嗨!昨天簡單介紹過機器學習之後,今天就來跟大家分享評估成效幾個比較常見的計算方法。
不知道大家以前有沒有看過牛奶花生的廣告,就是那個用電腦選花生的廣告。
如果用電腦幫我們挑選好的花生來當作牛奶花生的原料,可能會產生的結果有以下四種:好花生被挑出來、好花生沒被挑出來、壞花生被挑出來、壞花生沒被挑出來。我們有四個詞是專門用來形容這四個情況的,而運用這四的數字就可以完成四種模型的評估方式。
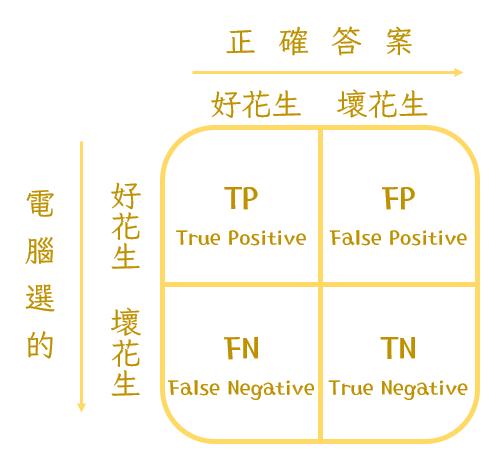
Accuracy 指的就是在所有花生裡面,我們正確挑出好花生跟壞花生的比率,所以它的計算方法是:
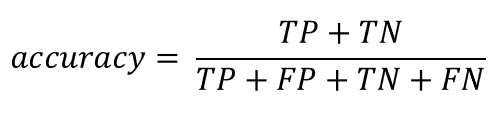
基本上這跟我們平常考試的計分方式相同,看起來也滿公正的。既然這樣,為什麼我們會需要其他算法呢?請大家設想一個情況:如果供應牛奶花生的農場生產的花生品質本來就很好,好花生的比例高達9成,那是不是電腦只要把所有花生都判斷成好花生也可以得到90%的正確率呢?在這個情況之下,雖然電腦的正確率高達90%,它其實根本沒有辨別壞花生的能力。也就是說,當資料裡面類別比例不平衡的時候,正確率可能就不是一個評估模型表現的好選項。所以下面兩個評估方式就出現了。
Precision 指的是在我們拿到的牛奶花生裡面,真的好花生的比率。也就是我們能相信模型預測為真的程度:
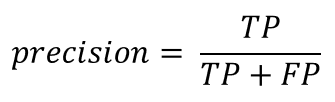
Recall 指的是真的好花生被正確挑出來的比率。也就是模型對真實的敏感度:
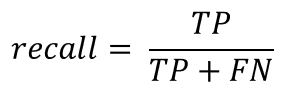
雖然precision跟recall都是以好花生作為判斷基準,但兩者之間是有差異的。先從precision說起,如果仔細看公式的分母,會發現被誤判為好花生的壞花生也佔有一席地位。當FP的值越大,precision就越低。也就是說,precision在意的其實是電腦不小心把多少壞花生放到產品裡面。這對愛之味的公關部門來說會是一個滿重要的指標,畢竟不能讓消費者吃到壞掉的花生之後來投訴嘛。
接下來看到recall的分母。這邊具有影響力的是沒被選出來的好花生。當沒被選出來的好花生越多,recall就越低,所以recall在意的是有多少明明是好花生卻被丟掉的原料。這個部分對愛之味的財務部門來說可能就會是比較重要的指標,因為丟掉的花生越多,要再購買的原料就越多。他們當然希望電腦的recall可以高一點,這樣就能減少購買原料的花費。
雖然說公關部門跟財務部門並不相同,所以注重的東西也不一樣,但愛之味終究是一間公司,一定會希望能找到最大程度滿足所有部門的工作方式嘛,所以就有了f-score的誕生。這邊使用的是他們的調和平均數。也就是倒數相加之後取平均再倒數回來的值(經過一番計算之後會等於兩者相乘的值除上兩者相加的值再乘2)。
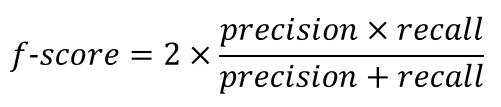
以上就是四種最常用的模型評估方式,通常大家會做的事情就是把他們四個值都算出來,分別去看模型在不同方面的表現好壞。
接下來我們就實際來計算看看這四種模型評估方式吧!假設在1000粒花生裡面有700粒好花生跟300粒壞花生,愛之味的電腦挑出的好花生裡面有680粒是真的好花生,50粒是壞花生,這台電腦的accuracy、precision、recall跟f-score分別是多少呢?看到這邊你可能覺得有點暈頭轉向,沒關係!當我們要評估模型表現的時候,最先做的事情就是畫出混淆矩陣(confusion matrix)。也就是把實際的數字填入上面那張好花生壞花生的表格裡面,像這樣。
| 真的好花生 | 真的假花生 | |
|---|---|---|
| 電腦挑的好花生 | 680 (TP) | 50 (FP) |
| 電腦挑的壞花生 | 20 (FN) | 250 (TN) |
接下來只要照著公式走就對了~

實際計算過後大家應該都比較熟悉這四個模型評估方式了,那麼今天就到這邊告一個段落。有問題一樣可以在下面留言提出,明天開始會正式進入資料前處理的相關教學~掰掰!


 iThome鐵人賽
iThome鐵人賽