嗨大家!經過幾天這系列文章第一天提到過NLP的目標就是要讓電腦可以像人一樣理解並處理語言,而想做到這樣的事情就需要語言學的規則來幫忙。這其實是NLP領域最開始發展的時候大家做的事情。工程師跟語言學家合作,透過語言學家統整出的語言規則來編寫程式,幫助電腦處理語言。但是隨著時間的演進,大家漸漸開始發現因為語言的變化性跟人的創造力太高,只靠語言規則來做NLP沒辦法達到很好的效果。因此開始有人把統計方法-也就是機器學習(Machine Learning)引進到NLP領域裡面。
所謂的機器學習跟人類學習東西其實滿相似的。一般來說我們最容易學到東西的途徑不是課本或媒體,而是生活經驗。例如當我們看見天空陰陰的☁就知道可能要下雨了。機器學習在做的事情也是如此,他們會透過經驗去學習怎麼完成我們安排的任務。而這個經驗的來源就是我們提供給機器的數據跟資料。簡單地說,機器學習泛指我們透過數據和資料,用統計方法幫助電腦學會完成任務並提升成效的方法。
機器學習的大致流程就像下面這張圖一樣。當我們有一個資料集的時候,通常會先清理過資料(整理並留下對我們有用的東西)再把它分成兩個部分,一個部分用來提供給電腦當作訓練用的經驗(訓練集,training set);另外一個部分則是在模型訓練好之後用來測試訓練成果(測試集,test set)。一般來說訓練集跟測試集的比例會是8:2或7:3,雖然要隨機取出來,取出來的資料比最好還是要跟原資料相近比較好。也就是說,如果今天我要讓機器學會分辨正常訊息跟垃圾訊息,我收集到的資料裡面有60%是正常訊息、40%是垃圾訊息,那我分出來的訓練集跟測試集裡面也要是六比四的正常訊息跟垃圾訊息。這樣才不會我們隨便取資料出來,結果發生訓練集裡只有正常訊息、測試集裡面只有垃圾訊息的窘境。
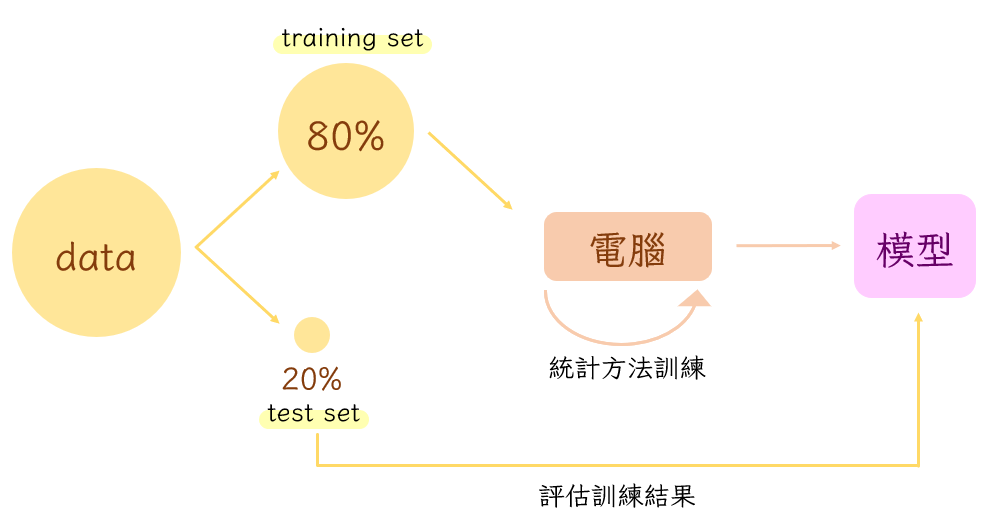
分好資料之後就進入到訓練機器的步驟了,這個地方有很多不同的統計模型可以選擇(例:決策樹、SVM等),之後的文章裡面會再詳細介紹。經過訓練的機器,我們會稱他們為訓練好的模型(model)。而測試模型成效的方法就是拿測試集讓他們實際完成任務,再評估成效(evaluation)。
機器學習根據投入資料類型的不同,主要可以分成兩大類,監督式學習(supervised learning)跟非監督式學習(unsupervised learning),下面就簡單介紹它們的差異。
監督式學習就跟它的名字一樣,指的是受到監督的學習。這個類型的機器學習在我們做完資料清理之後還會有一個標記(annotation)的步驟。所謂的標記就是幫資料貼上一些標籤,並且告訴電腦哪些是正確答案,哪些不是。舉例來說,當我們發現垃圾信件可能會有比較多驚嘆號跟問號的使用,我們可以幫每一筆資料都貼上是否有驚嘆號的標籤跟是否有問號的標籤。在標記結束後我們會把資料跟標籤一起丟給機器,讓他透過這些標籤去找到一個判斷信件是不是垃圾訊息的方法。因為我們已經先幫電腦決定好要走的路了,所以叫做監督式學習。
監督式學習的缺點在於人工標記語料通常需要花費較大的時間跟人力成本。此外,因為標記是透過我們對現成語料的觀察去做出來的,我們無法知道是不是有些特徵其實只存在這些資料中或是不包含在這些資料中,所以當有新的資料要拿來讓模型分類的時候,結果出來可能就比較沒有那麼好。也因為監督式學習的模型是我們一個口令一個動作訓練出來的,它們大多只能用來進行分類任務,不具有創造性。使用監督式模型的好處在於,因為從一開始就是從我們的指導開始,當出現問題的時候我們比較能插手找出癥結點並修正問題,所以通常監督式學習可以達到比較高的成效。
常見模型: Naive Bayes, SVM, Logistic Regression, Decision Tree, Random Forest
非監督式學習跟監督式學習不同,我們訓練機器的方法跟放任式教育的家長很像,基本上就是讓小孩自己找路走。也就是說拿到資料之後我們只會進行資料清理就把資料交給電腦,剩下的要怎麼完成任務就全看電腦的算法去決定。
非監督式學習的優點在於不需要標記資料,能極大程度地節省時間跟人力成本。也因為整個過程都是他自己摸索出來的,模型算是對資料有自己的了解,所以非監督式學習的模型可以用在比較具有創造性跟彈性的工作上,例如:生成文本。當然在遇到新資料的時候,非監督式學習的模型也比較具有調整的彈性空間。而它的缺點在於,我們沒有辦法掌握模型真正的分類依據。即便可以透過分類結果去歸納出資料之間的關聯性,我們還是沒有辦法100%確定機器是不是跟我們一樣這樣想。這樣的結果就是,萬一機器其實根本就搞錯重點,在加入新資料之後絕對會走上歪路。另外,相較於監督式學習的模型,我們也較難針對訓練過程找出問題,提高非監督式學習模型的成效。
常見模型: Cluster Analysis(聚類分析), GAN(生成對抗網路), Topic Modeling(主題模型)
針對機器學習的簡單介紹就到這邊告一個段落,如果有問題的話歡迎在下面留言提出。明天會接著介紹機器學習成效的評估方式,那就明天見啦~


 iThome鐵人賽
iThome鐵人賽