前幾日的文章,討論到了在訓練過程中,從資料的I/O、前處理到放入GPU之前的優化方式。今天將討論在GPU內的優化方式。
我們在先前的訓練時,預設的狀況下,從讀取資料到模型的訓練以及驗證,全部的數值都是使用float32(單精度浮點數,可參考wiki)。
數值部份的資料格式,除了最常見的float32以外,其實還存在很多不同的種,例如:只有01的Boolean、整數常用的Int16以及今天要討論到的主角-----大小只有Float32一半的半精度浮點數Flost16。
所謂的AMP(automatic mixed precision,即自動混和精度),就是一種利用相同數值能以不同格式儲存所帶來的記憶體容量差異優勢來進行訓練的技術。更詳細的介紹可以觀看這篇文章,這裡截一張裡頭的重點圖:
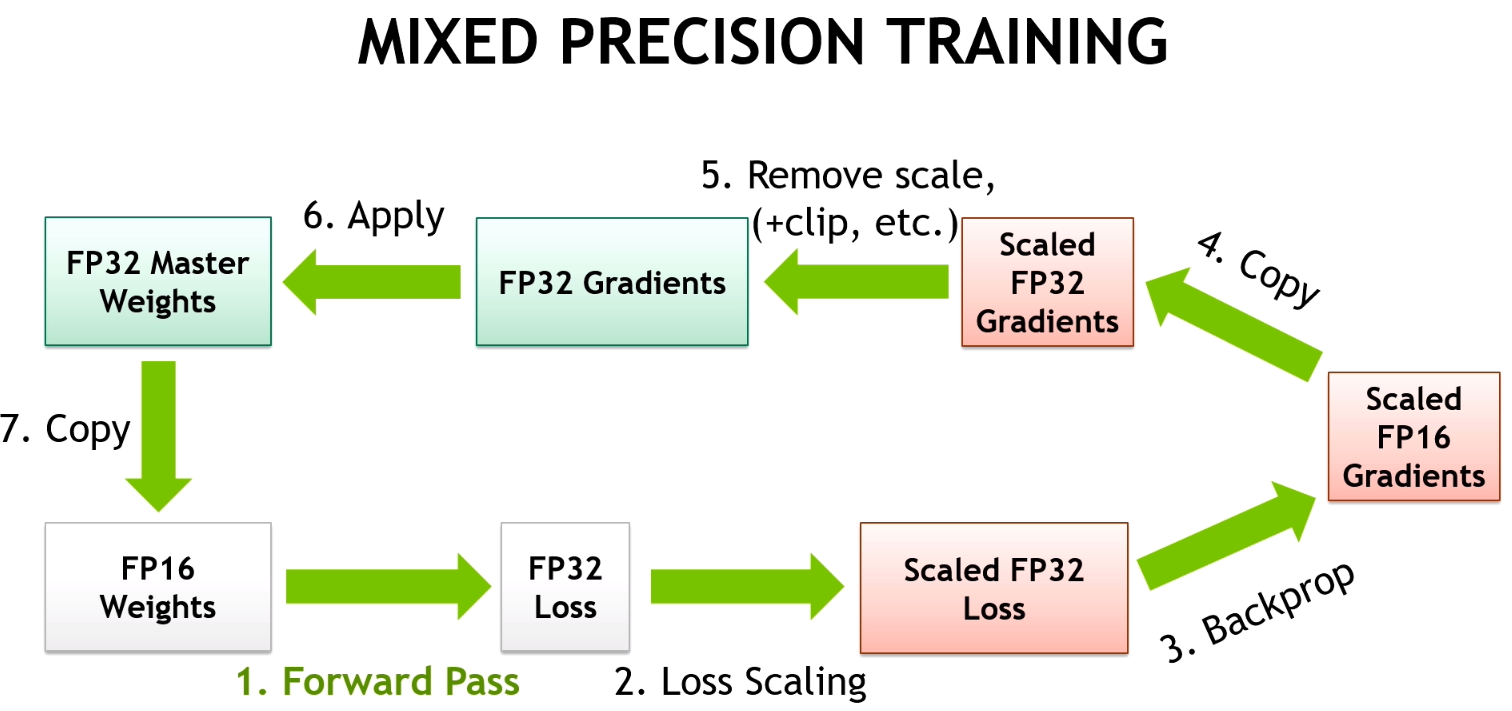
其運作方式大致上是:
除了今天主要介紹的AMP以外,還有一個個人覺得比較有感的加速則是Cudnn的Benchmark Mode。
詳細內容可以參考這篇討論,主要是由於cudnn內其實有多套不同的Convolution演算法實作,開啟這個功能主要是訓練時,cudnn會去自動調整針對當下tensor大小的最快最適合的演算法,來藉以加速。
實際實作很簡單,在pytroch裡面只要加上:
torch.backends.cudnn.benchmark = True
而Pytorch-Lightning則只要在Trainer內加上:
trainer = pl.Trainer(...,
benchmark = True)
就可以開啟這項功能了。
現在讓我們實際來比較差異,這次主要針對有無AMP跟有無開啟CUDNN benchmark來做四組的比較:
左圖為訓練時的使用記憶體變化量,右圖是整體的計算時間
大概可以歸納出下列幾點:

