普遍我們拿來訓練的圖片都是RGB,普遍都是機器學習的CNN層找到一些局部特徵來做分類,這些局部特徵對我們人來說,即使是轉成視覺化的特徵值,依然是個謎,既然這樣子,如果我們把圖片轉成HSV,機器一樣能夠完成任務嗎?畢竟對於機器來說,這些像素都是數值。
第二個問題是,其實我們今天把某些照片轉成灰階照片,我們仍然可以一眼看出圖片代表什麼(比如貓狗照片轉成灰階,你仍然可以認得哪張是貓哪張是狗),那在機器學習任務時,我們是不是也能夠教機器學習灰階圖片呢?這樣子訓練出來的模型和原先的RGB模型又會有什麼樣的差別呢?這就是我們今天要來實驗的主題。
在進行訓練之前,我們先來看看 tf.image.* 提供了哪些API供我們使用,很剛好地,轉成HSV和灰階都剛好有做好的API可以用。
import cv2
from google.colab.patches import cv2_imshow
def convert_img(image, label):
image = tf.cast(image, tf.float32)
normal = image / 255.
hsv = tf.image.rgb_to_hsv(normal)
hsv = hsv * 255.
gray = tf.image.rgb_to_grayscale(image)
return image, hsv, gray
ds_train = train_split.map(
convert_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
為了確保我們使用 Tensorflow API 轉換是正確的,我另外寫了和 OpenCV 轉換的對照版本,來實測轉換是否一致。
首先是 tf.image.rgb_to_hsv,一般我們圖片讀近來是 uint8 的格式,數值落在 [0, 255],但根據 tensorflow 官方文檔,我們發現
The output is only well defined if the value in images are in [0,1]
輸入的 image 必須是 [0,+1] 的範圍,所以一開始我們必須先將 image / 255. ,轉完 hsv 之後,再乘上 255. 變回去 uint8 的數值。
而 tf.image.rgb_to_grayscale ,相對簡單,原先的 uint8 就可以直接讀進來。
for example in ds_train.take(2):
ex = example
origin = cv2.cvtColor(example[0].numpy().astype(np.uint8), cv2.COLOR_RGB2BGR)
hsv = example[1].numpy().astype(np.uint8)
gray = example[2].numpy().astype(np.uint8)
print('Origin:')
cv2_imshow(origin)
print('\nOpenCV HSV:')
cv2_imshow(cv2.cvtColor(origin, cv2.COLOR_BGR2HSV))
print('\nTF HSV:')
cv2_imshow(hsv)
print('\nOpenCV Gray:')
cv2_imshow(cv2.cvtColor(origin, cv2.COLOR_BGR2GRAY))
print('\nTF Gray:')
cv2_imshow(gray)
我們來看看和 OpenCV 的差異:
原圖:
OpenCV 的 HSV:
TF 的 HSV:
發現這兩者轉換的數值還是有些微的差異,但後面的訓練仍用 tensorflow 轉換即可,我們只想知道訓練最後的 loss 和準確度。
OpenCV 的 灰階:
TF 的 灰階:
兩者並無太大差異,灰階轉換是OK的。
實驗一:使用經過HSV轉換的圖片來訓練
def normalize_img(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, (224,224))
image = image / 255.
image = tf.image.rgb_to_hsv(image)
return image, label
ds_train = train_split.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_train = ds_train.cache()
ds_train = ds_train.shuffle(SHUFFLE_SIZE)
ds_train = ds_train.batch(BATCH_SIZE)
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)
ds_test = test_split.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_test = ds_test.batch(BATCH_SIZE)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.experimental.AUTOTUNE)
base = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights='imagenet')
net = tf.keras.layers.GlobalAveragePooling2D()(base.output)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[base.input], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
產出:
loss: 4.5527e-04 - sparse_categorical_accuracy: 1.0000 - val_loss: 0.9874 - val_sparse_categorical_accuracy: 0.7402
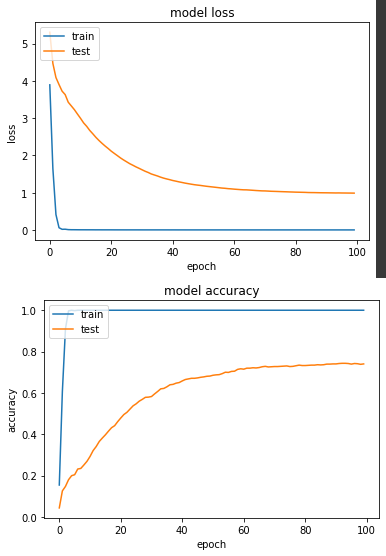
實驗二:使用經過灰階轉換的圖片來訓練
def normalize_img(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, (224,224))
image = tf.image.rgb_to_grayscale(image)
image = tf.repeat(image, 3, axis=2) # mobilenet input channel is 3
return image / 255., label
ds_train = train_split.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_train = ds_train.cache()
ds_train = ds_train.shuffle(SHUFFLE_SIZE)
ds_train = ds_train.batch(BATCH_SIZE)
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)
ds_test = test_split.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_test = ds_test.batch(BATCH_SIZE)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.experimental.AUTOTUNE)
base = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights='imagenet')
net = tf.keras.layers.GlobalAveragePooling2D()(base.output)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[base.input], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
start = timeit.default_timer()
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
這邊有個比較麻煩的地方是,原先 mobilenetV2 輸入的 channel 是3個,但是灰階 channel 只有1,所以我透過 tf.repeat 複製成3個 channel,為了不變動模型這樣做其實有點冗贅。
產出:
loss: 4.2608e-04 - sparse_categorical_accuracy: 1.0000 - val_loss: 0.8360 - val_sparse_categorical_accuracy: 0.7931
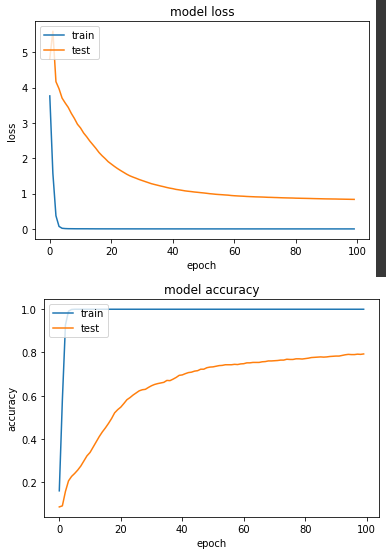
HSV的準確度和灰階的準確度分別是74%和79.3%,相較於昨天RGB實驗一的88.2%,看到這樣的結果,想了一下覺得畢竟今天照片呈現的物件是什麼,是由我們人的肉眼根據形狀和顏色等所定義,如果今天這個轉換去除了顏色這個因素,對機器來說就是個差異性很大的事情,今天只是個小實驗滿足我的好奇心,各位在做訓練任務時還是使用RGB吧。

