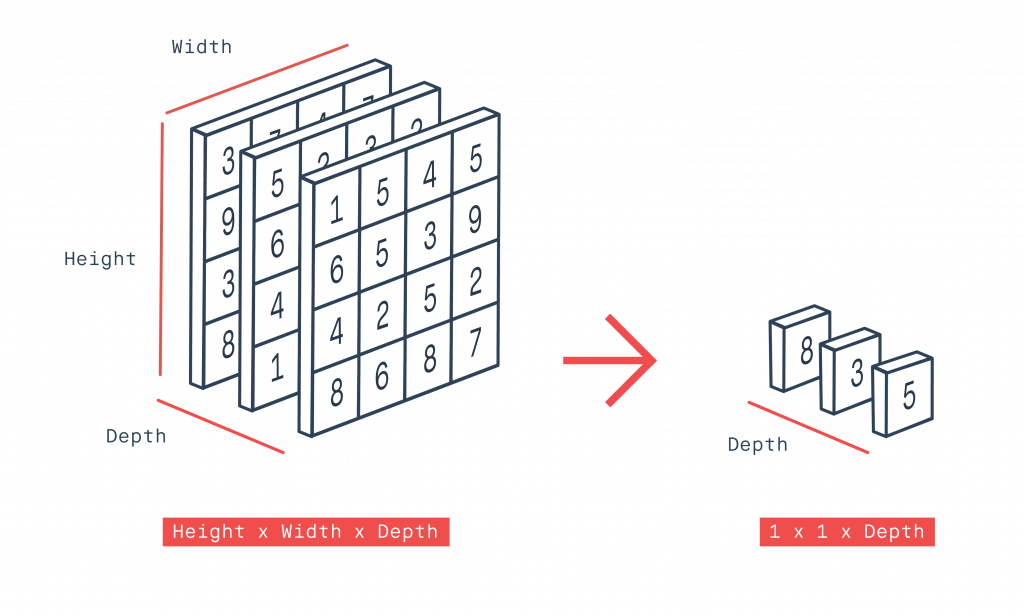
今天要探討的主題在模型從CNN Layer 轉變成 Dense Layer 時,使用 GlobalAveragePooling (GAP) 與 Flatten 兩者之前的差異。
我們假設最後一層CNN的寬高是W和H,通道數是C,那麼通過 GlobalAveragePooling 後,我們會得到W和H都變成1,通道數維持不變(11C),而又因為是GlobalAverage的關係,他是直接以通道為區分,直接裝裡面的權重值做平均。
相反的 Flatten 就簡單很多,它直接寬乘高乘通道(HxWxC),再繼續接上後面的 Dense Layer。了解以上兩個概念後我們就可以來做實驗。
實驗一:GlobalAveragePooling
base = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights='imagenet')
net = tf.keras.layers.GlobalAveragePooling2D()(base.output)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[base.input], outputs=[net])
model.summary()
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
在 model.summary() 中,可以看到經過 GlobalAveragePooling,輸出從 7x7x1280 變成 1x1x1280
out_relu (ReLU) (None, 7, 7, 1280) 0 Conv_1_bn[0][0]
__________________________
global_average_pooling2d_2 (Glo (None, 1280) 0 out_relu[0][0]
產出:
loss: 4.0428e-04 - sparse_categorical_accuracy: 1.0000 - val_loss: 0.4005 - val_sparse_categorical_accuracy: 0.9020
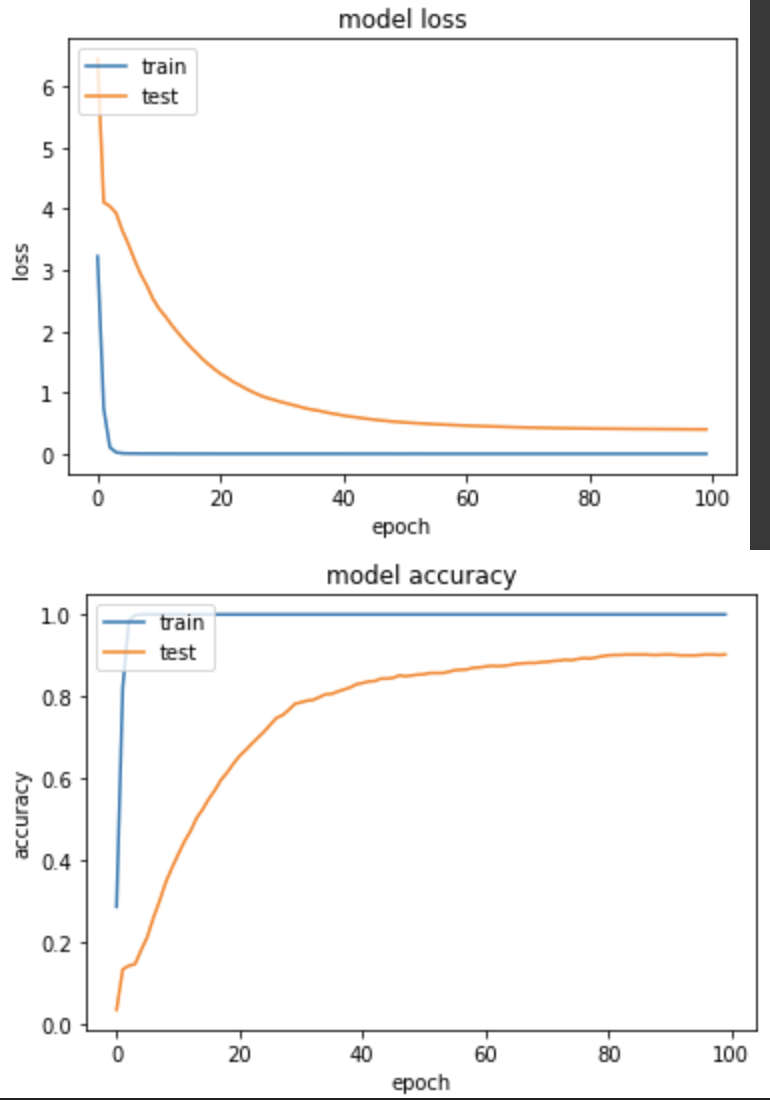
其實這模型前面訓練很多遍了,但這次跑出了準確度90%。
實驗二:Flatten
base = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights='imagenet')
net = tf.keras.layers.Flatten()(base.output)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[base.input], outputs=[net])
model.summary()
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
model.summary() 中,看到經過 Flatten,輸出從 7x7x1280 變成 62720。
out_relu (ReLU) (None, 7, 7, 1280) 0 Conv_1_bn[0][0]
__________________________
flatten_1 (Flatten) (None, 62720) 0 out_relu[0][0]
產出
loss: 0.0063 - sparse_categorical_accuracy: 0.9990 - val_loss: 9.1377 - val_sparse_categorical_accuracy: 0.0833
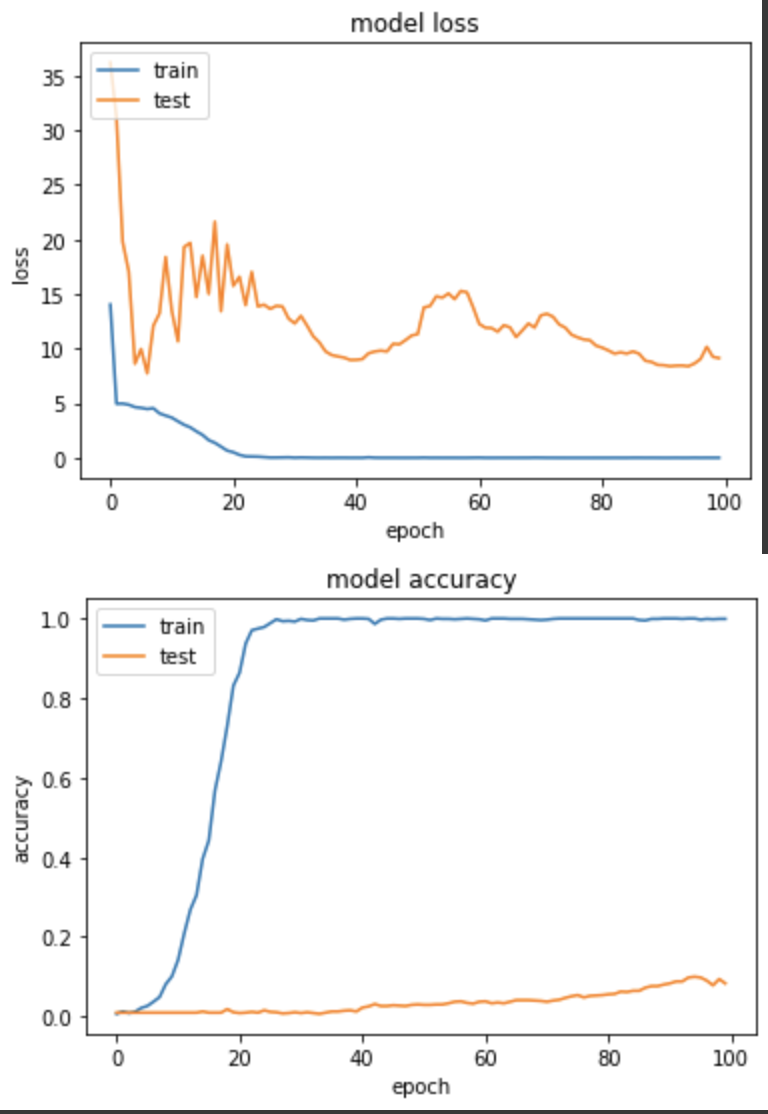
效果不太理想,訓練失敗,由於看到 val_loss 有噴高的現象出現,故我將 LR 降低成0.01後,再次訓練一次 Flatten 的實驗三。
base = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights='imagenet')
net = tf.keras.layers.Flatten()(base.output)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[base.input], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(0.01),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
產出:
loss: 1.4501e-04 - sparse_categorical_accuracy: 1.0000 - val_loss: 1.0266 - val_sparse_categorical_accuracy: 0.7500
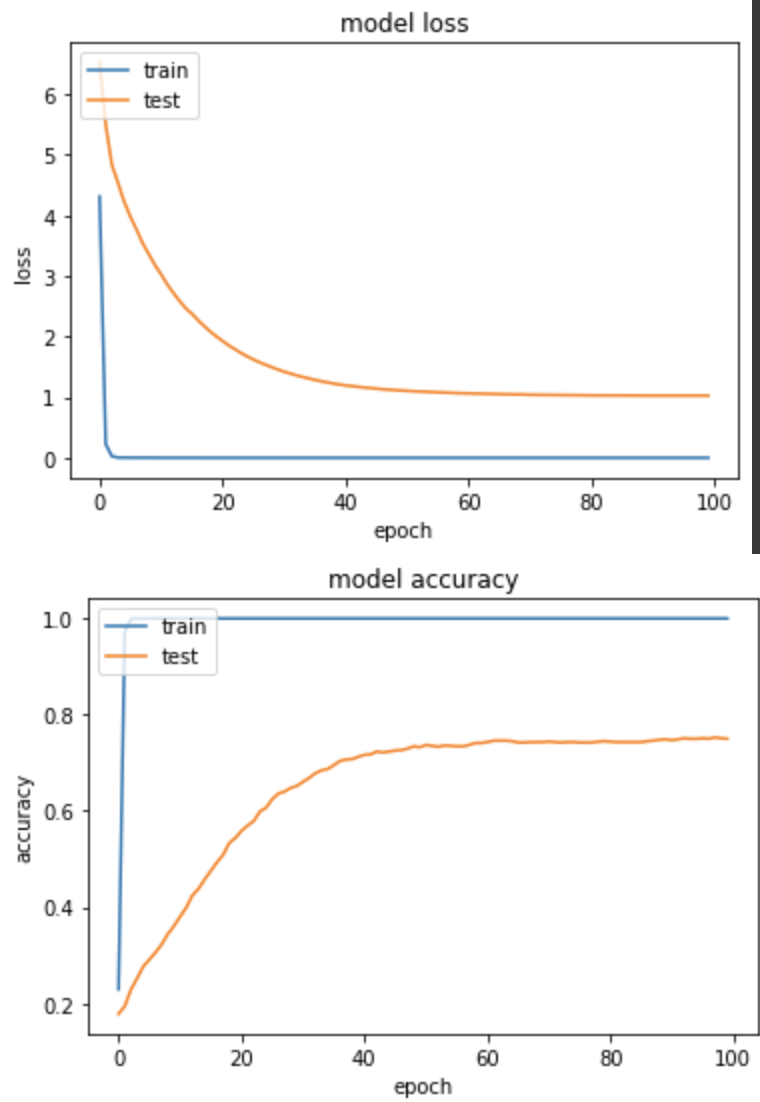
降低 LR 後,模型有效成長,雖然最後準確度仍低於 GlobalAveragePooling,但至少是朝著收斂邁進,我自己在執行訓練任務時,也是以 GlobalAveragePooling 為主。