昨天我們實驗了有無做 Normalization 的差異,但我在 stackoverflow 剛好看到一篇精彩的討論,主要爭論的點是我應該把圖片 Normalization 到 [0,+1] 還是 [-1,+1] 的討論,把數值縮放到 [-1,+1] 的原因有這麼做平均值接近0且標準差接近1,其中有個討論是如果範圍有負值,那會不會受到 relu 的影響,導致大部分的數值變成0呢?
這部分是不需要擔心的,因為我們的 activation 會在CNN或Dense之後,所以原先 input 是負值是有機會乘上權重後變成正值的(即權重也是負值,負負得正),因此不必擔心此問題。
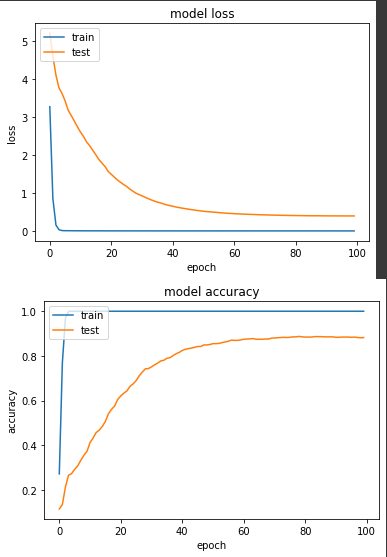
實驗一:老樣子將範圍縮到 [0,+1]
def normalize_img(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, (224,224))
return image /255., label. # [0, +1]
ds_train = train_split.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_train = ds_train.cache()
ds_train = ds_train.shuffle(SHUFFLE_SIZE)
ds_train = ds_train.batch(BATCH_SIZE)
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)
ds_test = test_split.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_test = ds_test.batch(BATCH_SIZE)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.experimental.AUTOTUNE)
base = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights='imagenet')
net = tf.keras.layers.GlobalAveragePooling2D()(base.output)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[base.input], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
產出:
loss: 3.6361e-04 - sparse_categorical_accuracy: 1.0000 - val_loss: 0.3945 - val_sparse_categorical_accuracy: 0.8824
實驗二:範圍縮到 [-1, +1]
def normalize_img(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, (224,224))
return (image - 127.5) / 127.5, label
ds_train = train_split.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_train = ds_train.cache()
ds_train = ds_train.shuffle(SHUFFLE_SIZE)
ds_train = ds_train.batch(BATCH_SIZE)
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)
ds_test = test_split.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_test = ds_test.batch(BATCH_SIZE)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.experimental.AUTOTUNE)
base = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights='imagenet')
net = tf.keras.layers.GlobalAveragePooling2D()(base.output)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[base.input], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
start = timeit.default_timer()
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
產出:
loss: 4.3770e-04 - sparse_categorical_accuracy: 1.0000 - val_loss: 0.4737 - val_sparse_categorical_accuracy: 0.8735
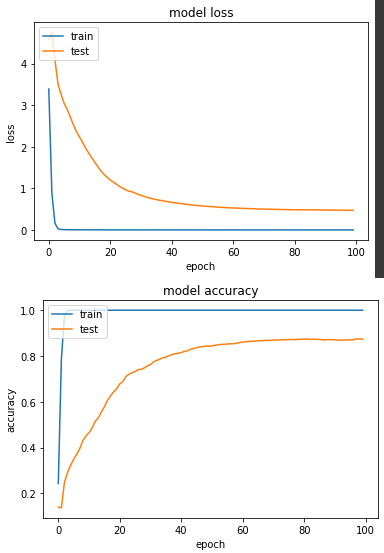
從結論來看,[0,1] 得準確度比 [-1,+1] 來得高一點點,以我自己的實務經驗來說,我普遍都是縮成[-1,+1],但也看過不少開源程式碼是[0,1],故兩者無多大區別。

