對於數據分析師我覺得最容易訓練解題過程的方式就是利用 Kaggle,我相信數據分析師對於 Kaggle 應該不會太陌生,我認為 Kaggle 最具有價值的地方就是可以參考不同國家與不同世界的人,會利用不同的方法去解決相同的問題,也有非常大量的資料來源,可以進行近一步的分析,是訓練基本功的好地方。
剛好有找到一個不錯的內容是關於 Titanic 的資料集,我們首先先到 Kaggle內下載資料檔案,在底下的 Data Explorer 中下載 train.csv 並且利用 Google Sheet 打開它。
在「Book Data Science Solutions」這中有解釋到數據工作流程一共有七個階段。
1.問題定義 (Definition)
2.獲取數據 (Acquiredata)
3.清理數據 (Clean data)
4.分析定義 (Analyze and identify)
5.模型預測 (Model predict)
6.可視化圖 (Visualize)
7.提交結果 (Results)
在開始定義問題前,我們要先了解這份資料的架構意義,如果我們利用 GoogleSheet 或是 Excel 開啟,在鐵達尼號的資料集中可以看見有許多不同的資料標題,在這樣的情況下我們資料標題我們能夠從標頭位置去做判斷,在這裡我使用 GoogleSheet 開啟。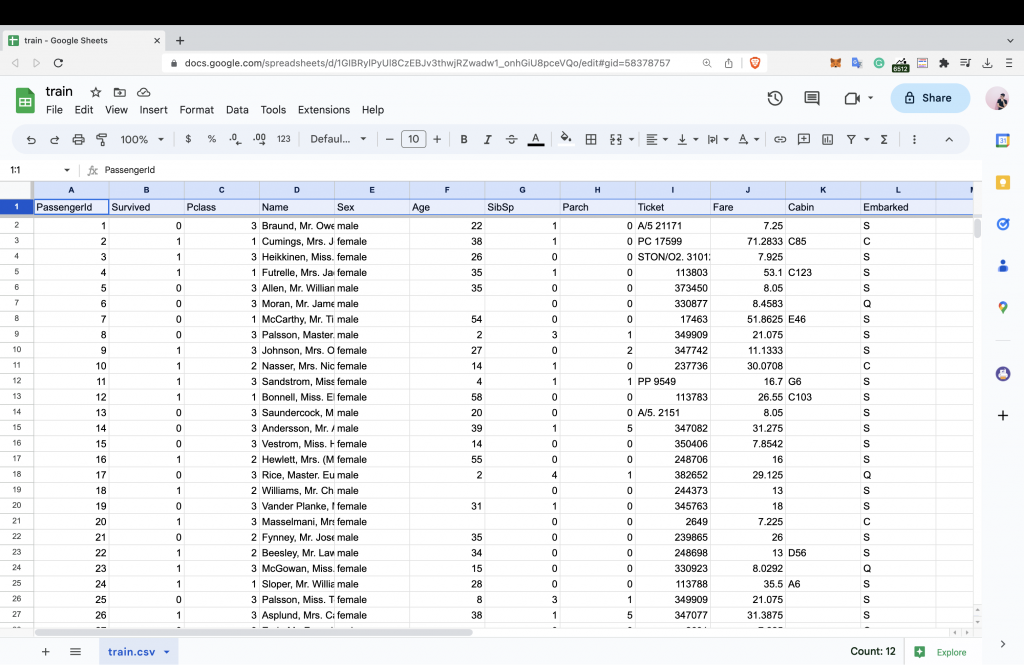
有了這些資料集與標頭,我們就能夠開始進行資料分類(上方提到的A.分類),因為不同類別與我們解決目標的影響或相關性,將樣本劃分為類似的樣本集。你可以考慮在分類特徵中,這些數值是有助於我們進行可視化圖表的?我們先大致將資料做簡單分類。
其中幾個特徵可以作為他的維度 dimension
像是 Survived, Sex, Embarked, Pclass 皆為分類型
而在 Age, Fare, SibSp, Parch 則是具有連續性的數字特徵。
在資料型態中我們可以檢測我們的樣本或特徵中的任何異常值。所謂的異常職包含了哪些特徵是空白、無效或空值?這些將需要提前先確認。對於 Excel 來說比較不容易進行樣本異常分析,但是我們還是可以藉由一些方式來快速驗證一下資料,來看看可能存在的資料空值會有哪些。我們利用 Excel 開啟資料集後先拉到最底部然後設定幾個公式看看。
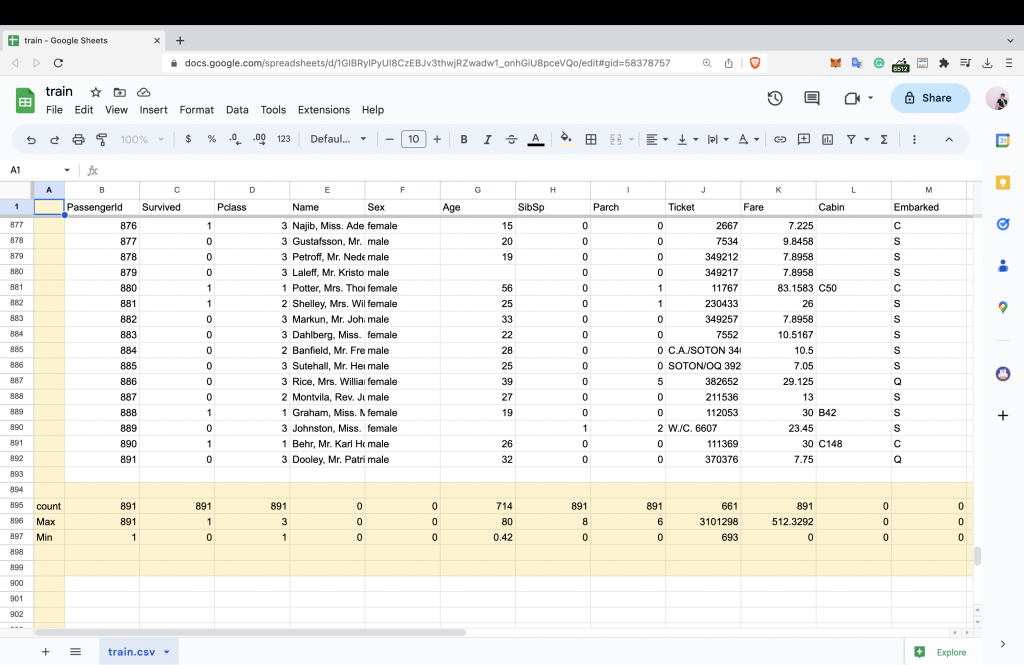
這邊應用三種簡單公式就能先快速歸納,但要注意他們只能運算數字特徵
以乘客編號為基準來看,我們很快可以找出幾個問題:
- 船票分類(Pclass)分為了 1,2,3 三種不同等級
- 年齡(Age)資料並不齊全只有 714 筆資料,而且最大年齡 80 歲,最小年齡僅有 0.42 歲
- 船票價格(Fare)從 0 元到 512 元都有
可以發現到整個資料集從 Excel 的列表中一共有 892 列,扣除掉最上方的標頭,所以可以確定這份資料集中鐵達尼號的乘客人數為 891 人。而其中我們可以快速注意到整體資料 Age,Cabin, Embarked 欄目中有部分數值缺少。
今年沒組團,每一筆一字矢志不渝的獻身精神都是為歷史書寫下新頁,有空的話可以走走逛逛我們去年寫的文章。
Jerry 據說是個僅佔人口的 4% 人口的 INFP 理想主義者,總是從最壞的生活中尋找最好的一面,想方設法讓世界更好,內心的火焰和熱情可以光芒四射,畢業後把人生暫停了半年,緩下腳步的同時找了份跨領域工作。偶而散步、愛跟小動物玩耍。曾立過很多志,最近是希望當一個有夢想的人。
謝謝你的時間「訂閱,追蹤和留言」都是陪伴我走過 30 天鐵人賽的精神糧食。

