昨天我們做完了一個完整的文本分類的 transformer 了,也準確地預測具有負面意義的詩句,真的是太厲害了。今天我們來看看更方便的 Transformer 用法並解構之,以及如何在 TensorFlow 中加載模型。
我們昨天的程式碼,其實可以簡化成下面的方式。
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
classifier(
[
"Only those who will risk going too far can definitely find out how far one can go.",
"Baby shark, doo doo doo doo doo doo, Baby shark!"
]
)
會得到下面的結果:
[{'label': 'POSITIVE', 'score': 0.9813831448554993},
{'label': 'POSITIVE', 'score': 0.9183685779571533}]
注意到我們把昨天詩句中的那個 possibly,改成 definitely,就得到正面的結果。
這樣子的程式碼真的很簡單,就是我們在架環境時試跑過的那段程式碼。但是我們昨天完整地跑過一遍 transformer 的流程,會對於我們明天在做 fine-tuned transformer 時會更有幫助。
下面這張圖就是整個 transformer 的流程,而 pipeline 就是把它們包在一起,讓我們可以更加方便使用。如下圖。
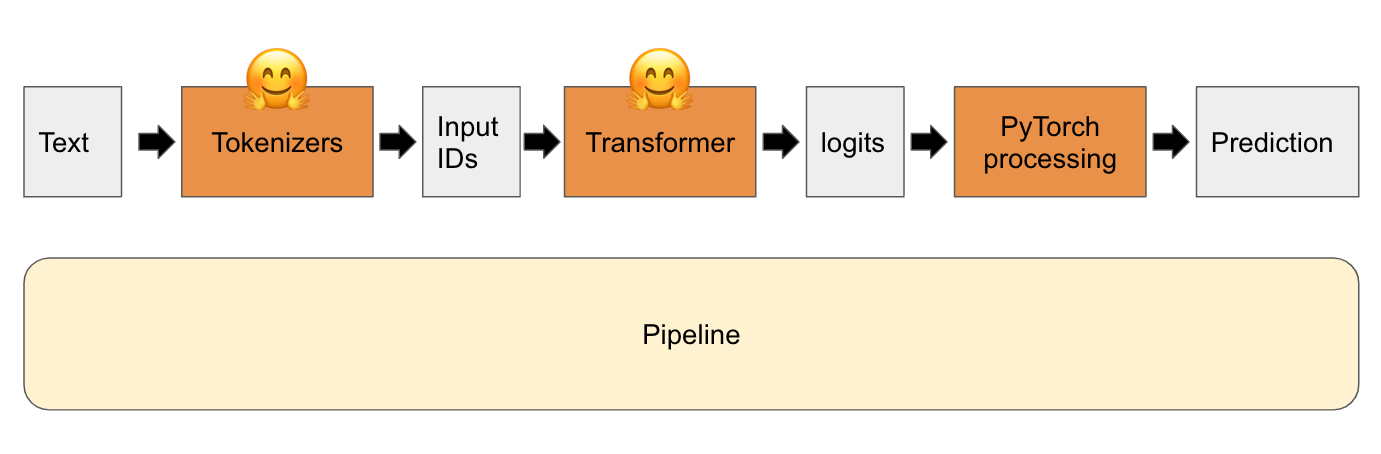
昨天我們的範例是加載了 PyTorch 的模型,之前有提到 Hugging Face 也支援 TensorFlow。今天我們就來看看如何加載 TensorFlow 的模型。
TFAutoModel 就可以載入想要的 transformer model 了。程式碼參考如下。from transformers import TFAutoModel
tf_model = TFAutoModel.from_pretrained(model_name)
xlm-roberta-base,就是只存在於 PyTorch 版本的 transformer。tf_model = TFAutoModel.from_pretrained("xlm-roberta-base", from_pt=True)
pt 一般就是指 PyTorch ,而 tf 是指 TensorFlow。許多內建的功能,都只要再加上 TF 的前綴,就會變成 TensorFlow 版本的功能了。一般支援的是 TensorFlow 2.0 之後的版本。今天的兩項功能,不禁讓人讚嘆 Hugging Face 真的太方便太好用了。明天我們就來看要如何 fine-tuned transformer 吧!又會是比較硬的內容了。

