
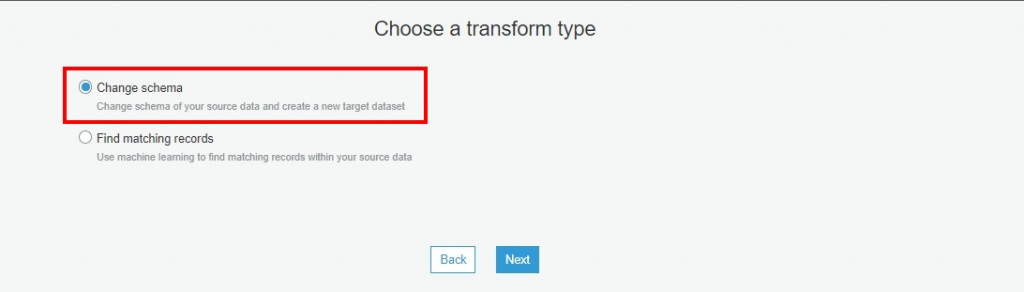
昨天我們已經透過 AWS Glue Crawler 自動建立 VPC Log 資料表,並且我們也看到 AWS Glue Crawler 業已依據資料夾切立 Partition,那可能此 Partition 不符合你的架構規劃,故我們可以透過 AWS Glue Job 來調整 Partition 分區結構以及將此格式轉換成 Parquet 以加快查詢速度。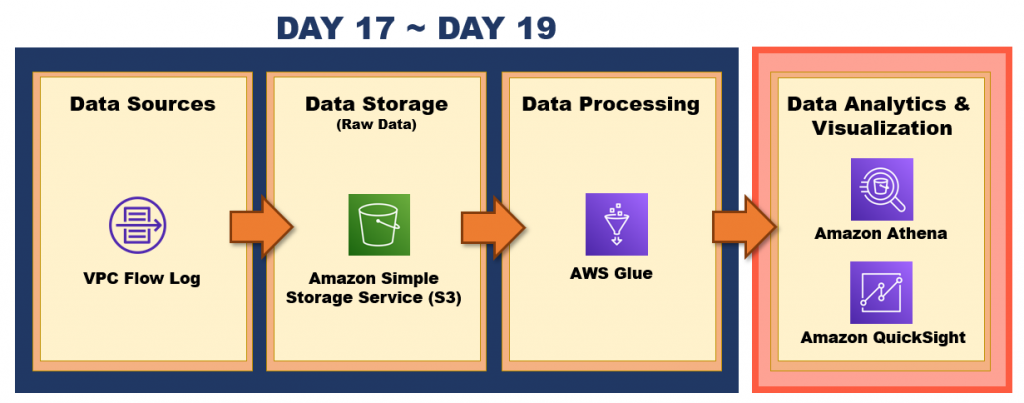
那我們就開始吧 GOGO
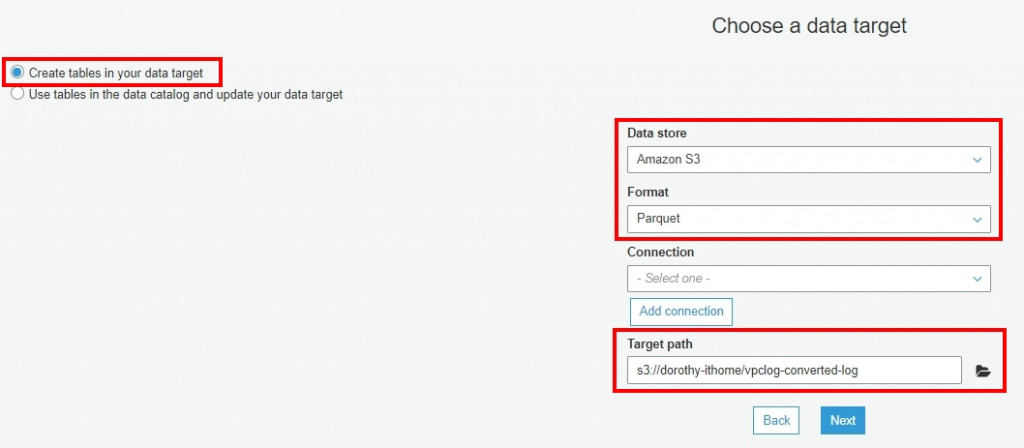
首先我們要建立一個資料夾來存放轉置成 Parquet 的 VPC Log,故我們於先前的 S3 Bucket Create folder (命名為:vpclog-converted-log )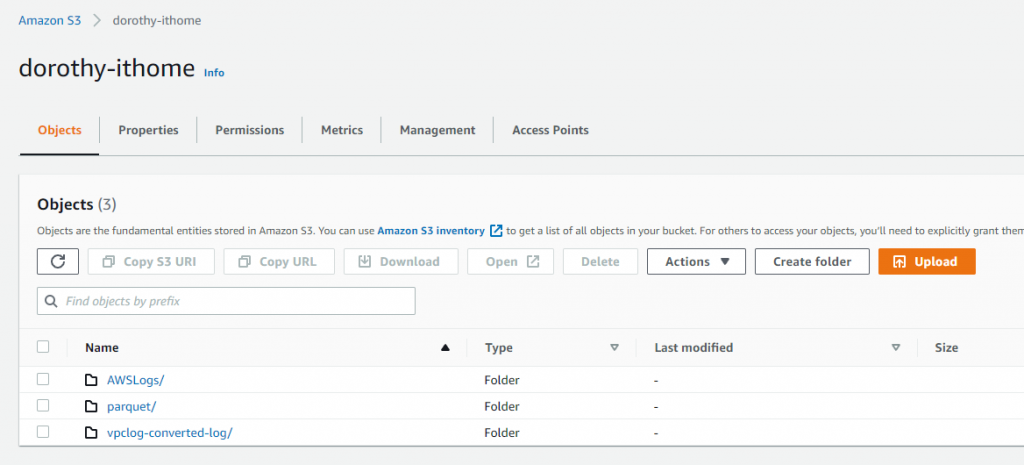
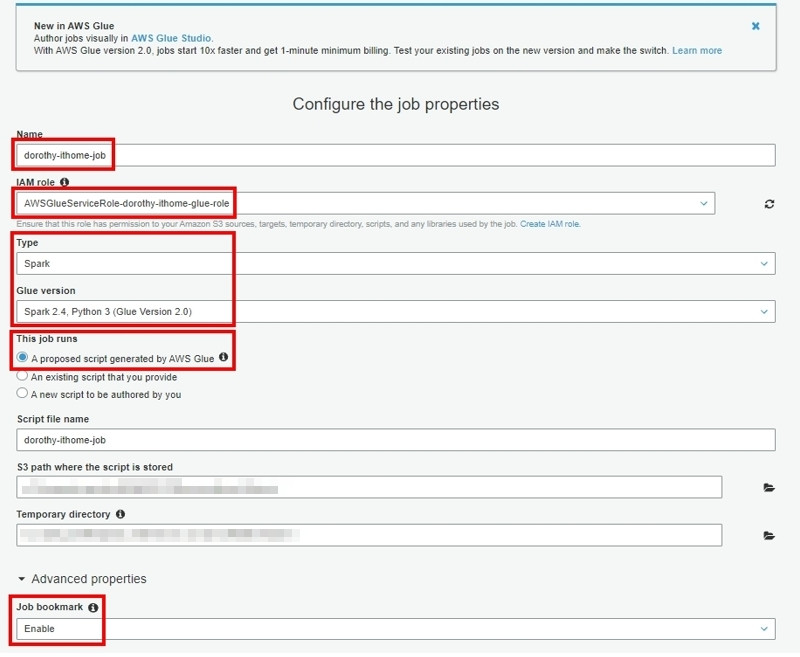
這邊我們選擇昨天創建的 vpc log 資料表,按 Next
左側為原始資料結構,右側是修改完的資料結構
因為我們要自行設定 Partition,故我們將 Target 的 Partition_x 都移除後按 Next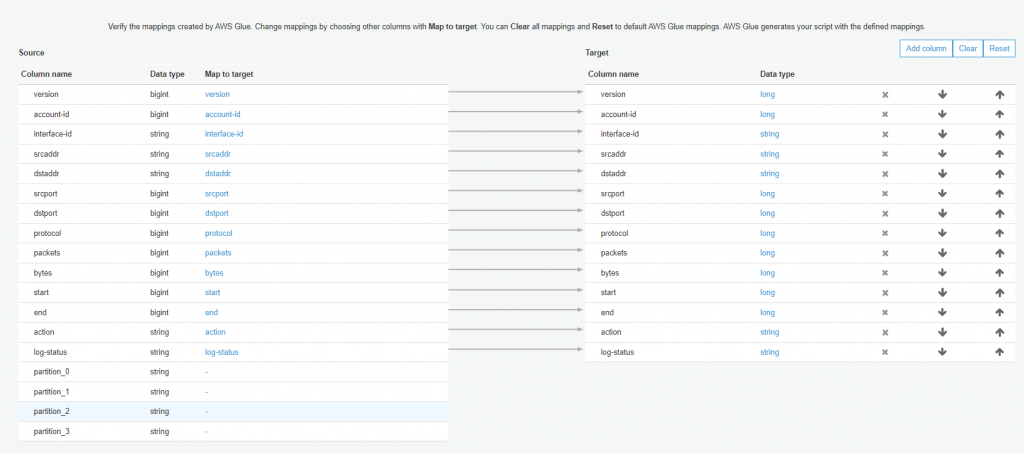
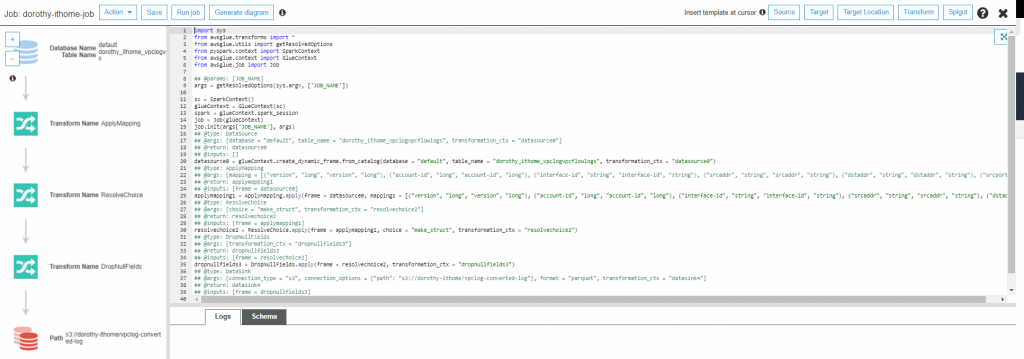
首先我們需要在最前面匯入以下套件
from awsglue.dynamicframe import DynamicFrame
from pyspark.sql.functions import *
接著我們打算抓原始資料的 start 欄位來切出『年/月/日』的 Partition,故我們在這行程式碼:dropnullfields3 = DropNullFields.apply(frame = resolvechoice2, transformation_ctx = "dropnullfields3")
增加以下程式碼:
dfdst = dropnullfields3.toDF()
dfdst = dfdst.withColumn("year",year(to_date(from_unixtime(dfdst.start))))
dfdst = dfdst.withColumn("month",month(to_date(from_unixtime(dfdst.start))))
dfdst = dfdst.withColumn("day",dayofmonth(to_date(from_unixtime(dfdst.start))))
resultFrame = DynamicFrame.fromDF(dfdst,glueContext,"result")
我們將此行程式碼datasink4 = …..
替換成以下程式碼
datasink4 = glueContext.write_dynamic_frame.from_options(frame = resultFrame, connection_type = "s3", connection_options = {"path": "s3://<<桶子名稱>> /<<存放VPC Log Parquet資料夾名稱>> /","partitionKeys":["year","month","day","action"]}, format = "parquet", transformation_ctx = "datasink4")
調整如下所示: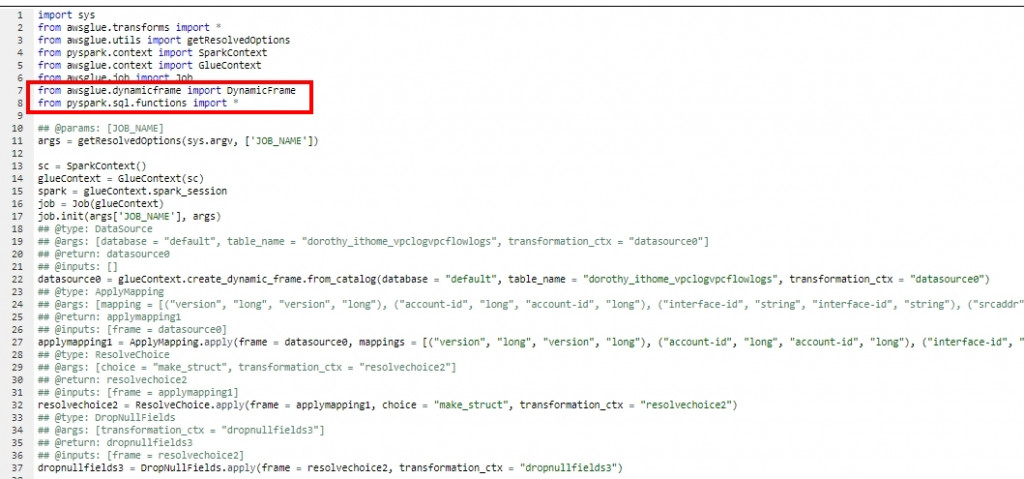

接著執行 Run Job ~ 大概等一分鐘就執行成功了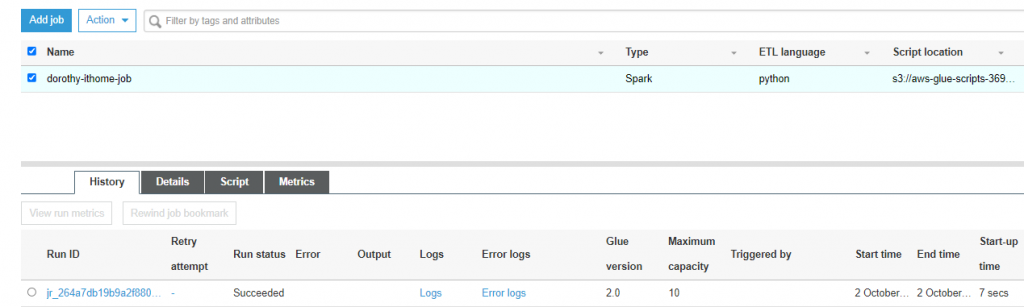
注意:
如果執行 AWS Glue Job 發生錯誤,可以看它的 Error 訊息是否為類似下方訊息An error occurred while calling o138.pyWriteDynamicFrame. Failed to delete key: vpclog-converted-log/_temporary
那應該是 IAM role 沒有授予適當權限,需要進行調整,下方為參考的 Policy ~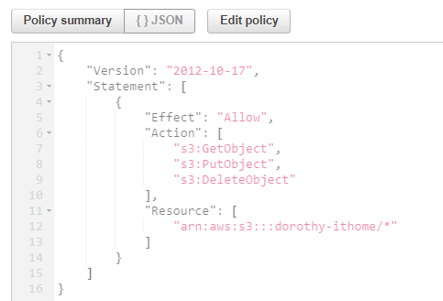

成功完成後,我們就可以看到此資料表的相關資訊,資料源格式為 Parquet,也可以看到我們剛剛手動新增的 Partition – year、month、day、action ~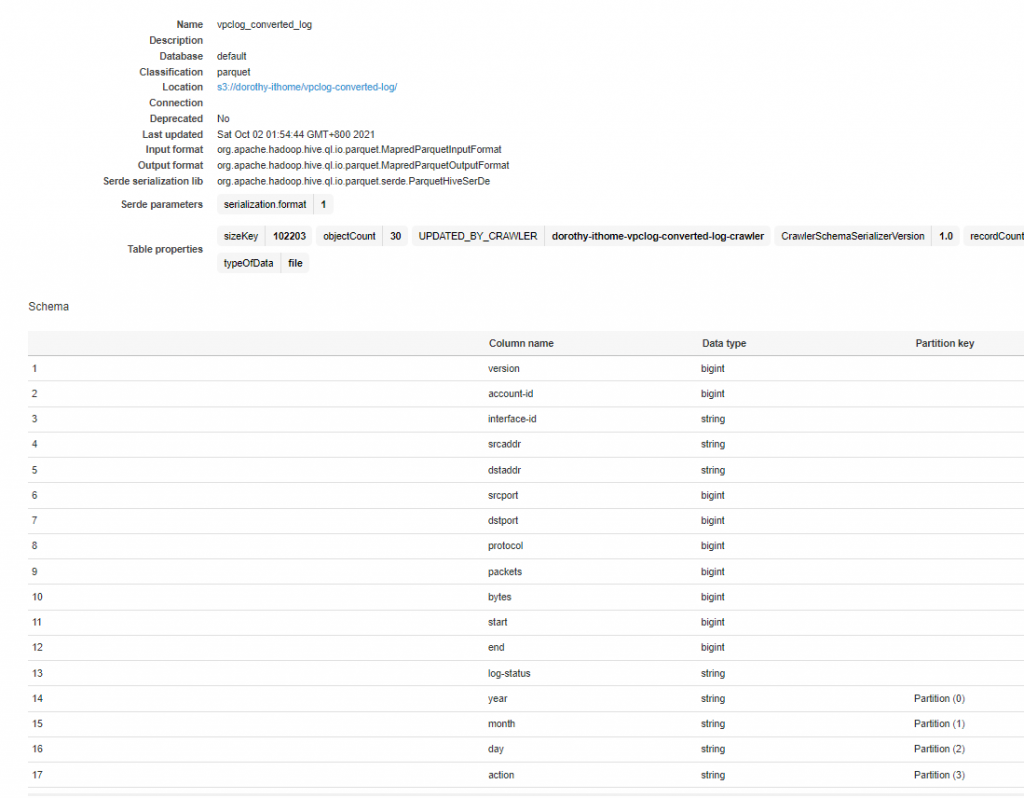
頗長的一篇文章哈哈 XD 今天我們成功地透過 AWS Glue Job 將 gz 檔案轉換成 Parquet,且調整 Partition 分層結構,那明天就進入了 Data Analytics & Visualization 階段啦
明天見囉 : D ~
如果有任何指點與建議,也歡迎留言交流,一起漫步在 Data on AWS 中。
