當我們想要把資料丟進model前,常常會需要把資料標準化,尤其是針對跟距離有關的模型(像是knn, svm等),標準化大概分為standardize和normalize兩種:
standardize:資料點減去平均數在除以標準差,當你覺得資料符合高斯分配時才選擇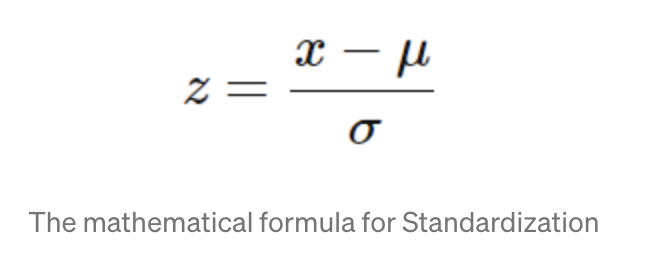
normalize:把資料範圍變為[0,1]間,大部分的標準化都會選擇這個方法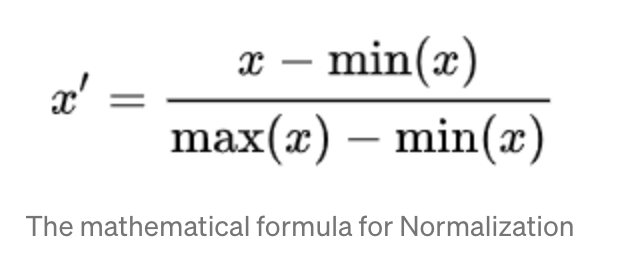
這邊有一個非常重要的觀念想要強調,就是在標準化之前必須要把資料先分割好,也就是對training和testing set分別標準化,不然會有data leakage的問題,data leakage是指訓練模型的過程中用到了training set以外的資訊,如果在未分割前就把所有資料標準化,那數值就會隱含著所有資料的分佈,進而影響模型。
[reference]
https://towardsdatascience.com/normalization-vs-standardization-cb8fe15082eb

