昨天的 AI 歷史讓我們知道,AI 已經在棋盤遊戲上贏過世界頂尖棋士甚至擊敗世界冠軍。那麼你知道當初在黑白棋,西洋棋,將棋,圍棋哪個是 AI 最難擊敗人類的嗎?先讓我們看看 AI 是如何辦到的。
在第一次 AI 浪潮中,最先想到的是試著讓電腦解決迷宮問題。所以需要將迷宮轉換成電腦看得懂的形式。像這樣將每個分歧點以及死路給一個符號,並將路線連結起來成為一個樹的結構,這個樹我們稱為搜尋樹。
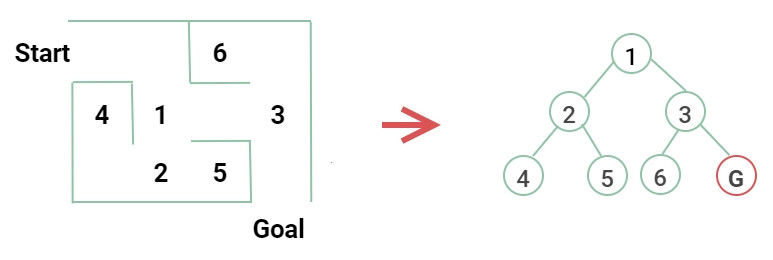
本系列文的說明範例,為了方便理解,盡可能製作比較簡單的圖例來說明。
要從起點走到出口,基本2種的走法就是先橫著走(廣度優先搜尋)和先往下走(深度優先搜尋)。
廣度優先搜尋(簡稱 BFS,Breadth First Search)
先把這層的走完再走下一層。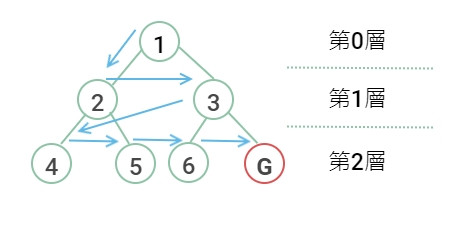
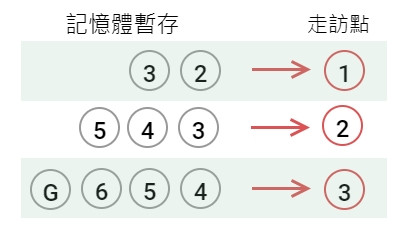
深度優先搜尋(簡稱 DFS,Depth First Search)
總之先往下一層走,直到不能走再回上一層換方向。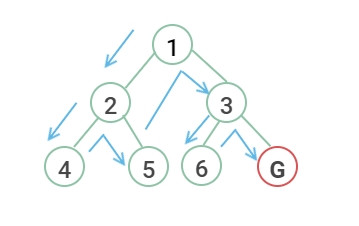
BFS 和 DFS 都可以選擇先從左或先從右走,如果出口靠右的話,先從右走會比較快找到答案。
利用這兩種搜尋法只要一直走,總有一天可以把所有路線組合走完找到出口。像這種沒有什麼技術,把所有可能性列出來靠著計算能力硬跑完一遍實在太暴力了,所以又叫做暴力法(Brute force)。但是這種解法蠻直觀的,早期還沒有最佳解的演算法時找答案都是靠這種方法。
搜尋樹也可以用來解河內塔問題,河內塔問題是有3個柱子,在第一個柱子套上大小圓盤。
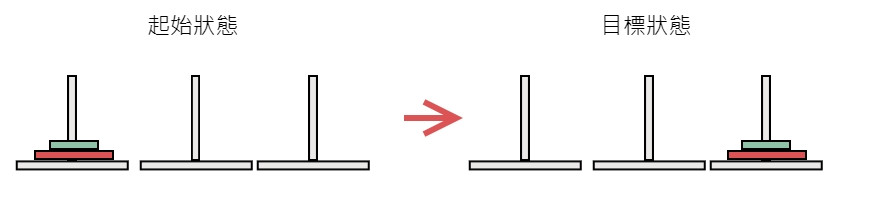
找出把圓盤搬到最右邊柱子的方法。
所以把河內塔轉換成電腦看得懂的形式,把三個柱子當成 A, B, C。把2個圓盤標示所在柱子(A, A),那麼將小圓盤移到 B 就變成(B, A),或是將小圓盤移到 C 就是(C, A),於是河內塔的搜尋樹就產生了。
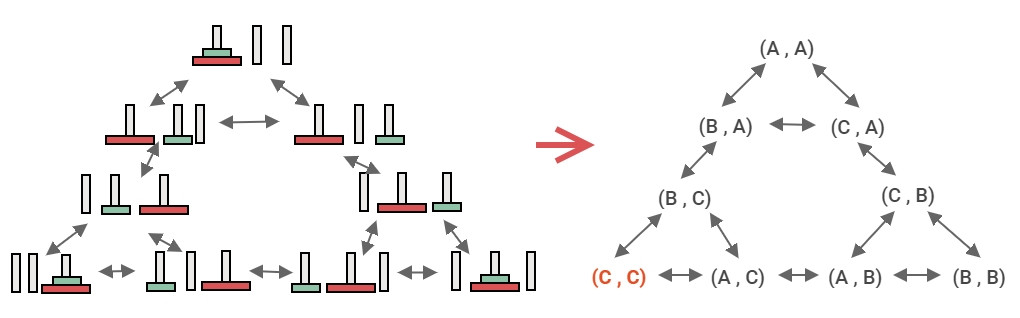
河內塔號稱工程師一生要爬一次的塔(笑)。第一次 AI 浪潮誕生了很多有用的演算法,搜尋樹就是基本的演算法之一。
還記得一開始問的問題嗎,棋盤遊戲對 AI 來說哪個最難呢?棋盤遊戲基本上也是採用搜尋樹的方法,所以關鍵就在於棋盤的大小和棋子的種類共有多少可能性的組合。
等等...10的3次方就是3個零也就是1千,10的8次方就是1億了。上面的數字是在開玩笑嗎?這些組合數字實在大到像天文數字,已經沒有辦法靠暴力法解決一切問題了。光是計算所有組合可能有生之年都看不到結果,所以有效的減少搜尋的次數就是一個很重要的議題。
這邊就需要投入成本的概念,就像台北移動到高雄可以搭高鐵,坐巴士,根據所選擇的手段從時間和金錢來評估成本。成本高的路線就捨棄不碰。這種事先靠經驗判斷成本來減少搜索的方式稱為啟發式(Heuristic),因為成本是靠人給的猜想分數,找出的可能不會是最佳解,但可以大幅減少需要的計算時間。
這邊的猜想分數就是讓電腦參考過去比賽的棋譜,由人告訴電腦這樣的局面分數高還是低。
由於棋盤遊戲和迷宮問題不同,是有對手的,所以搜尋樹就變成你這回合下什麼位置,下回對方可能會下什麼的位置的組合所形成。而為了擊敗對手,需要取得最高的分數(成本),因此在自己的回合應該選擇下在分數最高的那一格(MAX)。但是對手不是笨蛋,他的回合肯定會下在讓你分數最少的那一格(MIN),這就是 MIN-MAX 法。
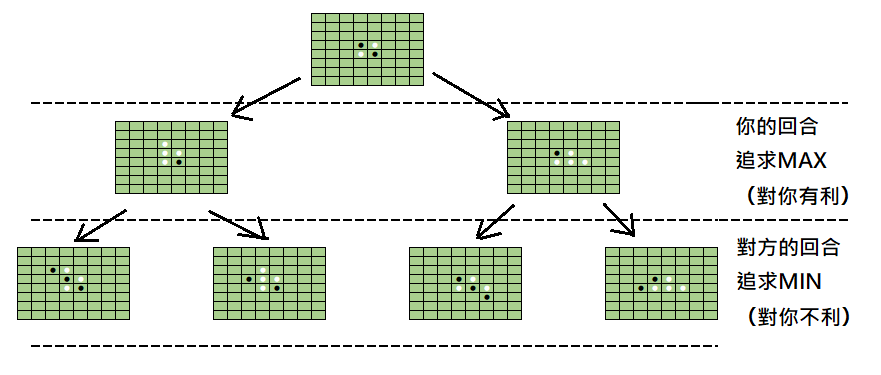
而透過 MIN-MAX 法,我們可以將像修剪樹木一樣將不需要搜索的樹枝給剪掉,減少搜索的次數。這種修剪法我們稱作 Alpha–beta 修剪(Alpha–beta pruning)。
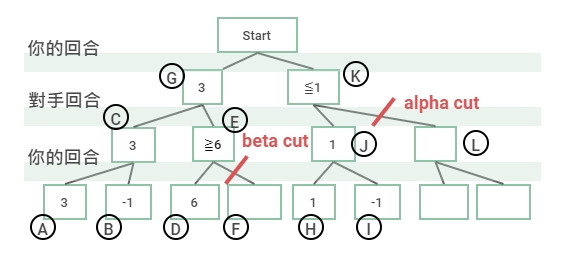
Beta Cut
選擇最大分數時,前一回合已經有更小分數的節點出現,則省略不搜尋。
上圖假設使用左邊開始的深度優先搜尋。
Alpha Cut
選擇最小分數時,前一回合已經有更大分數的節點出現,則省略不搜尋。
早期的黑白棋,西洋棋,AI 使用這種手法都得到了不錯的效果。但是大魔王的圍棋還是沒能有效獲勝人類玩家,所以又延伸出其他方法。
蒙地卡羅這名字其實是一個賭場的名字。我每次看到這個名字都忘記是幹嘛的,所以都用賭場來聯想。簡單來說就是使用大量的隨機抽樣,來逼近真實情況的方式。例如拋硬幣會隨機出現正反面,如果只拋一次出現正面,那正面以統計來看就是機率100%,但是我們知道正反面應該是要各50%的機率,而拋了無數次之後,正反面出現的機率會趨近於理論值的一半一半。
圍棋有分 19×19 棋盤和 9×9 棋盤,可就算是 9×9 棋盤,明明組合數比西洋棋少了,還是很難贏初階的職業棋手。這個原因在於圍棋的分數(成本)的評估問題。以往的方法是事先輸入各種對戰棋譜,由人先來評價該情況得多少分,因為是人憑著經驗去給的猜想分數,導致對戰的結果不同。
之後 AI 完全放棄傳統事先靠人評估分數的方法,而是採用蒙地卡羅方法,由電腦模擬兩個人對戰,雙方隨機下在某個位置,總之先讓遊戲進行到結束(Playout), 這樣讓遊戲結束好幾次,計算哪種下法勝率最高來獲得分數。結果利用這種方法,9×9 的圍棋,AI 可以達到等同職業棋士的水準。
但即便使用蒙地卡羅法,19×19 棋盤的圍棋組合還是太龐大了,最後還是加上深度學習自動找到更好的特徵才完成擊敗頂尖棋士的創舉。
AlphaGo 還是有用到人類棋譜,評分則是 AI 用學習的,發展到 AlphaGo Zero 則是連棋譜都不使用。


 iThome鐵人賽
iThome鐵人賽