哈囉大家,今天終於要正式進入模型訓練的階段了,真是可喜可賀,可喜可賀。雖然現在各種fancy的深度學習模型都非常強大,也能達到比機器學習還要好很多的成效,但機器學習終歸算是這個領域裡面元老一般的存在。而且這些模型的原理之間都有所關聯,如果能從最簡單部分開始打好基礎,後面在進入深度學習的時候也會稍微輕鬆一點(吧)。反正國小數學也是從1+1開始,所以NLP的模型訓練就從最經典的機器學習模型開始吧。
今天要介紹的是最常被用來當作baseline model的單純貝式分類器。在開始之前先名詞解釋一下什麼是baseline model。之前在講怎麼評估機器學習成效的時候介紹了accuracy, precision, recall, f-score這四種計算方法,但我們要怎麼知道算出來的數字到底是好還是不好呢?在學術界最常見的方法就是把它拿來跟其他模型比,因為數字大小的差異可以是我們的模型比別的模型好的重要指標。有可能是跟其他paper訓練出來的模型比較;也可能是針對有沒有使用目標特徵做比較;或者是選擇一兩種前人在相同目標下常用的模型做比較,而這些被用來凸顯我們模型成效的模型就叫做baseline model。至於單純貝式分類器為什麼經常被用來當作baseline model,讓我們繼續看下去。
前陣子Netflix的紀錄片《Tinder大騙徒》話題性超高,看到大家都在討論,我才發現原來很多人都有這方面的困擾。有沒有什麼方法可以放大家知道跟自己聊天的對象到底是想騙財騙色還是真的喜歡自己呢?後來我想起,《特殊戀人攻略》的作者提過自己故事裡面的PUA組織是真有其事。這些PUA組織專門在教沒心沒肺的男性透過話術欺騙女生的感情,藉此從他們身上榨取好處,感覺騙砲仔講話就會有一些他們的規律吧。不如我們就來試試看用貝式分類器的原理來鑑別騙砲仔好了(?
想用貝式定理識破騙砲仔的話,我們需要先理解全機率法則在幹嘛。全機率法則的內容簡而言之就是我們可以透過跟B事件互補且互斥的A事件來計算C事件發生的機率。
假設PUA男跟真誠男在交友軟體上面的比例是6:4,PUA男找你會講的第一句話是「在嗎?」的可能性是80%,真誠男找你的第一句話是「在嗎?」的可能性是50%,那隨便抽一個男生起來,他的第一句話會是「在嗎?」的可能性就可以用全機率法則來計算。因為交友軟體上的男生只有PUA男跟真誠男兩種(互補),而且PUA男不可能真誠,真誠男也不可能騙財騙色(互斥)。
所以我們到底要怎麼計算跟你聊天第一句話就是「在嗎」的可能性呢?請看下圖: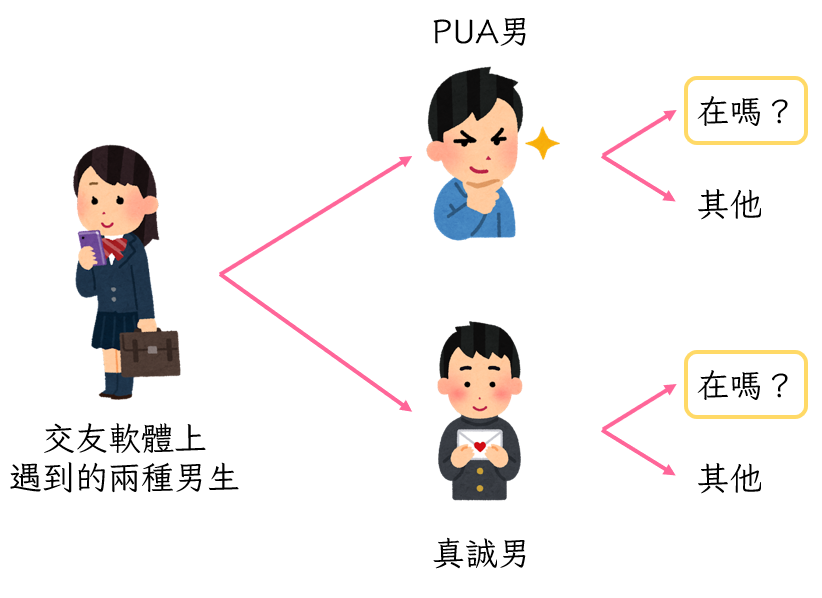
因為我們已經知道在交友軟體不是遇到PUA男就是遇到真誠男了,而且他們的身分並不會重疊,所以我們只會遇到第一句話講「在嗎?」的PUA男或是第一句話講「在嗎?」的真誠男。也就是說我們遇到第一句話講「在嗎?」的男生的可能性就像圖裡面被框框圈起來的部份一樣,等於遇到PUA男且他第一句話講「在嗎?」的可能性(PUA男跟「在嗎」的聯集)加上遇到真誠男且他第一句話講「在嗎?」的可能性(真誠男跟「在嗎」的聯集)。意即:
透過這個例子我們可以整理出,當我們想求出事件B的機率時,可以找到互補且互斥的N個事件來推算出B發生的可能性。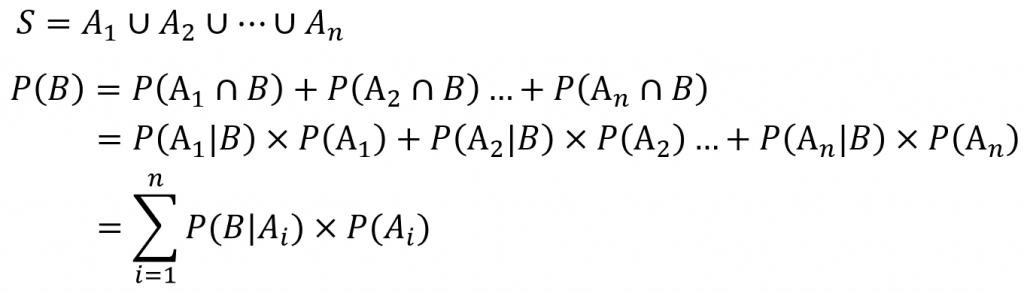
上面是想知道在交友軟體上面遇到「在嗎?」男的機率的時候可以做的事情。但是我們今天的目的是想知道自己遇到「在嗎?」男時,對方是PUA男的機率嘛,到底要怎麼計算呢?這就是貝式定理派上用場的時候了。為了求出P(PUA男|在嗎?),我們要先回想一下P(在嗎?∩ PUA男)是怎麼被算出來的。
註:P(A|B)代表的是B事件發生的前提下A事件發生的機率,所以P(A|B)跟P(B|A)算出來的數字會不一樣喔,要特別注意他們之間的不同。
這個時候就會發現黃色框框裡面有我們想要的東西,所以透過四則運算的移項規則,我們可以把P(PUA男|在嗎?)單獨移到等號左邊,讓他變成下面這樣: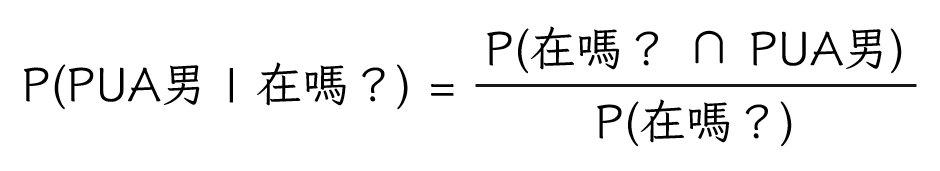
接著再把分子代換一下,就會變成下面這樣:
然後因為我們剛剛已經用全機率法則求出P(在嗎?)了,所以可以再把公式帶進去,然後就可以得出我們遇到的「在嗎?」男是PUA男的機率是0.71:
其實就是一個在等號兩邊移來移去把式子換來換去的過程,然後我們就可以得出事件B發生的情況下,屬於互補且互斥事件中第k個的機率公式:
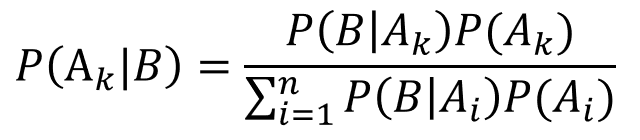
因為我們是先知道P(在嗎?),再以它為基礎加入新資訊去計算出P(PUA男|在嗎?),所以在貝式定理裡面前者被稱為先驗機率(prior probability),後者則是後驗機率(posterior probability)。關於這個部分更詳細的描述,可以看這篇文章。
在進行機器學習的時候,我們可以根據對資料的觀察找出一些可能對於區辨兩個分類有幫助的特徵標籤,以鑑別PUA男的例子來說就是我們可以看他是不是找你的第一句話會用「在嗎?」、是不是常常提起自己缺錢、是不是常常對一些小事都展現過度的共鳴等等。把這些標籤跟他們是不是渣男都送進去給機器之後,它就會得到不同的機率分配,也就能根據這個結果去計算對方是PUA男的機率跟真誠男的機率,再以數字較大者做為分類結果。這邊需要特別注意的是,如果使用單純貝式分類器的話,給出的標籤只能是分類變項,不能是連續變數。就像我們剛剛舉的例子一樣,每個可能發生的事件之間都是獨立而且有自己機率的,如果是連續數字就沒有辦法滿足這個條件。(如果真的想在裡面使用連續變數的話,可以參考高斯貝式分類器)
使用貝式分類器可能會遇到的問題是,如果樣本數不夠多的時候,機率容易受到單一資料偏差的影響而讓預測結果變得不準確,所以它只適用在擁有很多資料的時候。樣本數不夠多帶來的另外一個問題是,如果我們沒有辦法保證樣本的代表性,可能就會使學習過程產生偏差。例如剛好都找到比較進化,不講「在嗎?」的PUA男對話紀錄來訓練模型的話,它就會覺得誤把「在嗎?」認為是PUA男的反向指標。也就是說,單純貝式分類器只適用在我們能拿到足夠多足夠好的資料,非常理想的情況之下,所以他才叫做單純貝式分類器。除此之外,因為是透過機率不斷相乘再相加去計算,如果特徵太多就容易造成數字越成越小的狀況發生,所以貝式分類器也不適用在特徵過多的情況之下。
以上就是針對單純貝式分類器原理的介紹,如果有什麼問題都歡迎在下方提問或糾正~下一篇會針對如何實做進行教學,明天見!


 iThome鐵人賽
iThome鐵人賽