大家還記得 Datastore 和 Dataset 的關係嗎?我們再複習一下哦!
我們可以把 Datastores 理解成 Data Connector 的概念。它儲存資料的連線資訊,例如說你的資料在SQL database 裡,或者在 Azure Blob 裡,我們就可以透過 Datastores,安全地取得你的資料。而 Dataset,就是我們在做 Machine Learning 時的那個 Dataset,一般翻譯成資料集。
我們在前面使用了圖形化介面,點一點就建立好我們 Azure Machine Learning(下稱 AML) 的 Dataset。今天我們就來使用 SDK 建立 Dataset 吧!
我們從 Datastore 來建立 Dataset,有兩種形式,一種是表格形式的,一種是檔案形式的。前者就是我們之前建立的鐵達尼號,後者就是我們之前建立的寶可夢。
from_delimited_files 這個方法。注意在做 Dataset 時,要 import Dataset,還有要提供一個 tuple 哦!程式碼節錄如下:from azureml.core import Dataset
datastore = ws.datastores.get("您的datastore名稱")
csv_path = (datastore, "*.csv")
dataset = Dataset.Tabular.from_delimited_files(path=csv_path) # 這裡 path 要給一個 tuple 或是 List(tuple)
# 也可以去預設欄位的型別
# dataset = Dataset.Tabular.from_delimited_files(path=csv_path, set_column_types={'Survived': DataType.to_bool()})
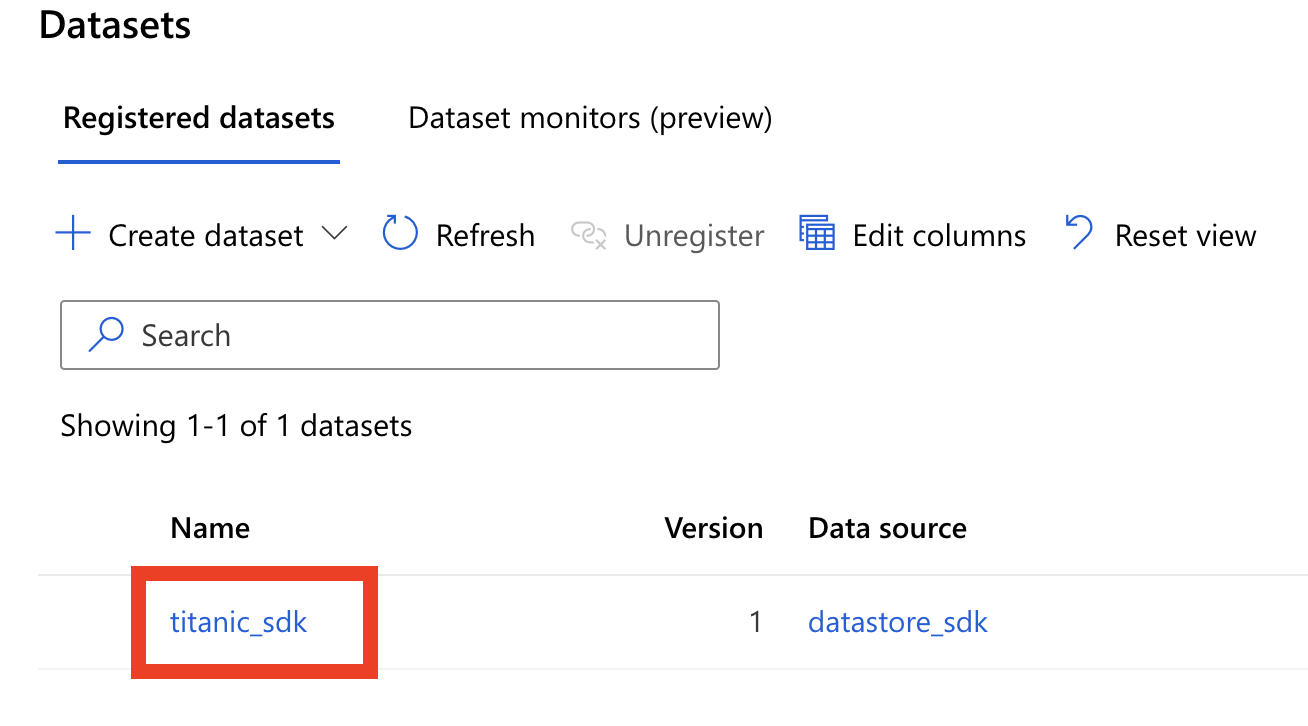
dataset = dataset.register(workspace=ws, name='titanic_sdk')
from azureml.core import Dataset
datastore = ws.datastores.get("您的datastore名稱")
# 因為影像檔有很多格式,這裡可以把 tuple 做成 List
img_path = [(datastore, "*.jpeg"),
(datastore, "*.png"),
(datastore, "*.jpg")]
img_data = Dataset.File.from_files(img_path)
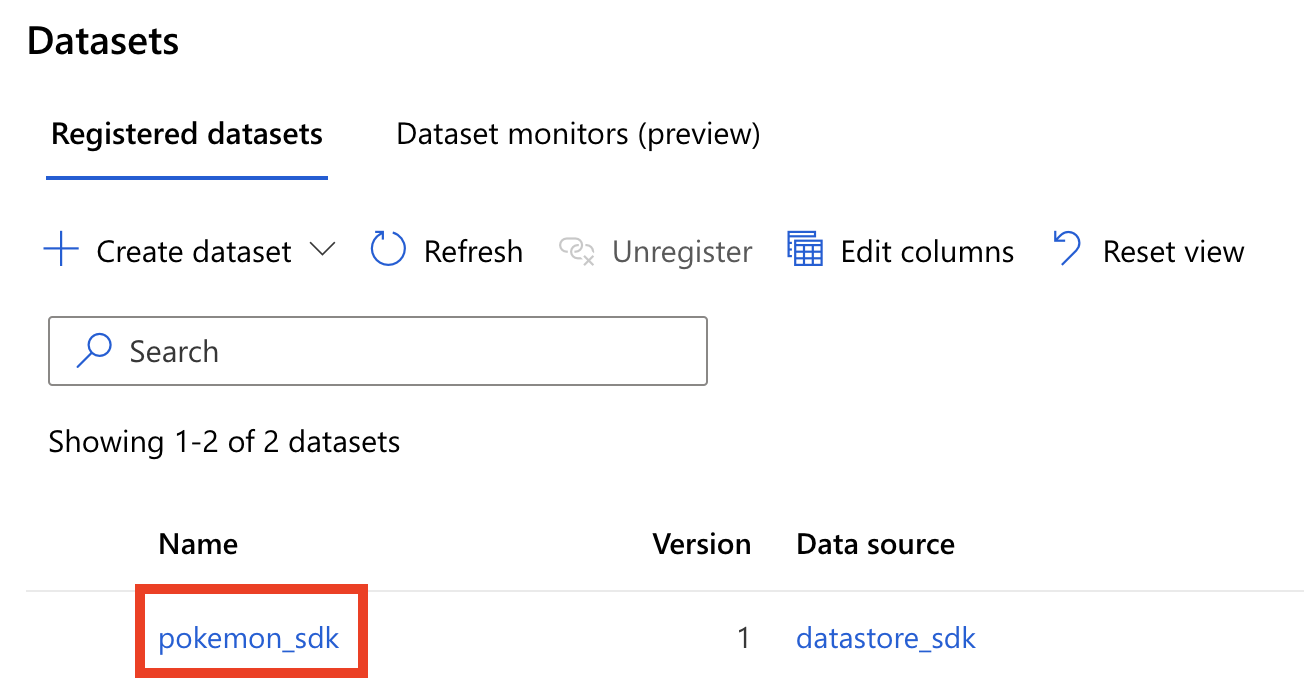
dataset = img_data.register(workspace=ws, name="pokemon_sdk")
dataset = Dataset.get_by_name(workspace, name='titanic_sdk')
dataset.to_pandas_dataframe()
dataset = Dataset.get_by_name(workspace, name='pokemon_sdk')
dataset.download(target_path='.', overwrite=False)
# 表格形式的(當然你轉成 Pandas dataframe 之後,用 Pandas 內建的功能更強大)
tabular_dataset = tabular_dataset.filter((tabular_dataset['name'].contains('koko')) & (tabular_dataset['age'] > 18))
# 檔案形式的
file_dataset = file_dataset.filter((file_dataset.file_metadata['CreatedTime'] < datetime(2020,1,1)) | (file_dataset.file_metadata['Size'] < 1024))
# 標記資料專案裡面標簽的
labeled_dataset = labeled_dataset.filter((labeled_dataset['label']['Pikachu'] == True) & (labeled_dataset.file_metadata['Size'] > 10000))
以上就是今天我們的建立 Dataset 和取用啦!明天我們再來建立運算資源。

