不知道大家有沒有發現,目前現在主流的網路結構中已經愈來愈少看到 Dropout 了,在早期 VGG 還當紅時,Dropout 在 Dense Layer 中是個很好的防過擬合手段,然而近年主流的網路結構朝全 CNN 層的思維來設計,Dense Layer 越少出現就導致了 Dropout 越少被使用。
那CNN就不能用Dropout 嗎?這篇文章 Don’t Use Dropout in Convolutional Networks 做了幾個實驗比較 Batch Normalization 和 Deopout 比較的實驗,文章認為 BN 可以很好的取代 Dropout。
那麼為什麼在 CNN 裡面使用 Dropout 效果並不好?這篇文章 Dropout on convolutional layers is weird 有很好的證明,文章內中提到,一般 Dropout 用在 Dense Layer 時,我們就是屏蔽掉某幾個節點的權重,但是如果 Dropout 用在 CNN 層時,因為 CNN 的卷積是有空間性的(例如3x3個像數),所以你無法很乾淨的屏蔽權重的更新,因為鄰近的 kernel 權重都會影響。
看完以上比較偏重理論的部分,我們還是要來實驗當你硬要會發生什麼事?模型就拿 mobilenetV2 來做修改。
實驗一:把所有 BN 全部替換成 Dropout
def bottleneck(net, filters, out_ch, strides, shortcut=True, zero_pad=False, drop_rate=0.0):
padding = 'valid' if zero_pad else 'same'
shortcut_net = net
net = tf.keras.layers.Conv2D(filters * 6, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.Dropout(drop_rate)(net)
if zero_pad:
net = tf.keras.layers.ZeroPadding2D(padding=((0, 1), (0, 1)))(net)
net = tf.keras.layers.DepthwiseConv2D(3, strides=strides, use_bias=False, padding=padding)(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.Dropout(drop_rate)(net)
net = tf.keras.layers.Conv2D(out_ch, 1, use_bias=False, padding='same')(net)
if shortcut:
net = tf.keras.layers.Add()([net, shortcut_net])
return net
def get_mobilenetV2_dropout(shape, rate):
input_node = tf.keras.layers.Input(shape=shape)
net = tf.keras.layers.Conv2D(32, 3, (2, 2), use_bias=False, padding='same')(input_node)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.Dropout(rate)(net)
net = tf.keras.layers.DepthwiseConv2D(3, use_bias=False, padding='same')(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.Dropout(rate)(net)
net = tf.keras.layers.Conv2D(16, 1, use_bias=False, padding='same')(net)
net = bottleneck(net, 16, 24, (2, 2), shortcut=False, zero_pad=True, drop_rate=rate) # block_1
net = bottleneck(net, 24, 24, (1, 1), shortcut=True, drop_rate=rate) # block_2
net = bottleneck(net, 24, 32, (2, 2), shortcut=False, zero_pad=True, drop_rate=rate) # block_3
net = bottleneck(net, 32, 32, (1, 1), shortcut=True, drop_rate=rate) # block_4
net = bottleneck(net, 32, 32, (1, 1), shortcut=True, drop_rate=rate) # block_5
net = bottleneck(net, 32, 64, (2, 2), shortcut=False, zero_pad=True, drop_rate=rate) # block_6
net = bottleneck(net, 64, 64, (1, 1), shortcut=True, drop_rate=rate) # block_7
net = bottleneck(net, 64, 64, (1, 1), shortcut=True, drop_rate=rate) # block_8
net = bottleneck(net, 64, 64, (1, 1), shortcut=True, drop_rate=rate) # block_9
net = bottleneck(net, 64, 96, (1, 1), shortcut=False, drop_rate=rate) # block_10
net = bottleneck(net, 96, 96, (1, 1), shortcut=True, drop_rate=rate) # block_11
net = bottleneck(net, 96, 96, (1, 1), shortcut=True, drop_rate=rate) # block_12
net = bottleneck(net, 96, 160, (2, 2), shortcut=False, zero_pad=True, drop_rate=rate) # block_13
net = bottleneck(net, 160, 160, (1, 1), shortcut=True, drop_rate=rate) # block_14
net = bottleneck(net, 160, 160, (1, 1), shortcut=True, drop_rate=rate) # block_15
net = bottleneck(net, 160, 320, (1, 1), shortcut=False, drop_rate=rate) # block_16
net = tf.keras.layers.Conv2D(1280, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.Dropout(rate)(net)
return input_node, net
DROP_RATE=0.1
input_node, net = get_mobilenetV2_dropout((224,224,3), DROP_RATE)
net = tf.keras.layers.GlobalAveragePooling2D()(net)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[input_node], outputs=[net])
# model.summary()
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
產出:
loss: 2.3033 - sparse_categorical_accuracy: 0.0998 - val_loss: 2.3033 - val_sparse_categorical_accuracy: 0.1000
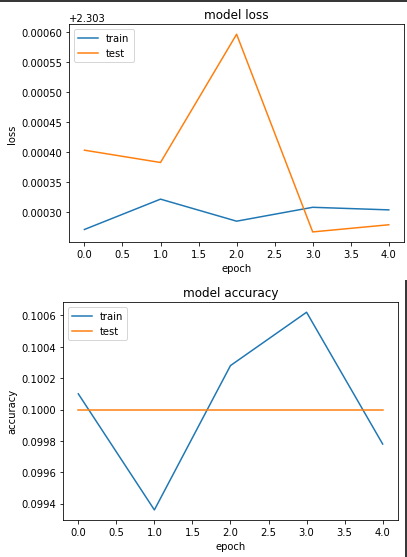
完全沒在訓練,很明顯這樣做並不行...
實驗二:在有 BN 之後接 Dropout
def bottleneck(net, filters, out_ch, strides, shortcut=True, zero_pad=False, drop_rate=0.0):
padding = 'valid' if zero_pad else 'same'
shortcut_net = net
net = tf.keras.layers.Conv2D(filters * 6, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.Dropout(drop_rate)(net)
if zero_pad:
net = tf.keras.layers.ZeroPadding2D(padding=((0, 1), (0, 1)))(net)
net = tf.keras.layers.DepthwiseConv2D(3, strides=strides, use_bias=False, padding=padding)(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.Dropout(drop_rate)(net)
net = tf.keras.layers.Conv2D(out_ch, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
if shortcut:
net = tf.keras.layers.Add()([net, shortcut_net])
return net
def get_mobilenetV2_bn_with_dropout(shape, rate):
input_node = tf.keras.layers.Input(shape=shape)
net = tf.keras.layers.Conv2D(32, 3, (2, 2), use_bias=False, padding='same')(input_node)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.Dropout(rate)(net)
net = tf.keras.layers.DepthwiseConv2D(3, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.Dropout(rate)(net)
net = tf.keras.layers.Conv2D(16, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
net = bottleneck(net, 16, 24, (2, 2), shortcut=False, zero_pad=True, drop_rate=rate) # block_1
net = bottleneck(net, 24, 24, (1, 1), shortcut=True, drop_rate=rate) # block_2
net = bottleneck(net, 24, 32, (2, 2), shortcut=False, zero_pad=True, drop_rate=rate) # block_3
net = bottleneck(net, 32, 32, (1, 1), shortcut=True, drop_rate=rate) # block_4
net = bottleneck(net, 32, 32, (1, 1), shortcut=True, drop_rate=rate) # block_5
net = bottleneck(net, 32, 64, (2, 2), shortcut=False, zero_pad=True, drop_rate=rate) # block_6
net = bottleneck(net, 64, 64, (1, 1), shortcut=True, drop_rate=rate) # block_7
net = bottleneck(net, 64, 64, (1, 1), shortcut=True, drop_rate=rate) # block_8
net = bottleneck(net, 64, 64, (1, 1), shortcut=True, drop_rate=rate) # block_9
net = bottleneck(net, 64, 96, (1, 1), shortcut=False, drop_rate=rate) # block_10
net = bottleneck(net, 96, 96, (1, 1), shortcut=True, drop_rate=rate) # block_11
net = bottleneck(net, 96, 96, (1, 1), shortcut=True, drop_rate=rate) # block_12
net = bottleneck(net, 96, 160, (2, 2), shortcut=False, zero_pad=True, drop_rate=rate) # block_13
net = bottleneck(net, 160, 160, (1, 1), shortcut=True, drop_rate=rate) # block_14
net = bottleneck(net, 160, 160, (1, 1), shortcut=True, drop_rate=rate) # block_15
net = bottleneck(net, 160, 320, (1, 1), shortcut=False, drop_rate=rate) # block_16
net = tf.keras.layers.Conv2D(1280, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.Dropout(rate)(net)
return input_node, net
DROP_RATE=0.1
input_node, net = get_mobilenetV2_bn_with_dropout((224,224,3), DROP_RATE)
net = tf.keras.layers.GlobalAveragePooling2D()(net)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[input_node], outputs=[net])
# model.summary()
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
產出
loss: 0.6246 - sparse_categorical_accuracy: 0.7846 - val_loss: 0.7367 - val_sparse_categorical_accuracy: 0.7511
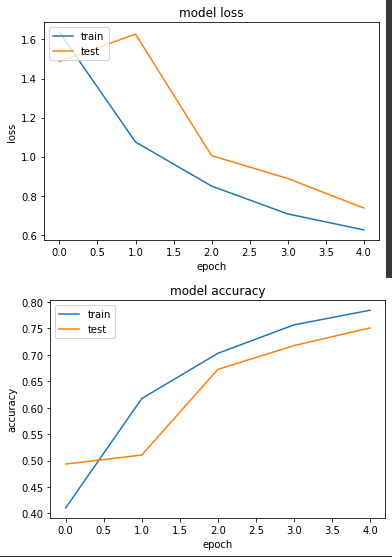
實驗二有跑起來,雖然測試的 epoch 數量不多,但至少是有再訓練的。
我個人實務上會用上 dropout 的時機大部分也是在模型後段如果有用上 Dense Layer 時,才會套用 Dropout,畢竟現在防止過擬合已經有更多手段可以選擇。

