早期剛學深度學習時,我們 AlexNet 學到了幾個基本的 CNN, Dense, Pooling, Dropout Layers,其中 Pooling 又有 Max 和 Avg 兩種版本,但現代的模型中,我們越來越少看到 Pooling Layer 的存在(Global Pooling 不算),近期取而代之的是將多數的 Layer 盡量利用 CNN 來搞定,這樣既可以降低下採樣(subsampling),同時還多了幾個權重讓模型去學習,當然,這麼做的代價就是預算比較複雜些。
今天要來做的實驗是比較 MaxPooling vs AvgPooling vs Conv 三種用來作為 down sampleing 手段的比較。
資料集我們採用 beans,共有三種分類,辨別葉片的健康狀況。
NUM_OF_CLASS = 3
ds_data, ds_info = tfds.load(
'beans',
shuffle_files=True,
as_supervised=True,
with_info=True,
)
train_split, test_split = ds_data['train'], ds_data['test']
fig = tfds.show_examples(train_split, ds_info)
print(f'number of train: {len(train_split)}')
print(f'number of test: {len(test_split)}')

實驗一,使用 MaxPooling
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, MaxPooling2D, AveragePooling2D, Flatten, Dense
def alexnet_modify_max_pooling():
model = Sequential()
model.add(Conv2D(32, (11, 11), padding='valid', input_shape=(227,227,3)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(3, 3)))
model.add(Conv2D(64, (7, 7), padding='valid'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(3, 3)))
model.add(Conv2D(96, (3, 3), padding='valid'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(3, 3)))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(3, 3)))
model.add(Flatten())
model.add(Dense(128))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dense(64))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dense(NUM_OF_CLASS))
return model
產出:
EPOCH 172/200
loss: 0.0015 - sparse_categorical_accuracy: 1.0000 - val_loss: 0.7871 - val_sparse_categorical_accuracy: 0.8438
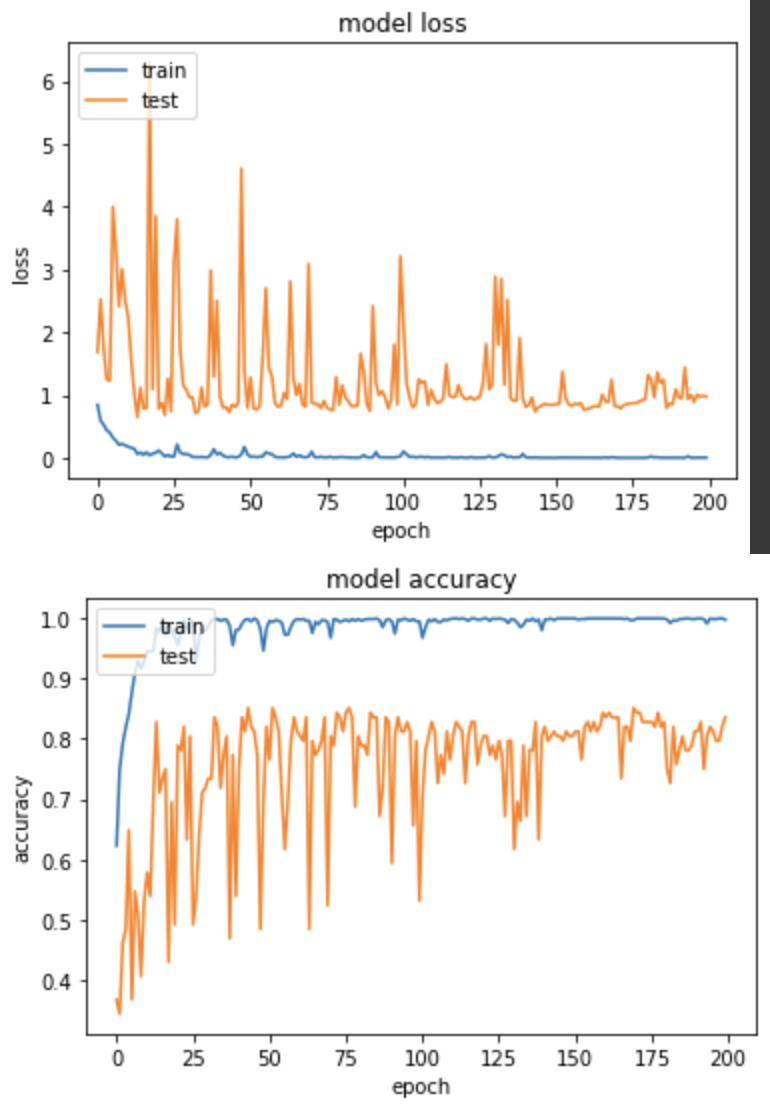
實驗二,使用AvgPooling
def alexnet_modify_avg_pooling():
model = Sequential()
model.add(Conv2D(32, (11, 11), padding='valid', input_shape=(227,227,3)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(AveragePooling2D(pool_size=(3, 3)))
model.add(Conv2D(64, (7, 7), padding='valid'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(AveragePooling2D(pool_size=(3, 3)))
model.add(Conv2D(96, (3, 3), padding='valid'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(AveragePooling2D(pool_size=(3, 3)))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(AveragePooling2D(pool_size=(3, 3)))
model.add(Flatten())
model.add(Dense(128))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dense(64))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dense(NUM_OF_CLASS))
return model
產出:
EPOCH 155/200
loss: 0.0060 - sparse_categorical_accuracy: 0.9990 - val_loss: 0.7398 - val_sparse_categorical_accuracy: 0.8438
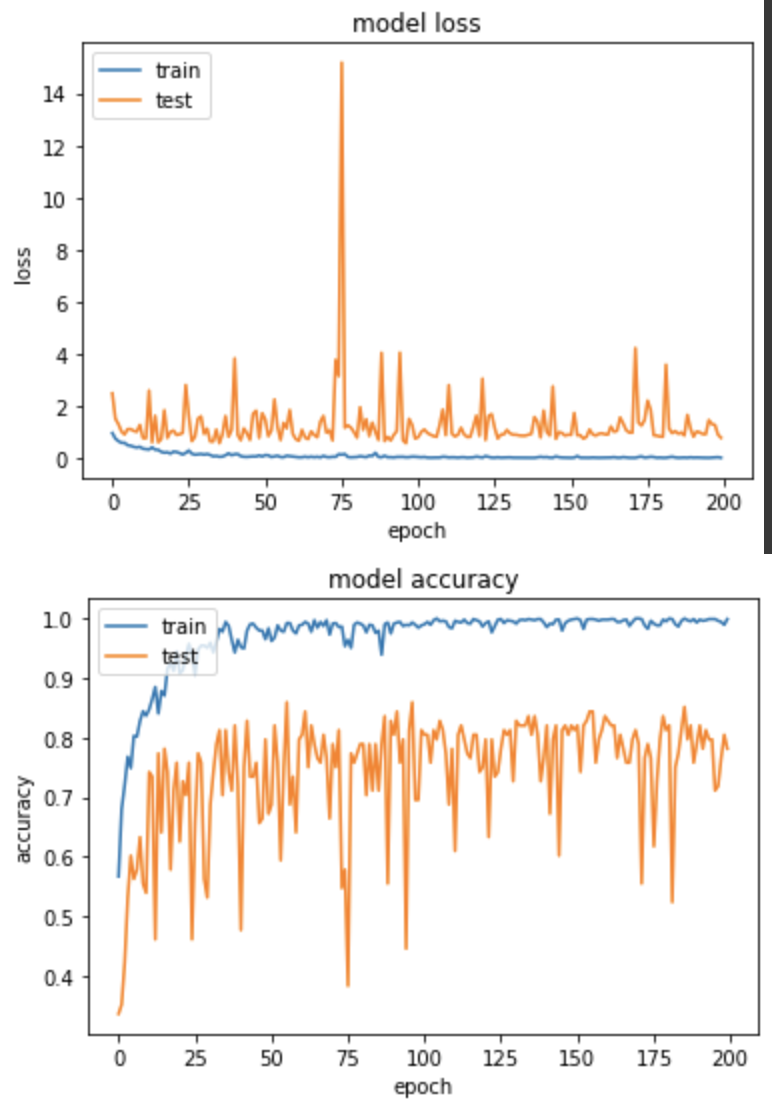
得出的成果和實驗一的 MaxPooling 差不多。但兩者的準確度上升圖表可以看到 MaxPooling 較為穩定,AvgPooling 在中後期準確度仍有低至50%的情況發生。
實驗三,使用 Conv(strides=3) 取代 Pooling。
def alexnet_modify_conv_replace_pooling():
model = Sequential()
model.add(Conv2D(32, (11, 11), padding='valid', input_shape=(227,227,3)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3), strides=(3, 3), padding='valid'))
model.add(Conv2D(64, (7, 7), padding='valid'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3), strides=(3, 3), padding='valid'))
model.add(Conv2D(96, (3, 3), padding='valid'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(96, (3, 3), strides=(3, 3), padding='valid'))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3), strides=(3, 3), padding='valid'))
model.add(Flatten())
model.add(Dense(128))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dense(64))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dense(NUM_OF_CLASS))
return model
產出
EPOCH 194/200
loss: 7.5052e-04 - sparse_categorical_accuracy: 1.0000 - val_loss: 1.0053 - val_sparse_categorical_accuracy: 0.7734
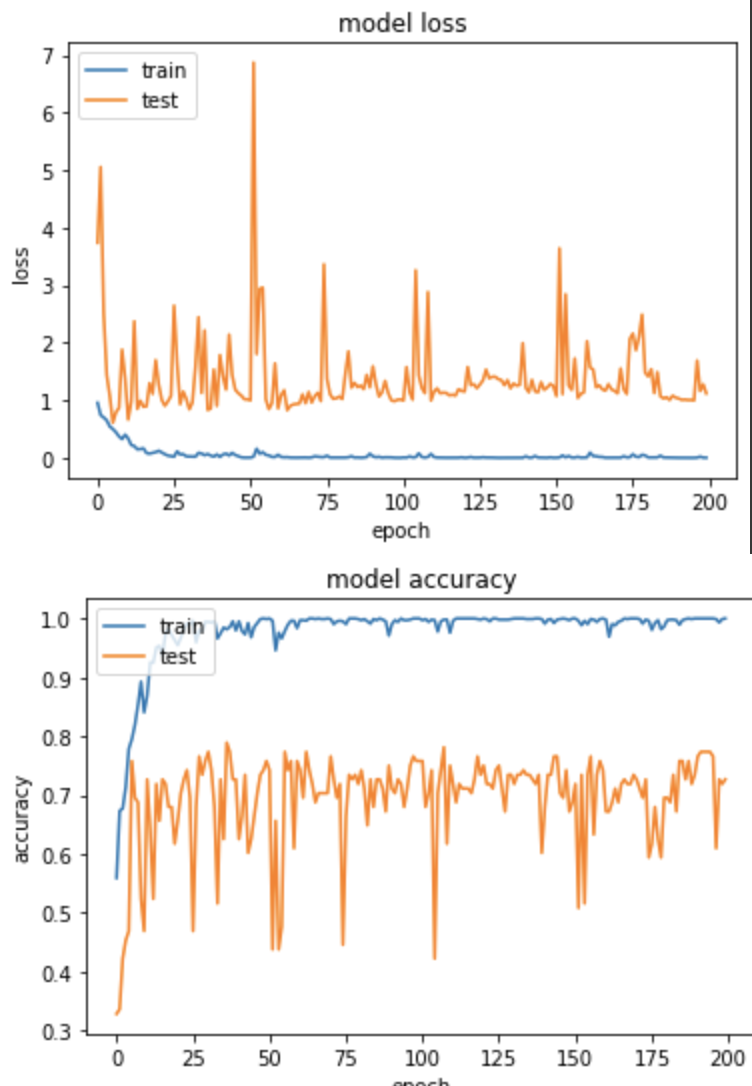
從結果的準確度來看,使用 Conv 取代 Pooling 並沒有比 Pooling 準確度來的高,當然可以再嘗試的地方就是將 Flatten 取代成 Global Pooling 並把後面的 Dense 拿掉,但是今天的測試純屬想知道只更換 Pooling 會產生什麼樣的變化,就做了這樣的實驗囉。

