打開 Spotify,我們會看到許多推薦歌單和 Podcast 節目,他們怎麼知道用戶會喜歡什麼呢?

Spotify 不遺餘力地搜集各式各樣的資料,資料分為 internal data 和 external data。
誠如昨天所述,multi-armed bandit 是在平衡 exploitation 和 exploration。昨天是以挑選餐廳舉例,回到 Spotify,他們有以下兩種行為:
讓我們先退一步來思考,為什麼不能只 exploit 呢?如果已經根據用戶的播放紀錄,建立預測模型,不能只推薦有十足把握、認為用戶會喜歡的歌嗎?為什麼要加上 explore 呢?
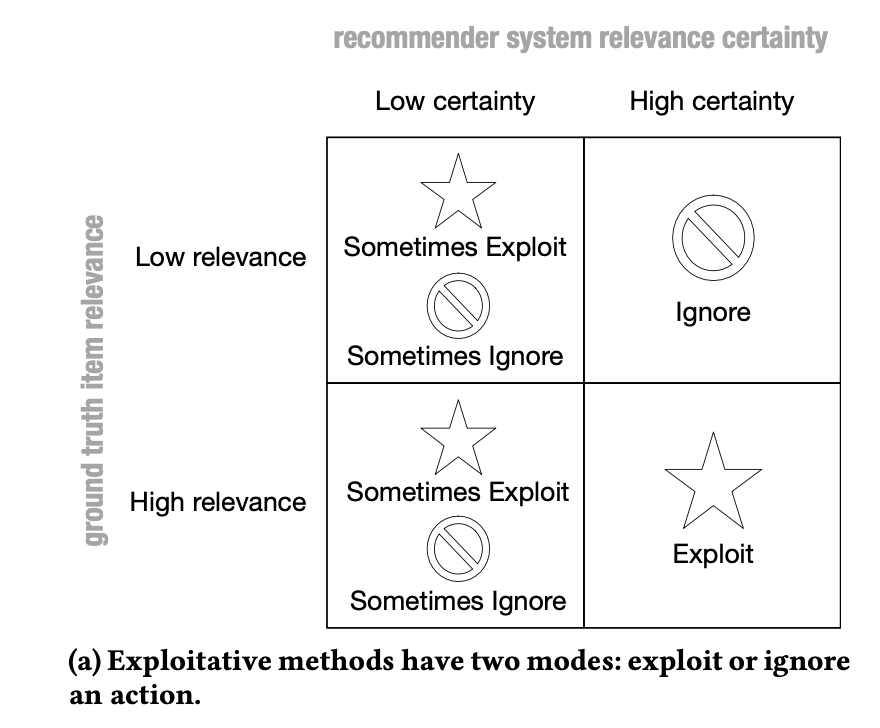
倘若只有 exploit,則模型只有兩種選擇:exploit 或 ignore。
以下圖為例,在模型有高度信心(圖的右半邊)時,較不相關的內容(右上)可以直接忽略,因為其真實值(ground truth)也真的是低相關。
然而,在模型的信心較低(左半邊)時,有時會忽略真實是高相關的內容(左下)。
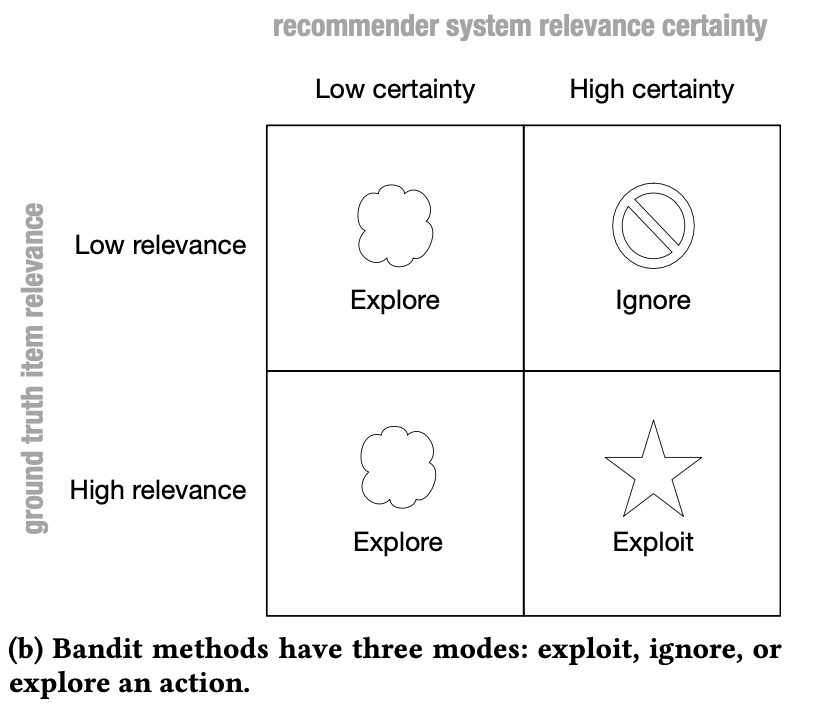
如果新增 exploration 的選項,就不會有忽略高相關內容(左下)的問題。因為在左半邊的兩格中,儘管預測模型的信心都不高,但是由於都會 explore,不用擔心會被忽略的問題。
儘管 exploration 是帶有不確定性的,然而對於新用戶、新項目(如音樂或影片)而言,還是重要的探索。
再者,Spotify,發現,如果能夠告知推薦原因,能讓使用者更理解推薦系統的邏輯,讓他們更願意相信、提升參與度,並提升滿意度跟說服力。
因此,除了原本的 multi-armed bandit 以外,Spotify 加入 explanation,建構出 Bart 模型(BAndits for Rescplanations, Rescplanations 是 explanation for a recommendation 的縮寫 )。
訓練資料的建構方式是將使用者 u 和解釋 e 配對,再將其對應到相應的歌曲清單 J。
如下圖為例,解釋 e 為「你朋友喜歡的電影(Movies your friends love)」,使用者 u 為 user123,對應到的歌曲清單 J 則為「受到 user123 朋友歡迎的電影(Movies that are popular with user123's friends)」。

你可能會有一個疑問,為什麼不直接把所有歌曲清單 J 都跟每個解釋 e 配對呢?因為有些解釋只適合某些特定的清單,不適用於全部。舉例而言,「因為你最近讀過歷史小說(because you recently read historical fiction)」是和歷史小說有關清單的唯一解釋,不適用於其他清單。
在建構好資料樣貌之後,Spotify 希望能夠建立一個機器學習模型,客製化地排序解釋和推薦清單,並要考量到脈絡,脈絡包使用者特徵、推薦清單特徵、一天當中的時間、播放平台等等。
Bart 的目的是預測任意歌曲清單(i ∈ J)、解釋(e ∈ E) 和脈絡(x ∈ X) 的結合之使用者滿意度(e.g., click through rate、消費的可能性),其 reward function r 為 J x E x X。
主要建構於 MAB(multi-armed bandit) 上,MAB 的目的是最大化最後的 reward。如前一天介紹過的,有不同架構,例如 epsilon-greedy 或 upper confidence bound。
然而,MAB 被批評說會忽略脈絡,因此提出一個新的概念為 contextual bandit,這個會在做行為之前先考慮並觀察 X。
結合脈絡(context)後,reward function 最終形態如下:
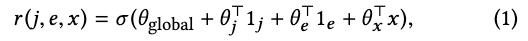
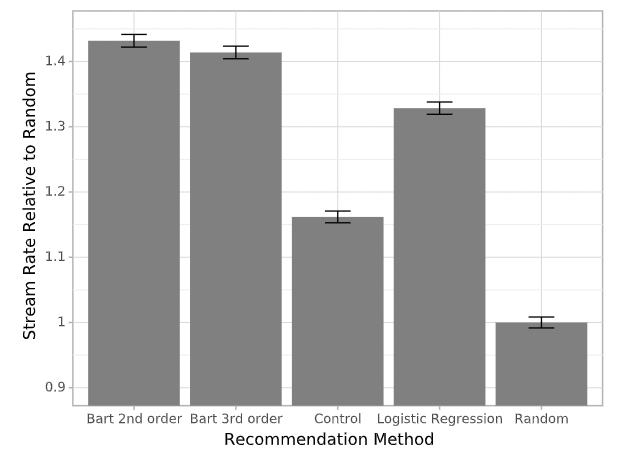
Spotify 比較三種不同模型/reward functions 的成效,分別為logistic regression 和兩個不同加權脈絡 x 的方式。
(1) Logistic regreesion:利用 logistic regression 的分數排序
(2) Bart 2nd order:Bart 模型,使用 2nd order factorization machine reward function
(3) Bard 3rd order:Bart 模型,使用 3rd order factorization machine reward function
計算細節我們不會在此討論,有興趣了解的人可以去參考原始 paper。
總之,為了簡化模型,MAB 使用 epsilon-greedy 架構,並使用 counterfactual risk minimization (CRM) 訓練模型。
好了,說了這麼多,讓我們來看結果吧!
實驗場景分為 offline 和 online,在兩個場景中,顧客參與度都有大量提升。
所謂的 offline 就是用過往留存的資料,用已知資料預測用戶行為,再比對他們的實際狀況。而 online 模型就是真的在用戶使用時即時搜集資料。
來看幾個有趣的發現。
下圖是他們比較的七種解釋,並在做卡方檢定後,結果顯示可以拒絕此虛無假設(不知道這是什麼嗎?Day 8 的文章有詳盡解釋)。換句話說,不同解釋和流量是有關的。

但是,說不定只是歌曲清單內容本身吸引人,跟放什麼解釋無關,因此他們又做了以下的假設。
他們針對有多個不同解釋的歌曲清單做研究,共有兩個清單:
結果顯示,第一組清單的虛無假設被推翻,所以儘管歌曲內容完全相同,不同解釋是會影響用戶的收聽意願。
然而,第二組的虛無假設無法被推翻,但是也很合理,因為 mood 和 focus 都是相對相似,且較模糊的敘述。
最後,來看功能實際上線的結果,可以看到無論是以上三組的有比較好的播放流量!
以上,Spotify 使用 Bart 模型,利用 multi-armed bandit 方法,同時 exploit 用戶過往的播放歷史,和 explore 新的內容。並且,再結合 explanation,增加用戶的信任度和收聽意願,製作出許許多多的播放清單。
謝謝讀到最後的你,如果喜歡這系列,別忘了按下喜歡和訂閱,才不會錯過最新更新。
也歡迎到我的 medium 逛逛!
Reference:
J. McInerney et al., “Explore, exploit, and explain: personalizing explainable recommendations with bandits,” in Proceedings of the 12th ACM Conference on Recommender Systems, Vancouver British Columbia Canada, Sep. 2018, pp. 31–39. doi: 10.1145/3240323.3240354.


 iThome鐵人賽
iThome鐵人賽