今天的內容會說明將 attention 機制加入到昨天提到的 multi-scale CNN 當中。
CNN 中的 attention 機制是受到自然界中生物的視覺注意機制所啟發。例如,人類能夠以高分辨率專注於圖像的特定區域,同時以低分辨率感知周圍區域。此外,焦點區域可以以看似毫不費力的方式進行動態轉移。為了能夠使 CNN 架構
中不同特徵圖的不同區域有不同的貢獻值,我們在 CNN 模型中加入 attention 機制。
在模型架構中,attention module 的輸入為 multi-scale CNN 第一層經過 max-out uni 取最大值後的feature map。attention module 由兩層 max-pooling layer(pooling size: 2x2)及兩層 upsampling layer(採樣方式為雙線性內插 Bilinear Interpolation)組成。其中所有的 max-pooling layer 及 upsampling layer 後面都會接著一層 conv layer,kernel size 皆為2x2,輸出的 feature map 維度分別為30、20、20及10,最後在使用 softmax 進行轉換。attention module 的輸出會與 multi-scale CNN 的輸出相乘,再將相乘的結果與原本 multi-scale CNN 的輸出相加最後再傳遞至輸出層,架構如圖 1。
雙線性內插 (Bilinear Interpolation) 為線性內插在二維直角網格的擴展,用於對雙變
量函數(ex: x , y)進行內插。其核心概念是在兩個方向上分別進行一次線性內插。
圖 2 為雙線性內插的示意圖。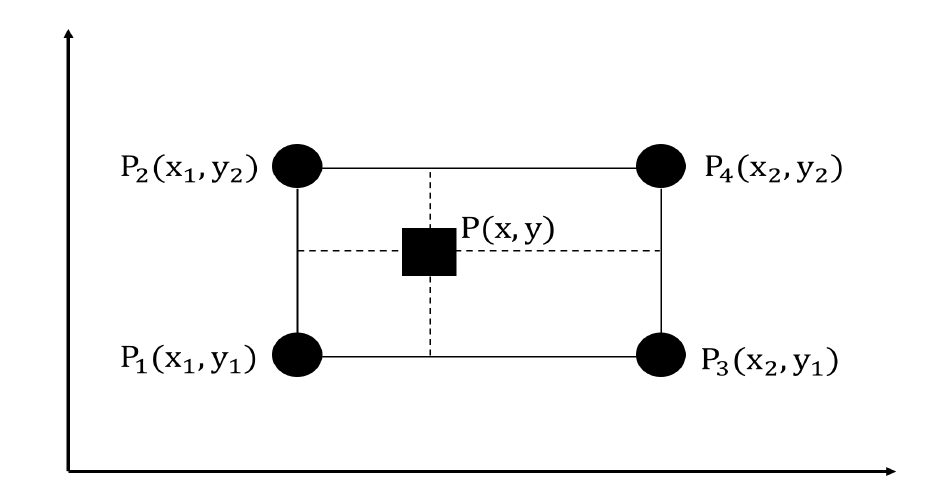
圖 2: 雙線性內插示意圖。四個圓形的點(P1、P2、P3、P4)代表已知的資料點而正方形的點(P)代要進行內插的點
具體來說,假設我們要近似函數 f(.) 在點 P=(x,y) 的值。已知函數 f(.) 在點 、
、
、
的值,則函數 f(.) 在點 P=(x,y) 的雙線性內插定義如下:
實際上在實作時可以直接透過 tensorflow 的 image resize 來完成
def interpolation(inputs, size):
return tf.image.resize_images(inputs, size, method=tf.image.ResizeMethod.BILINEAR)
method 參數的部份,詳細說明可以參考這裡。
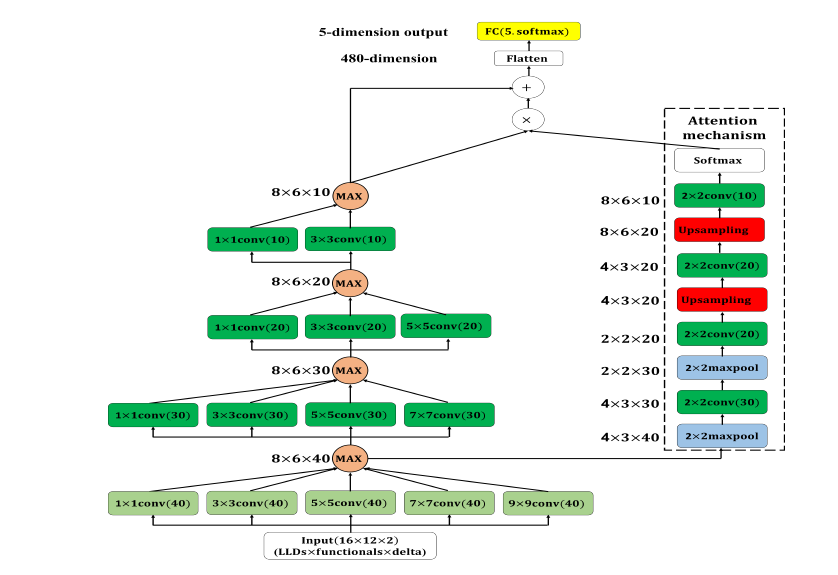
圖 1: Multi-scale CNN with attention mechanism 靜態模型。每一層卷積層後的activation function 使用 tanh 與 ReLU,所有卷積層 padding 方式皆為 zero-padding,淺綠色卷積層 stride=2;深綠色卷積層 stride=1
依照圖 1 的架構轉換成程式:
cnn_train_data = np.reshape(train_data, (train_data.shape[0], args.llds, args.functionals, args.delta))
cnn_test_data = np.reshape(test_data, (test_data.shape[0], args.llds, args.functionals, args.delta))
# 8x6x40
conv1_1 = Conv2D(filters=40,kernel_size=(1,1),strides=(2,2),padding='same', activation='relu', name='conv1_1')(cnn_input)
conv1_2 = Conv2D(filters=40,kernel_size=(3,3),strides=(2,2),padding='same', activation='relu', name='conv1_2')(cnn_input)
conv1_3 = Conv2D(filters=40,kernel_size=(5,5),strides=(2,2),padding='same', activation='relu', name='conv1_3')(cnn_input)
conv1_4 = Conv2D(filters=40,kernel_size=(7,7),strides=(2,2),padding='same', activation='relu', name='conv1_4')(cnn_input)
conv1_5 = Conv2D(filters=40,kernel_size=(9,9),strides=(2,2),padding='same', activation='relu', name='conv1_5')(cnn_input)
conv1_maxout = maximum([conv1_1, conv1_2, conv1_3, conv1_4, conv1_5], name='conv_max1')
#4x3x30
conv2_1 = Conv2D(filters=30,kernel_size=(1,1),strides=(1,1),padding='same', activation='relu', name='conv2_1')(conv1_maxout)
conv2_2 = Conv2D(filters=30,kernel_size=(3,3),strides=(1,1),padding='same', activation='relu', name='conv2_2')(conv1_maxout)
conv2_3 = Conv2D(filters=30,kernel_size=(5,5),strides=(1,1),padding='same', activation='relu', name='conv2_3')(conv1_maxout)
conv2_4 = Conv2D(filters=30,kernel_size=(7,7),strides=(1,1),padding='same', activation='relu', name='conv2_4')(conv1_maxout)
conv2_maxout = maximum([conv2_1, conv2_2, conv2_3, conv2_4], name='conv_max2')
#2x2x20
conv3_1 = Conv2D(filters=20,kernel_size=(1,1),strides=(1,1),padding='same', activation='relu', name='conv3_1')(conv2_maxout)
conv3_2 = Conv2D(filters=20,kernel_size=(3,3),strides=(1,1),padding='same', activation='relu', name='conv3_2')(conv2_maxout)
conv3_3 = Conv2D(filters=20,kernel_size=(5,5),strides=(1,1),padding='same', activation='relu', name='conv3_3')(conv2_maxout)
conv3_maxout = maximum([conv3_1, conv3_2, conv3_3], name='conv_max3')
#1x1x10
conv4_1 = Conv2D(filters=10, kernel_size=(1,1),strides=(1,1),padding='same', activation='relu', name='conv4_1')(conv3_maxout)
conv4_2 = Conv2D(filters=10, kernel_size=(3,3),strides=(1,1),padding='same', activation='relu', name='conv4_2')(conv3_maxout)
conv4_maxout = maximum([conv4_1, conv4_2], name='conv_max4')
# attention module (input: 8x6x40)
attention_pool_1 = MaxPooling2D(pool_size=(2,2), padding='same', name='att_pool1')(conv1_maxout)# 4x3x40
attention_conv_1 = Conv2D(filters=30, kernel_size=(2,2), padding='same', activation='relu', use_bias=False, name='att_conv1')(attention_pool_1)# 4x3x30
attention_pool_2 = MaxPooling2D(pool_size=(2,2), padding='same', name='att_pool2')(attention_conv_1)#2x2x30
attention_conv_2 = Conv2D(filters=20, kernel_size=(2,2), padding='same', activation='relu', use_bias=False, name='att_conv2')(attention_pool_2)#2x2x20
attention_interp_1 = Lambda(interpolation, arguments={'size': (4,3)}, name='att_up1')(attention_conv_2)# 4x3x20
attention_conv_3 = Conv2D(filters=20, kernel_size=(2,2), padding='same', activation='relu', use_bias=False, name='att_conv3')(attention_interp_1)#4x3x20
attention_interp_2 = Lambda(interpolation, arguments={'size': (8,6)}, name='att_up2')(attention_conv_3)# 8x6x20
attention_conv_4 = Conv2D(filters=10, kernel_size=(2,2), padding='same', activation='relu', use_bias=False, name='att_conv4')(attention_interp_2)#8x6x1
attention_weights = Activation('softmax', name='attention_weights')(attention_conv_4)
attention_representation = multiply([conv4_maxout, attention_weights])
attention_add = add([conv4_maxout, attention_representation])
conv_flatten = Flatten()(conv4_maxout)# 480
output = Dense(units=args.classes, activation='softmax', name='output')(conv_flatten)
model = Model(inputs=cnn_input, outputs=output)
model.summary()
前半部的部分跟昨天的 multi-scale CNN 相同,增加的部分在於 attention module。
在說明完三種的 CNN 架構後,我們就來做個比較吧。在表 1 中可發現將 attention 機制應用於multi-scale CNN上並沒有顯著的影響,UA recall 僅從 46.1% 上升至 46.4%。主要原因應為應用於 CNN 的 attention 機制目的是要決定不同空間區域的貢獻程度。然而,語音訊號的本質並非空間而是時間。
Model | UA recall (tanh) | UA recall (ReLU)
------------- | -------------
Basic CNN | 44.1% | 43.6%
Multi-scale CNN | 46.1% | 45.3%
Multi-scale CNN with attention | 46.4% | 45.6%
表 1: 三種 CNN 與不同 activation function 實驗結果比較
我們再將最好的結果 (UA recall=46.4%) 列出其混淆矩陣如表 2
/ | A | E | N | P | R | UA recall
------------- | -------------
A | 382 | 85 | 96 | 33 | 15 | 62.5%
E | 336 | 746 | 345 | 63 | 18 | 49.5%
N | 748 | 977 | 2,788 | 770 | 94 | 51.9%
P | 13 | 9 | 52 | 135 | 6 | 62.8%
R | 113 | 81 | 190 | 133 | 29 | 5.3%
Avg.recall | - | - | - | - | - | 46.4%
表 2: Multi-scale CNN with attention 分類結果混淆矩陣(A:angry, E:emphatic,
N:neutral, P:positive, R:rest
靜態模型的部分就到這邊了,明天開始將介紹動態模型的部分。

