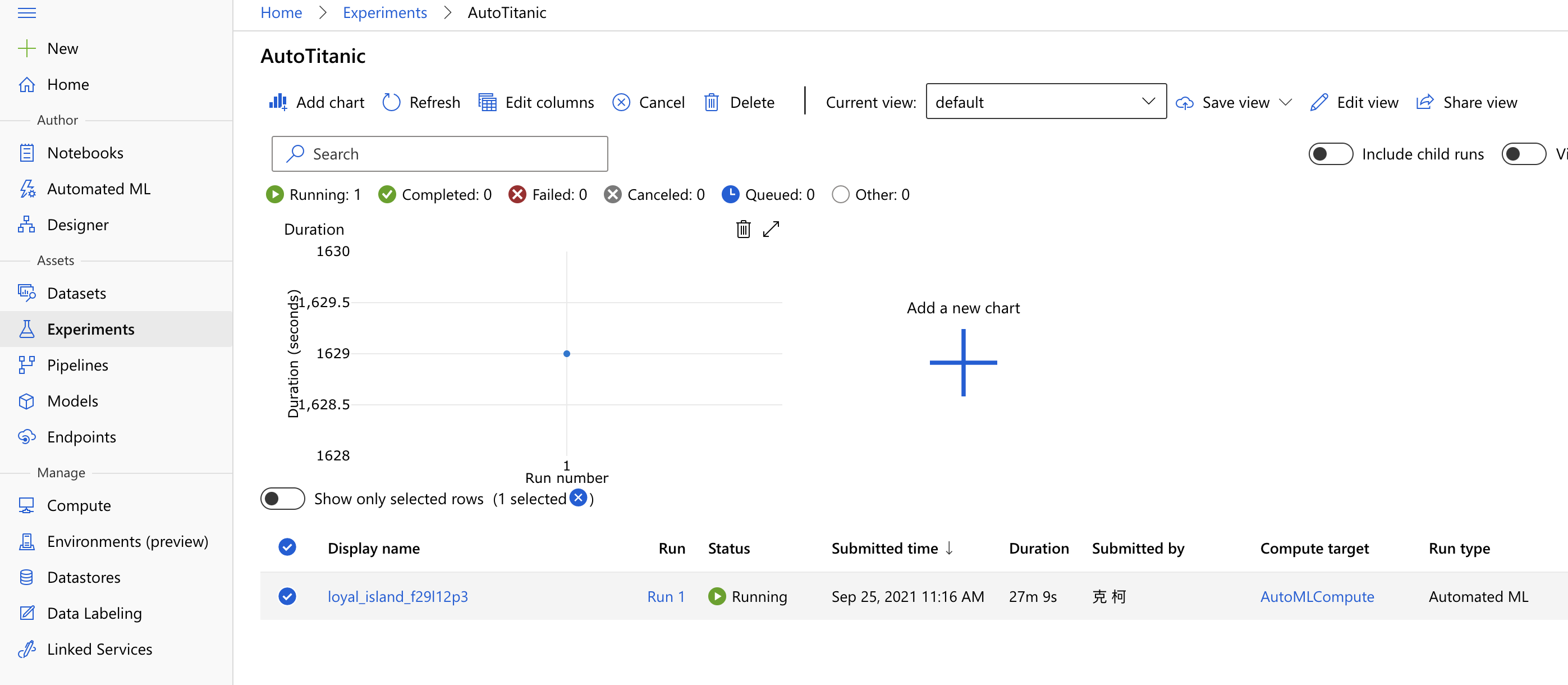
進到 Run 裡面後,我們點選上面的 Models,點擊你想要部署的那個 Model 進去。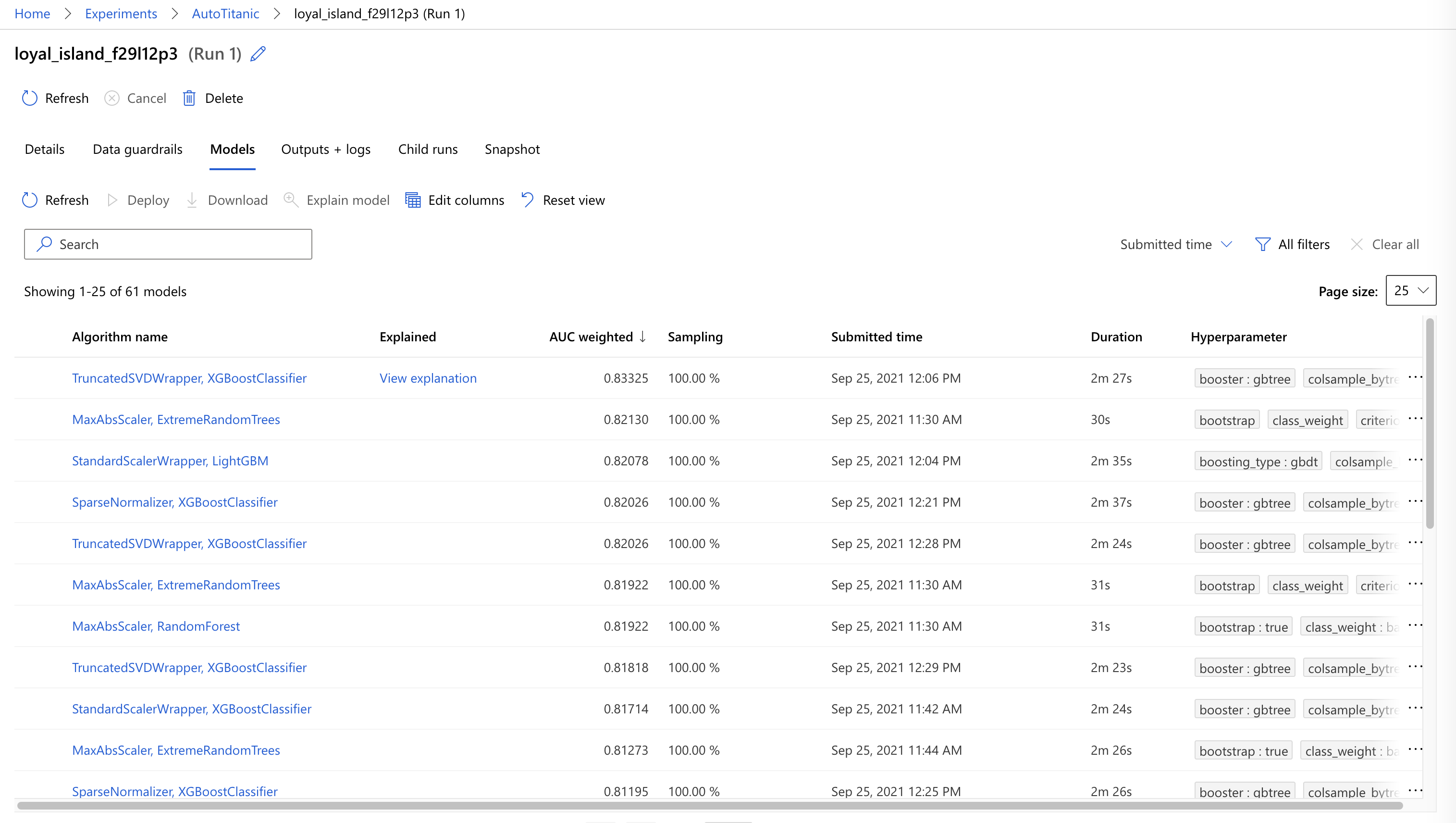
進去 Model 裡面後,如下圖所示會看到上方有個 Deploy 的按鈕,我們點下去。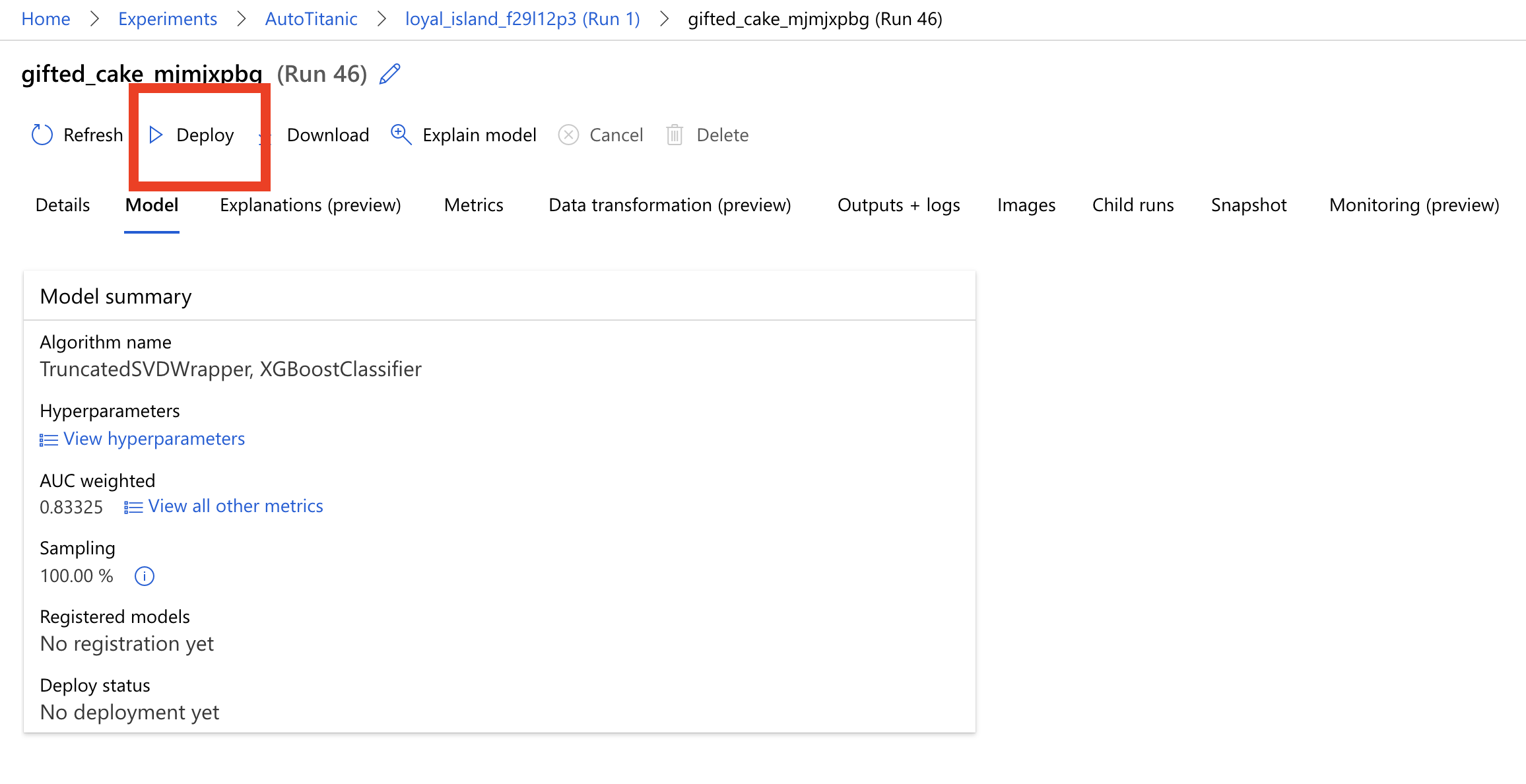
接著會跳出一個視窗,我們依序填入名稱、描述、選擇 AKS 和之前我們開好的那個 Inference Compute。
在 Authentication 這裡,我們給它啟用,然後看你要用什麼方式來做 authenticate,這裡我們選 key-based。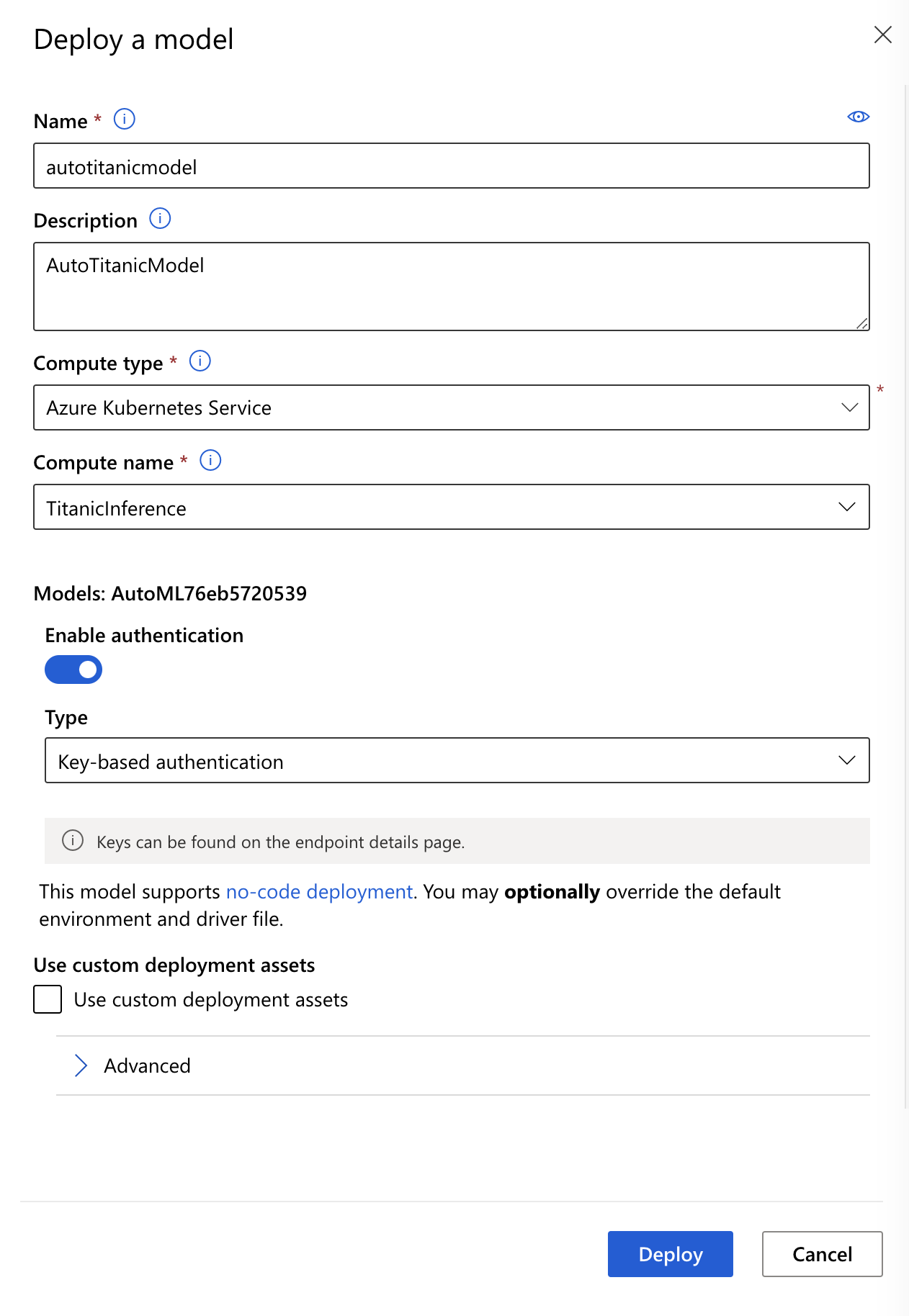
等待一段時間就會部署完成了。這時候我們點左邊選單的 Endpoints,進到我們剛剛部署上去的 endpoint 裡面。在 Details 的頁簽裡,我們可以看到這個 endpoint 的一些基本資訊,包含了 REST API 的網址。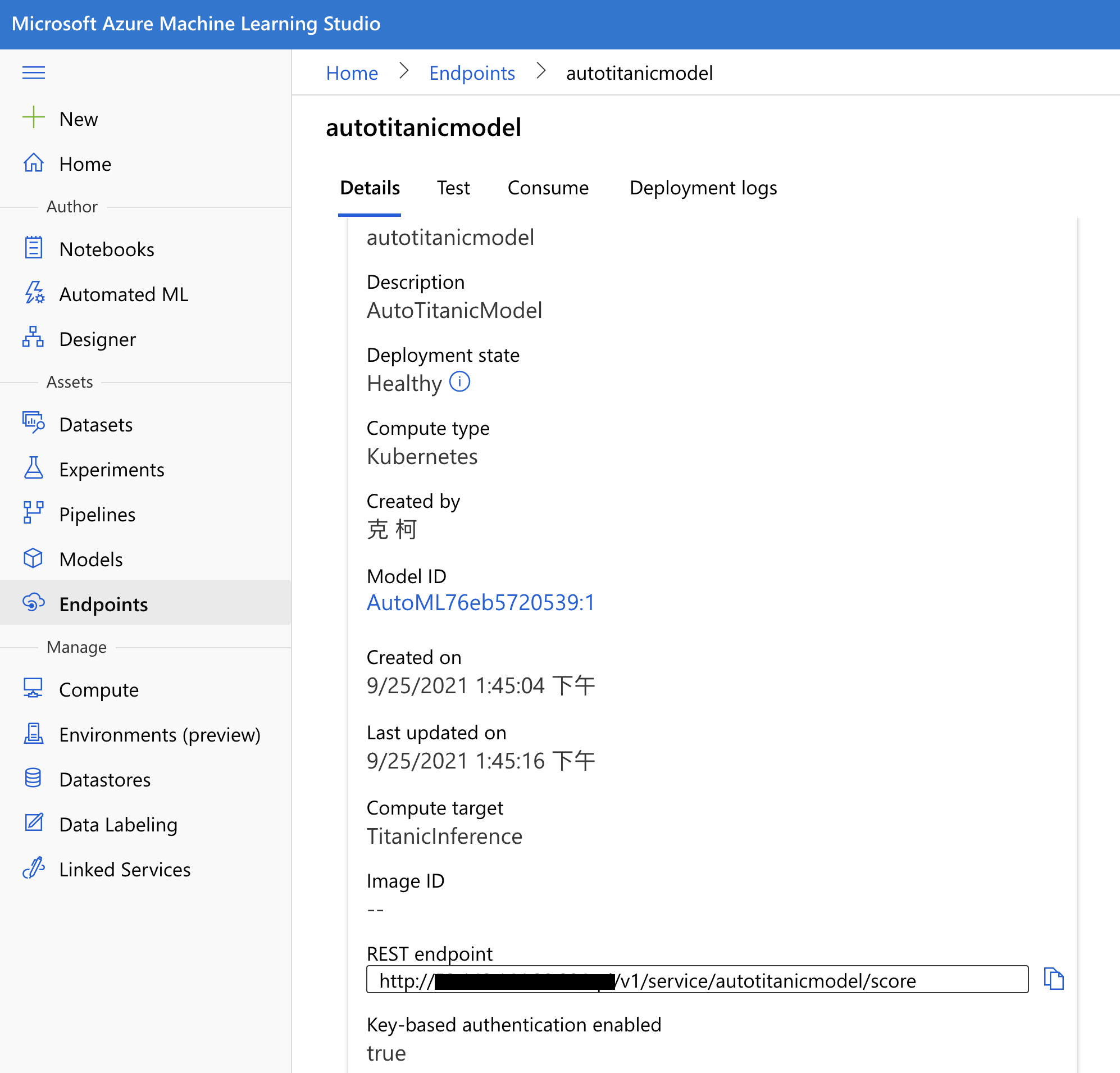
再來我們點到 Test 那個分頁,有圖形化介面可以來測試這個 API。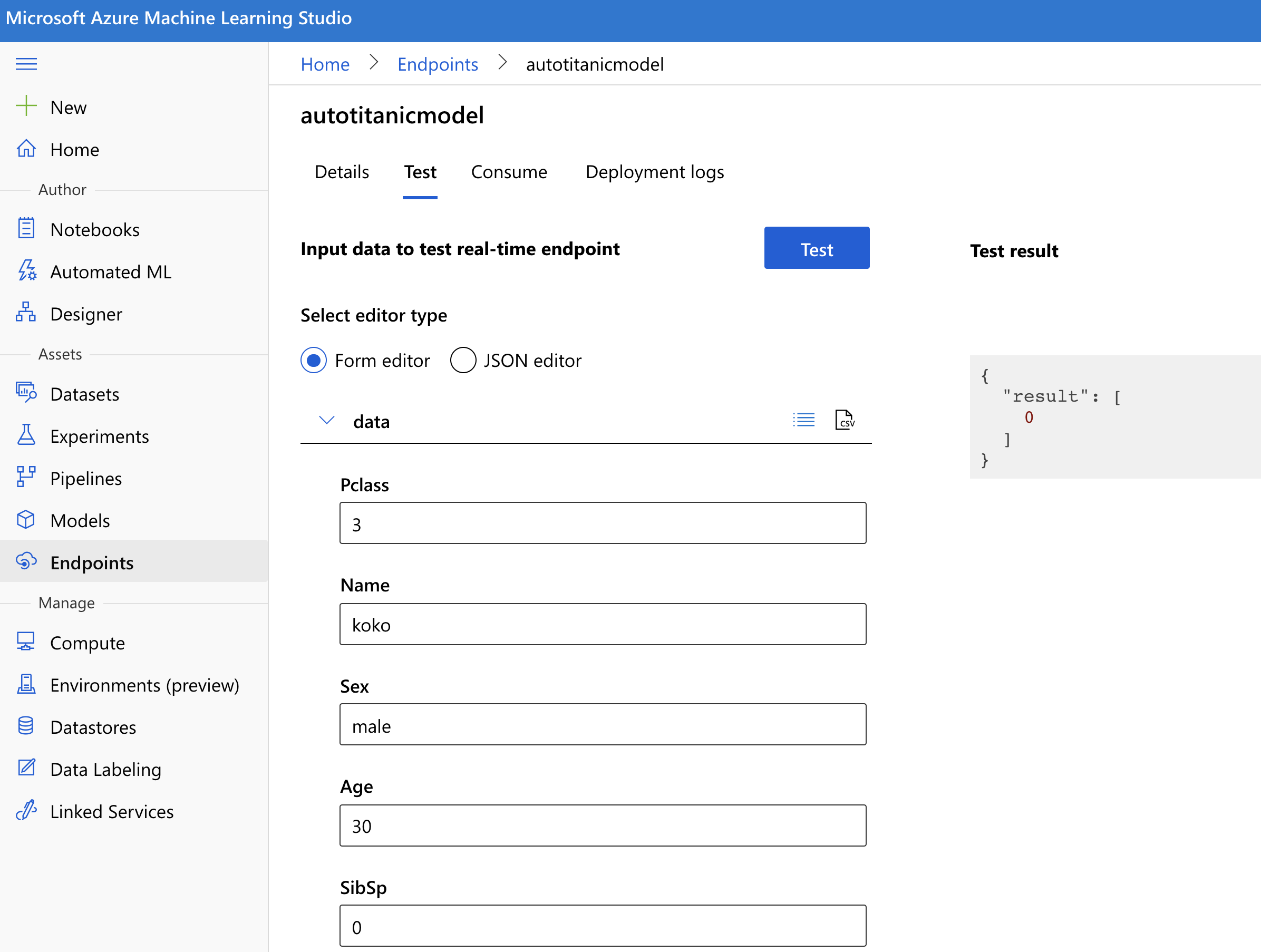
接著我們進到 Consume 這個頁面,一如以往地,連怎麼使用這個 API 的程式碼都幫你生產好啦!!剛剛我們做的 key-based authentication 的 Key,在放在這裡哦!
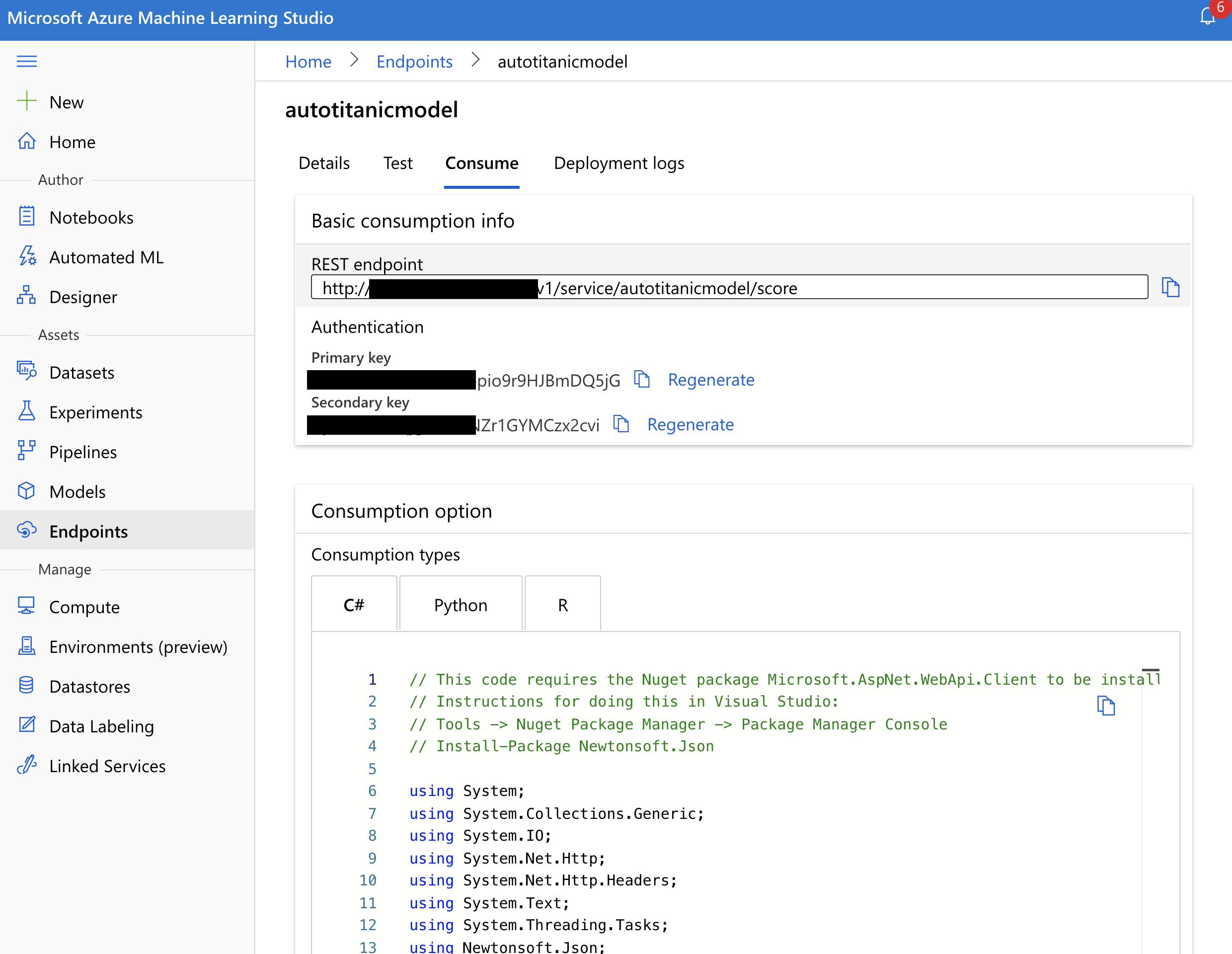
到這裡為止我們就完成了 Automated ML 的部署,真的是非常地容易呢!有沒有愈來愈喜歡 Azure Machine Learning 呢?
做到這兒我經常做不下去, 因為都出現 error,內容如下
Deployment request failed due to insufficient compute resource. For the specified compute target, 1 replica cannot be created per specified CPU/Memory configuration(1.8 CPU Cores, 7GB Memory). You can address this problem by adjusting number of replicas, using a different CPU/memory configuration, or using a different compute target
是不是資源不夠?要如何才能知道所選的 model 需要用多少資源呢?
應該不可能碰運氣吧
請問部署到最後的 endpoint 時出現以下 error,可以怎解決?
There are no backend pods available for this service. No logs could be retrieved.

