今天要來實驗不同的 ReLU 家族的評比,挑戰者有
說真的,有那麼多 ReLU,但我自己實務上卻只使用過第一種基本款,所以我也蠻好奇這次實驗會有多大的對比。
而因為這次想跑多次的 epochs 來進行實驗,所以資料集的部分改用 beans 來實驗。

實驗一:基本 ReLU
def bottleneck(net, filters, out_ch, strides, shortcut=True, zero_pad=False):
padding = 'valid' if zero_pad else 'same'
shortcut_net = net
net = tf.keras.layers.Conv2D(filters * 6, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
if zero_pad:
net = tf.keras.layers.ZeroPadding2D(padding=((0, 1), (0, 1)))(net)
net = tf.keras.layers.DepthwiseConv2D(3, strides=strides, use_bias=False, padding=padding)(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.Conv2D(out_ch, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
if shortcut:
net = tf.keras.layers.Add()([net, shortcut_net])
return net
def get_mobilenetV2_relu(shape):
input_node = tf.keras.layers.Input(shape=shape)
net = tf.keras.layers.Conv2D(32, 3, (2, 2), use_bias=False, padding='same')(input_node)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.DepthwiseConv2D(3, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.Conv2D(16, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
net = bottleneck(net, 16, 24, (2, 2), shortcut=False, zero_pad=True) # block_1
net = bottleneck(net, 24, 24, (1, 1), shortcut=True) # block_2
net = bottleneck(net, 24, 32, (2, 2), shortcut=False, zero_pad=True) # block_3
net = bottleneck(net, 32, 32, (1, 1), shortcut=True) # block_4
net = bottleneck(net, 32, 32, (1, 1), shortcut=True) # block_5
net = bottleneck(net, 32, 64, (2, 2), shortcut=False, zero_pad=True) # block_6
net = bottleneck(net, 64, 64, (1, 1), shortcut=True) # block_7
net = bottleneck(net, 64, 64, (1, 1), shortcut=True) # block_8
net = bottleneck(net, 64, 64, (1, 1), shortcut=True) # block_9
net = bottleneck(net, 64, 96, (1, 1), shortcut=False) # block_10
net = bottleneck(net, 96, 96, (1, 1), shortcut=True) # block_11
net = bottleneck(net, 96, 96, (1, 1), shortcut=True) # block_12
net = bottleneck(net, 96, 160, (2, 2), shortcut=False, zero_pad=True) # block_13
net = bottleneck(net, 160, 160, (1, 1), shortcut=True) # block_14
net = bottleneck(net, 160, 160, (1, 1), shortcut=True) # block_15
net = bottleneck(net, 160, 320, (1, 1), shortcut=False) # block_16
net = tf.keras.layers.Conv2D(1280, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
return input_node, net
input_node, net = get_mobilenetV2_relu((224,224,3))
net = tf.keras.layers.GlobalAveragePooling2D()(net)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[input_node], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
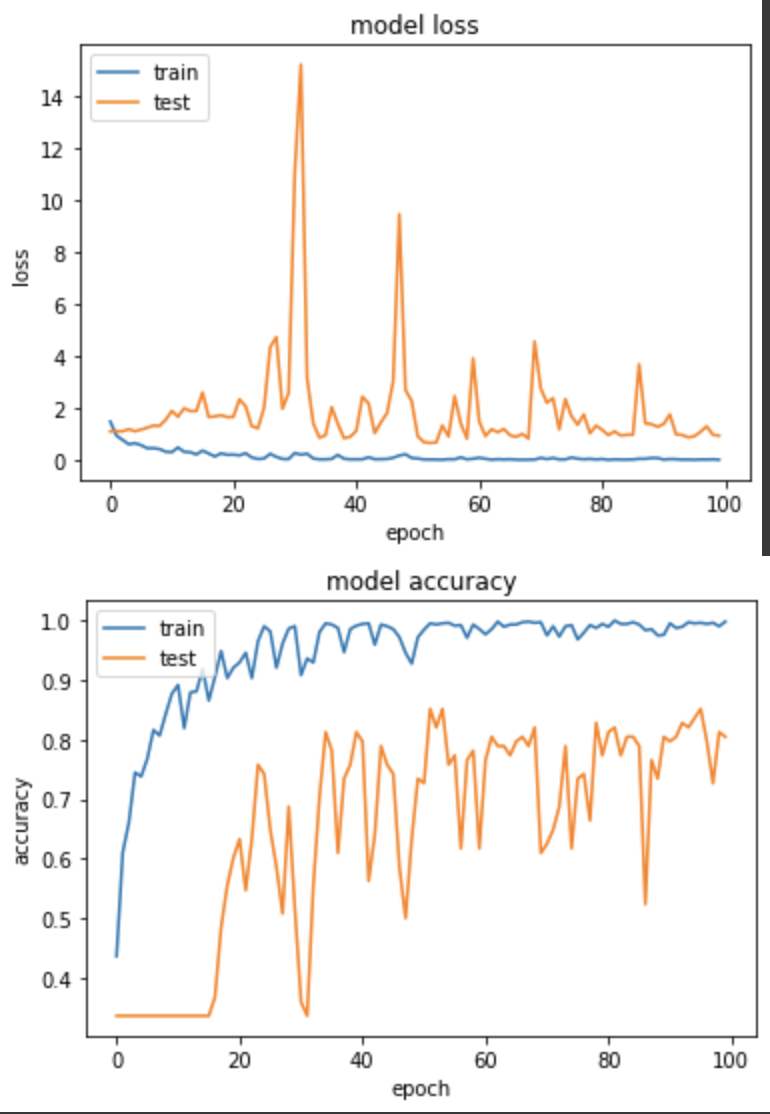
產出:
Epoch 96/100
loss: 0.0074 - sparse_categorical_accuracy: 0.9961 - val_loss: 0.9123 - val_sparse_categorical_accuracy: 0.8516
實驗二:Leaky ReLU
一般的 ReLU 遇到輸入為負值時,輸出會變成0,很容易讓大半的節點死亡,因此我們在輸入負值時,仍然給它一個 α 值,讓他微分時仍然可以更新權重,在這邊我們用預設的0.3。
def bottleneck(net, filters, out_ch, strides, shortcut=True, zero_pad=False):
padding = 'valid' if zero_pad else 'same'
shortcut_net = net
net = tf.keras.layers.Conv2D(filters * 6, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.LeakyReLU()(net)
if zero_pad:
net = tf.keras.layers.ZeroPadding2D(padding=((0, 1), (0, 1)))(net)
net = tf.keras.layers.DepthwiseConv2D(3, strides=strides, use_bias=False, padding=padding)(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.LeakyReLU()(net)
net = tf.keras.layers.Conv2D(out_ch, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
if shortcut:
net = tf.keras.layers.Add()([net, shortcut_net])
return net
def get_mobilenetV2_leakyrelu(shape):
input_node = tf.keras.layers.Input(shape=shape)
net = tf.keras.layers.Conv2D(32, 3, (2, 2), use_bias=False, padding='same')(input_node)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.LeakyReLU()(net)
net = tf.keras.layers.DepthwiseConv2D(3, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.LeakyReLU()(net)
net = tf.keras.layers.Conv2D(16, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
net = bottleneck(net, 16, 24, (2, 2), shortcut=False, zero_pad=True) # block_1
net = bottleneck(net, 24, 24, (1, 1), shortcut=True) # block_2
net = bottleneck(net, 24, 32, (2, 2), shortcut=False, zero_pad=True) # block_3
net = bottleneck(net, 32, 32, (1, 1), shortcut=True) # block_4
net = bottleneck(net, 32, 32, (1, 1), shortcut=True) # block_5
net = bottleneck(net, 32, 64, (2, 2), shortcut=False, zero_pad=True) # block_6
net = bottleneck(net, 64, 64, (1, 1), shortcut=True) # block_7
net = bottleneck(net, 64, 64, (1, 1), shortcut=True) # block_8
net = bottleneck(net, 64, 64, (1, 1), shortcut=True) # block_9
net = bottleneck(net, 64, 96, (1, 1), shortcut=False) # block_10
net = bottleneck(net, 96, 96, (1, 1), shortcut=True) # block_11
net = bottleneck(net, 96, 96, (1, 1), shortcut=True) # block_12
net = bottleneck(net, 96, 160, (2, 2), shortcut=False, zero_pad=True) # block_13
net = bottleneck(net, 160, 160, (1, 1), shortcut=True) # block_14
net = bottleneck(net, 160, 160, (1, 1), shortcut=True) # block_15
net = bottleneck(net, 160, 320, (1, 1), shortcut=False) # block_16
net = tf.keras.layers.Conv2D(1280, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.LeakyReLU()(net)
return input_node, net
input_node, net = get_mobilenetV2_leakyrelu((224,224,3))
net = tf.keras.layers.GlobalAveragePooling2D()(net)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[input_node], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
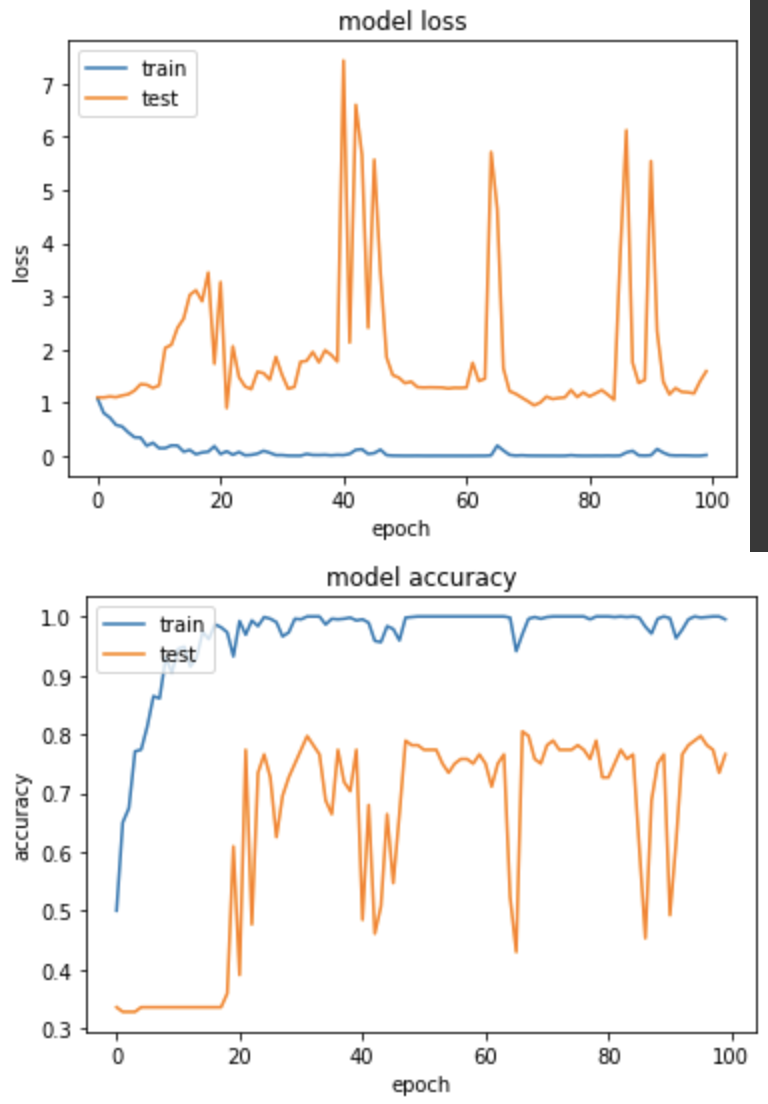
產出:
Epoch 96/100
loss: 0.0074 - sparse_categorical_accuracy: 0.9981 - val_loss: 1.2042 - val_sparse_categorical_accuracy: 0.7969
實驗三:PReLU
有了 LeakyReLU 後,就會有人覺得給予固定的 α 值似乎讓模型缺乏了彈性,因此不如讓這個值也變成模型學習的參數,所以就有了 PReLU,在這邊我們讓他的初始值為0.25。
def bottleneck(net, filters, out_ch, strides, shortcut=True, zero_pad=False):
padding = 'valid' if zero_pad else 'same'
shortcut_net = net
net = tf.keras.layers.Conv2D(filters * 6, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.PReLU(alpha_initializer=tf.initializers.constant(0.25))(net)
if zero_pad:
net = tf.keras.layers.ZeroPadding2D(padding=((0, 1), (0, 1)))(net)
net = tf.keras.layers.DepthwiseConv2D(3, strides=strides, use_bias=False, padding=padding)(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.PReLU(alpha_initializer=tf.initializers.constant(0.25))(net)
net = tf.keras.layers.Conv2D(out_ch, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
if shortcut:
net = tf.keras.layers.Add()([net, shortcut_net])
return net
def get_mobilenetV2_prelu(shape):
input_node = tf.keras.layers.Input(shape=shape)
net = tf.keras.layers.Conv2D(32, 3, (2, 2), use_bias=False, padding='same')(input_node)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.PReLU(alpha_initializer=tf.initializers.constant(0.25))(net)
net = tf.keras.layers.DepthwiseConv2D(3, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.PReLU(alpha_initializer=tf.initializers.constant(0.25))(net)
net = tf.keras.layers.Conv2D(16, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
net = bottleneck(net, 16, 24, (2, 2), shortcut=False, zero_pad=True) # block_1
net = bottleneck(net, 24, 24, (1, 1), shortcut=True) # block_2
net = bottleneck(net, 24, 32, (2, 2), shortcut=False, zero_pad=True) # block_3
net = bottleneck(net, 32, 32, (1, 1), shortcut=True) # block_4
net = bottleneck(net, 32, 32, (1, 1), shortcut=True) # block_5
net = bottleneck(net, 32, 64, (2, 2), shortcut=False, zero_pad=True) # block_6
net = bottleneck(net, 64, 64, (1, 1), shortcut=True) # block_7
net = bottleneck(net, 64, 64, (1, 1), shortcut=True) # block_8
net = bottleneck(net, 64, 64, (1, 1), shortcut=True) # block_9
net = bottleneck(net, 64, 96, (1, 1), shortcut=False) # block_10
net = bottleneck(net, 96, 96, (1, 1), shortcut=True) # block_11
net = bottleneck(net, 96, 96, (1, 1), shortcut=True) # block_12
net = bottleneck(net, 96, 160, (2, 2), shortcut=False, zero_pad=True) # block_13
net = bottleneck(net, 160, 160, (1, 1), shortcut=True) # block_14
net = bottleneck(net, 160, 160, (1, 1), shortcut=True) # block_15
net = bottleneck(net, 160, 320, (1, 1), shortcut=False) # block_16
net = tf.keras.layers.Conv2D(1280, 1, use_bias=False, padding='same',)(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.PReLU(alpha_initializer=tf.initializers.constant(0.25))(net)
return input_node, net
input_node, net = get_mobilenetV2_prelu((224,224,3))
net = tf.keras.layers.GlobalAveragePooling2D()(net)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[input_node], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
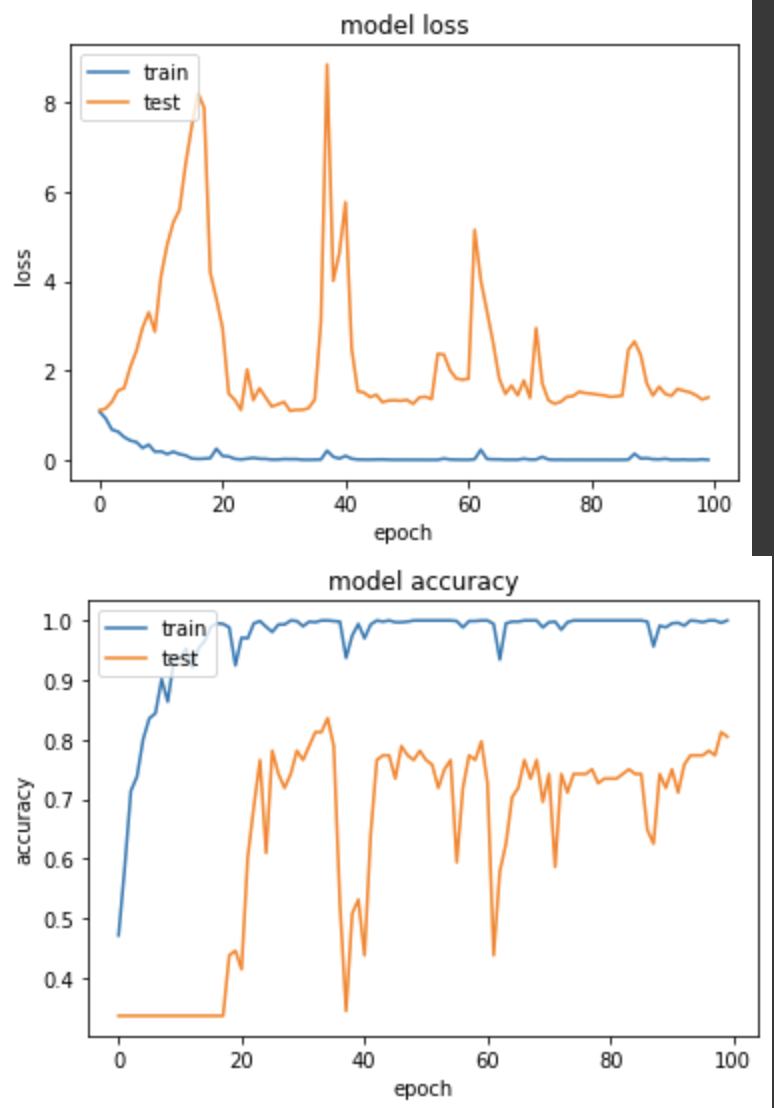
產出:
Epoch 99/100
loss: 0.0119 - sparse_categorical_accuracy: 0.9961 - val_loss: 1.3487 - val_sparse_categorical_accuracy: 0.8125
實驗四:SELU
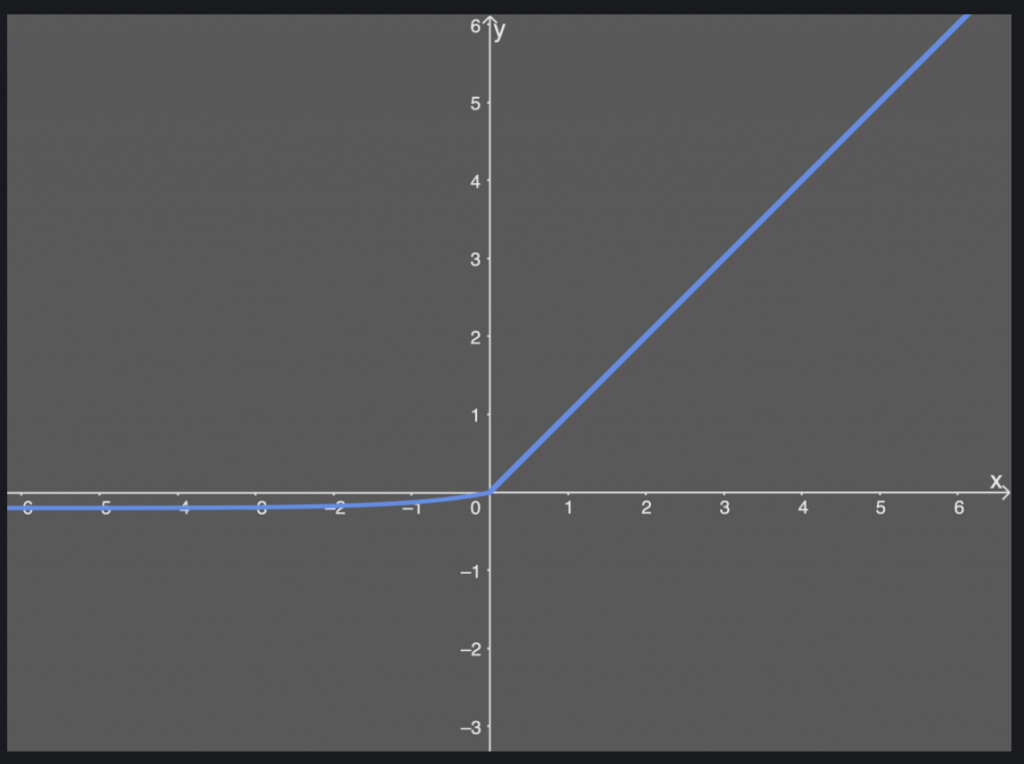
介紹 SELU 之前,要先知道他是 ELU 的一種,ELU在輸入小於0時,會是一個 exponential 形狀,所以在計算量上都會比較大,ELU 的公式如下:
而 SELU 公式和 ELU 差不多,只是原作者找到了一個確切的 α 數值和一個固定的 λ 值來做縮放,而且在使用這個 act func 時,前面的權重初始化要使用 lecun_normal,如果有用過 dropout 則是要替換成另一種 AlphaDropout。
def bottleneck(net, filters, out_ch, strides, shortcut=True, zero_pad=False):
padding = 'valid' if zero_pad else 'same'
shortcut_net = net
net = tf.keras.layers.Conv2D(filters * 6, 1, use_bias=False, padding='same', kernel_initializer='lecun_normal')(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.activations.selu(net)
if zero_pad:
net = tf.keras.layers.ZeroPadding2D(padding=((0, 1), (0, 1)))(net)
net = tf.keras.layers.DepthwiseConv2D(3, strides=strides, use_bias=False, padding=padding, kernel_initializer='lecun_normal')(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.activations.selu(net)
net = tf.keras.layers.Conv2D(out_ch, 1, use_bias=False, padding='same', kernel_initializer='lecun_normal')(net)
net = tf.keras.layers.BatchNormalization()(net)
if shortcut:
net = tf.keras.layers.Add()([net, shortcut_net])
return net
def get_mobilenetV2_selu(shape):
input_node = tf.keras.layers.Input(shape=shape)
net = tf.keras.layers.Conv2D(32, 3, (2, 2), use_bias=False, padding='same', kernel_initializer='lecun_normal')(input_node)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.activations.selu(net)
net = tf.keras.layers.DepthwiseConv2D(3, use_bias=False, padding='same', kernel_initializer='lecun_normal')(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.activations.selu(net)
net = tf.keras.layers.Conv2D(16, 1, use_bias=False, padding='same', kernel_initializer='lecun_normal')(net)
net = tf.keras.layers.BatchNormalization()(net)
net = bottleneck(net, 16, 24, (2, 2), shortcut=False, zero_pad=True) # block_1
net = bottleneck(net, 24, 24, (1, 1), shortcut=True) # block_2
net = bottleneck(net, 24, 32, (2, 2), shortcut=False, zero_pad=True) # block_3
net = bottleneck(net, 32, 32, (1, 1), shortcut=True) # block_4
net = bottleneck(net, 32, 32, (1, 1), shortcut=True) # block_5
net = bottleneck(net, 32, 64, (2, 2), shortcut=False, zero_pad=True) # block_6
net = bottleneck(net, 64, 64, (1, 1), shortcut=True) # block_7
net = bottleneck(net, 64, 64, (1, 1), shortcut=True) # block_8
net = bottleneck(net, 64, 64, (1, 1), shortcut=True) # block_9
net = bottleneck(net, 64, 96, (1, 1), shortcut=False) # block_10
net = bottleneck(net, 96, 96, (1, 1), shortcut=True) # block_11
net = bottleneck(net, 96, 96, (1, 1), shortcut=True) # block_12
net = bottleneck(net, 96, 160, (2, 2), shortcut=False, zero_pad=True) # block_13
net = bottleneck(net, 160, 160, (1, 1), shortcut=True) # block_14
net = bottleneck(net, 160, 160, (1, 1), shortcut=True) # block_15
net = bottleneck(net, 160, 320, (1, 1), shortcut=False) # block_16
net = tf.keras.layers.Conv2D(1280, 1, use_bias=False, padding='same', kernel_initializer='lecun_normal')(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.activations.selu(net)
return input_node, net
input_node, net = get_mobilenetV2_selu((224,224,3))
net = tf.keras.layers.GlobalAveragePooling2D()(net)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[input_node], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
產出:
Epoch 85/100
loss: 0.0018 - sparse_categorical_accuracy: 1.0000 - val_loss: 0.6651 - val_sparse_categorical_accuracy: 0.8672
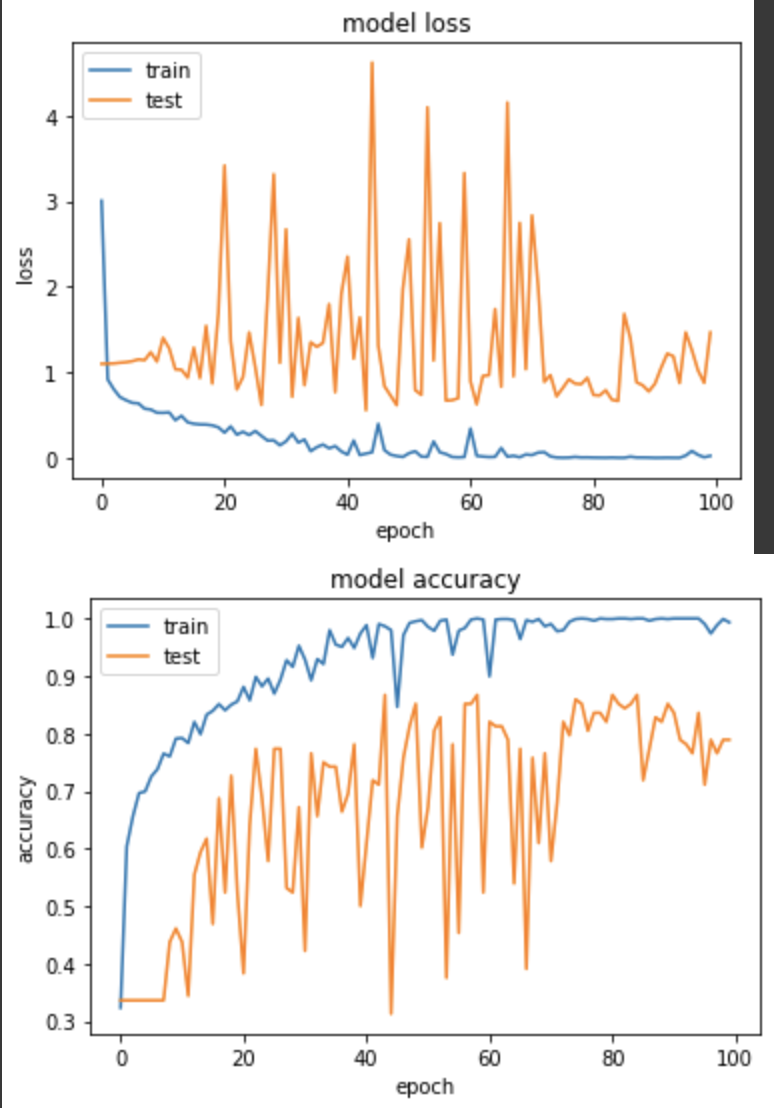
以上就是今天針對這四個不同的 ReLU 所做的實驗,大致上都有得到不錯的效果,今天如果你要處理的任務比較急或者是第一次訓練的話,或許還是基本款的 ReLU 就好,如果是相比 Kaggle 這種必須計較分數的比賽,那就很推薦嘗試一些新的手法來訓練。


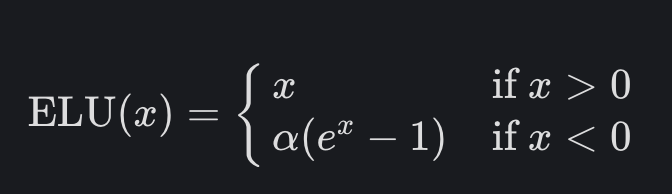
 iThome鐵人賽
iThome鐵人賽