支援向量機(Support vector machine, SVM)可以處理線性問題及非線性問題,由於變數之間大部分情況存在著相關性,因此模型運作概念為將資料從低維度空間中投影至高維度空間,使原本在低維度無法進行切割的資料,在高維度時能找到超平面來分開樣本,由於此篇將針對分類問題探討,因此將專注於支持向量分類(Support Vector Classification, SVC)
模型主要目的在於找到超平面,使得邊界(Margin最大化),讓兩邊樣本可以越分開,提升新資料放入模型時分類正確性。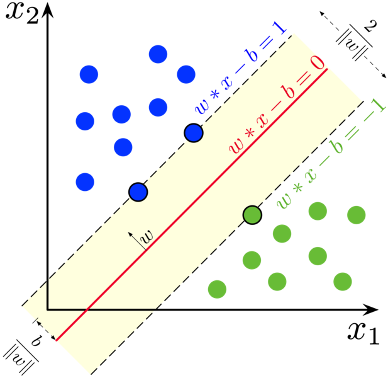
(圖片來源:連結)
SVM會找出類別之間最靠近的點作為(support vectors),接下來會在這些支持向量中找出最佳的分界,使分界與支持向量之間有著最大的邊界距離,而找出的分界就是SVM所找出的最佳解。而資料中常會出現離群值,為了避免分界受到離群值的影響,因此模型中放入一個超參數C進行控制,數學公式的部分在此則不多加說明。
當C越大時,會使模型偏向重視模型分錯所造成的損失,因此找出的分界會較貼近分類邊界的點;當C越小時,模型則可以容許一些離群值在訓練時被分錯,找到距離邊界最遠的分界,因此在調整參數C時會對於模型有較顯著的影響。
線性SVM為在二維空間上可以做到樣本的切割,當在低維度無法做到時,則會調整到高維度空間上運作,則被稱為非線性SVM。而將低維度空間轉換至高維度空間則需透過核函數(kernal function)來完成。
常見的kernal 為高次方轉換(Polynomial)及高斯轉換(Radial Basis Function)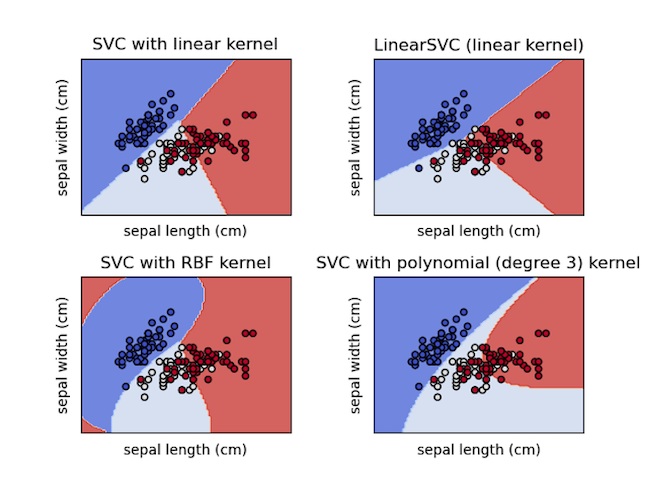
(圖片來源:連結)
e1071套件中的svmlibrary(e1071)
#模型
model_svm <- svm(formula = as.factor(Activity) ~ ., data = training)
#預測
pred_svm <- predict(model_svm,testing)
#衡量
confusionMatrix(pred_svm,reference = as.factor(testing$Activity))

sklearn.svm套件中的SVCfrom sklearn import svm
#模型
model_svm =svm.SVC(kernel='rbf',C=1,gamma='auto')
model_svm.fit(X_train,Y_train)
# 預測
pred_svm = model_svm.predict(X_test)
# 衡量
accuracy = metrics.accuracy_score(pred_svm,Y_test)
print(accuracy) ## 0.733453981385729


 iThome鐵人賽
iThome鐵人賽
{kind=link}