這篇文章因為調整訓練資料及版本,因此詳細請看 ipynb,此文章只紀錄 nn.Transformer 這篇文章因為調整訓練資料及版本,因此詳細請看 ipynb,此文章只紀錄 nn.Transformer
`這篇文章因為調整訓練資料及版本,因此詳細請看 ipynb,此文章只紀錄 nn.Transformer
利用前面的基礎再往上導入 Pytorch 內建的 Transformers 的模組,Transformers 跟之前的 attention 差異的地方在於幾個不同的點,這邊就不多說明
至於內建的 Transformer 不懂的地方的話,可以參考下方的文件說明,簡單來講就是把複雜的 Transformer 架構想像成一個黑盒子,然後直接使用就可以了
ref : Pytorch中 nn.Transformer的使用详解与Transformer的黑盒讲解
整個概念大概如上面文章的說明,然而這篇就稍微解釋程式碼的問題
如果想要從頭幹起 Transformer 的話,就看下一篇的說明,這一篇就直接使用現成的模組來說明
並參考這張圖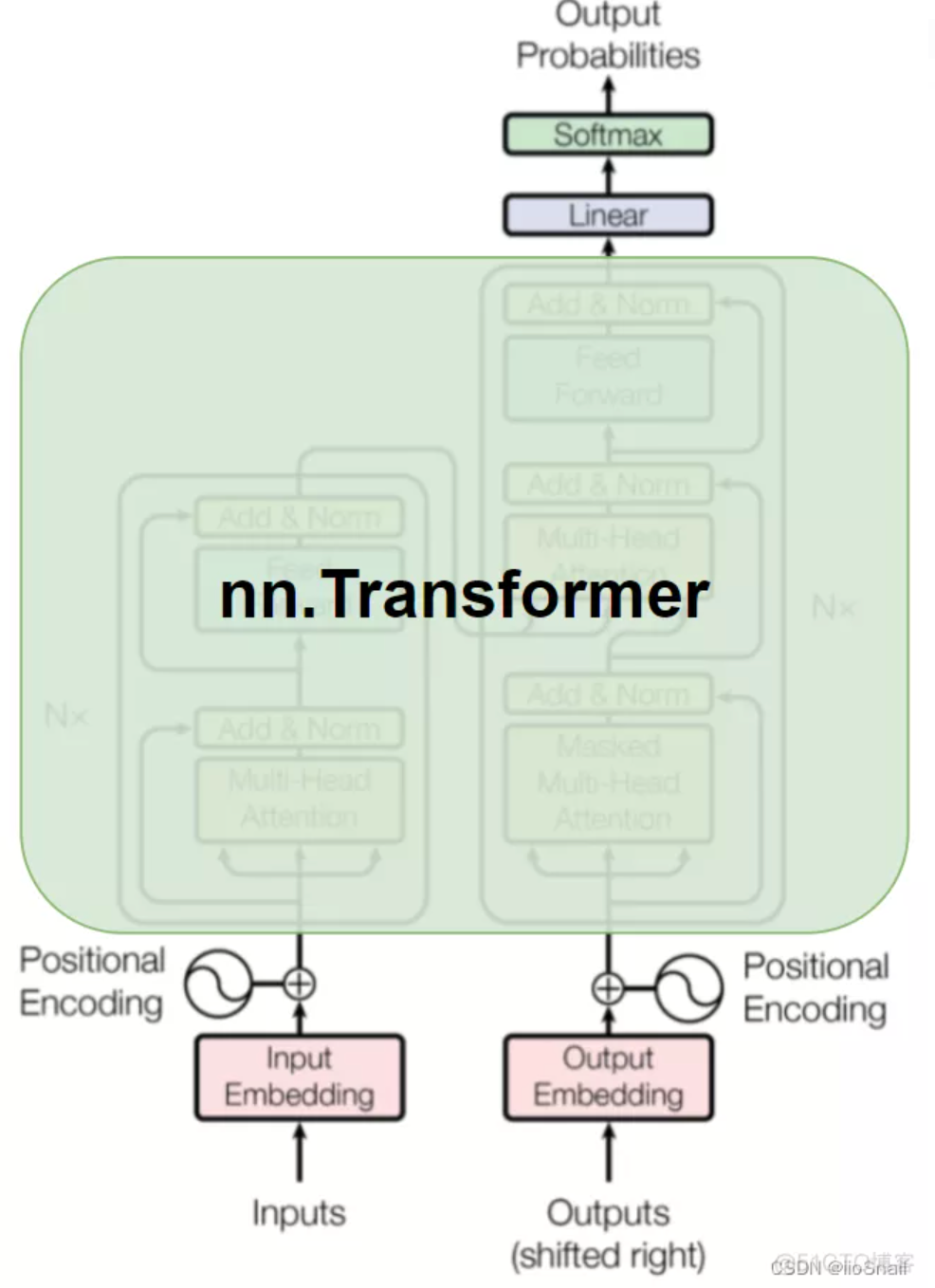
圖片中可以看到 nn.Transformer 沒蓋到的地方就是我們要訓練的地方分別有下方四個 embedding :
然後上方的部分要做一個 Linear 還有最後的 softmax
class Transformer(nn.Module):
def __init__(
self,
embedding_size,
src_vocab_size,
trg_vocab_size,
src_pad_idx,
num_heads,
num_encoder_layers,
num_decoder_layers,
forward_expansion,
dropout,
max_len,
device,
):
super(Transformer, self).__init__()
# 這邊放這需要被訓練的 embedding layer
self.src_word_embedding = nn.Embedding(src_vocab_size, embedding_size)
self.src_position_embedding = nn.Embedding(max_len, embedding_size)
self.trg_word_embedding = nn.Embedding(trg_vocab_size, embedding_size)
self.trg_position_embedding = nn.Embedding(max_len, embedding_size)
self.device = device
# 呼叫內建的 transformer,這就很簡單 api 直接尻起來
#
self.transformer = nn.Transformer(
embedding_size,
num_heads,
num_encoder_layers,
num_decoder_layers,
forward_expansion,
dropout,
)
self.fc_out = nn.Linear(embedding_size, trg_vocab_size)
self.dropout = nn.Dropout(dropout)
self.src_pad_idx = src_pad_idx
# eecoder 用的 mask call padding mask
def make_src_mask(self, src):
src_mask = src.transpose(0, 1) == self.src_pad_idx
# (N, src_len)
return src_mask.to(self.device)
def forward(self, src, trg):
src_seq_length, N = src.shape
trg_seq_length, N = trg.shape
src_positions = (
torch.arange(0, src_seq_length)
.unsqueeze(1)
.expand(src_seq_length, N)
.to(self.device)
)
trg_positions = (
torch.arange(0, trg_seq_length)
.unsqueeze(1)
.expand(trg_seq_length, N)
.to(self.device)
)
embed_src = self.dropout(
(self.src_word_embedding(src) + self.src_position_embedding(src_positions) )
)
embed_trg = self.dropout(
(self.trg_word_embedding(trg) + self.trg_position_embedding(trg_positions) )
)
# <pad> 加入 mask
src_padding_mask = self.make_src_mask(src)
# 訓練的時候要加入mask 不然會看到後面的答案
# decoder 用的mask call sequence mask
trg_mask = self.transformer.generate_square_subsequent_mask(trg_seq_length).to(
self.device
)
out = self.transformer(
embed_src,
embed_trg,
src_key_padding_mask=src_padding_mask,
tgt_mask=trg_mask,
)
# nn.transformer 的 output 後面要再加一個 linear
out = self.fc_out(out)
return out
這邊記錄一下 embedding 的說明:
encoder 跟 decoder 的input 參數,他們是對 token 進行embedding 然後再經過 positional embedding 後的結果。
舉例來說 你,要,不,要,來,我,家,看,貓咪 透過 vocab 變成 [[1, 0, 2, 0, 3, 4, 5, 6, 7 ]],shape (1, 9), batch size = 1.
再來經過 word embedding , shape (1, 9, 128)
# Training hyperparameters
num_epochs = 10000
learning_rate = 3e-4
batch_size = 32
# model hyperparameters
src_vocab_size = len(zh_vocab.vocab)
trg_vocab_size = len(en_vocab.vocab)
embedding_size = 512
num_heads = 8
num_encoder_layers = 3
num_decoder_layers = 3
dropout = 0.10
max_len = 100
forward_expansion = 4
src_pad_idx = en_vocab.vocab.get_stoi()["<pad>"]
這邊說明一下,因為版本的問題,這邊已經升上去 torchtext = 0.12 版本,所以原本的切法這邊就改成 DataLoader ,後續把 ipynb 上傳會比較完整
PAD_IDX = zh_vocab.vocab.get_stoi()['<pad>']
BOS_IDX = zh_vocab.vocab.get_stoi()['<bos>']
EOS_IDX = zh_vocab.vocab.get_stoi()['<eos>']
## 主要是在處理 batch 的時候 長度要對齊
def generate_batch(data_batch):
zh_batch, en_batch = [], []
for (zh_token, en_token) in data_batch:
zh_item = torch.tensor([zh_vocab.vocab.get_stoi()[token] for token in zh_token], dtype=torch.long)
zh_batch.append(torch.cat([torch.tensor([BOS_IDX]), zh_item, torch.tensor([EOS_IDX])], dim=0))
en_item = torch.tensor([en_vocab.vocab.get_stoi()[token] for token in en_token], dtype=torch.long)
en_batch.append(torch.cat([torch.tensor([BOS_IDX]), en_item, torch.tensor([EOS_IDX])], dim=0))
zh_batch = pad_sequence(zh_batch, padding_value=PAD_IDX)
en_batch = pad_sequence(en_batch, padding_value=PAD_IDX)
return zh_batch, en_batch
train_iter = DataLoader(train_data, batch_size=batch_size,
shuffle=True, collate_fn=generate_batch)
test_iter = DataLoader(test_data, batch_size=batch_size,
shuffle=True, collate_fn=generate_batch)
model = Transformer(
embedding_size,
src_vocab_size,
trg_vocab_size,
src_pad_idx,
num_heads,
num_encoder_layers,
num_decoder_layers,
forward_expansion,
dropout,
max_len,
device,
).to(device)
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
optimizer, factor=0.1, patience=10, verbose=True
)
pad_idx = en_vocab.vocab.get_stoi()["<pad>"]
criterion = nn.CrossEntropyLoss(ignore_index=pad_idx)
# 這個是用來 Load 上次的checkpoint
if os.path.isfile(checkPointPath):
load_checkpoint(torch.load(checkPointPath), model, optimizer)
# 訓練之前,先看一下 blue score ,第一次訓練應該是0
score = bleu(test_data[1:100], model, tokenize_zh, zh_vocab, en_vocab, device)
print(f"Bleu score {score*100:.2f}")
這邊就丟下去給他訓練model
sentence = "你想不想要来我家看猫?或者一起看电影?"
example_token = tokenize_zh(sentence)
for epoch in range(num_epochs):
print(f"[Epoch {epoch} / {num_epochs}]")
if save_model:
checkpoint = {
"state_dict": model.state_dict(),
"optimizer": optimizer.state_dict(),
}
save_checkpoint(checkpoint)
model.eval()
translated_sentence = translate_sentence(
model, example_token, zh_vocab, en_vocab, device, max_length=50
)
print(f"Translated example sentence: \n {translated_sentence}")
model.train()
losses = []
for batch_idx, batch in enumerate(train_iter):
# Get input and targets and get to cuda
inp_data = batch[0].to(device)
target = batch[1].to(device)
# Forward prop
output = model(inp_data, target[:-1, :])
# Output is of shape (trg_len, batch_size, output_dim) but Cross Entropy Loss
# doesn't take input in that form. For example if we have MNIST we want to have
# output to be: (N, 10) and targets just (N). Here we can view it in a similar
# way that we have output_words * batch_size that we want to send in into
# our cost function, so we need to do some reshapin.
# Let's also remove the start token while we're at it
output = output.reshape(-1, output.shape[2])
target = target[1:].reshape(-1)
optimizer.zero_grad()
loss = criterion(output, target)
losses.append(loss.item())
# Back prop
loss.backward()
# Clip to avoid exploding gradient issues, makes sure grads are
# within a healthy range
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1)
# Gradient descent step
optimizer.step()
# plot to tensorboard
writer.add_scalar("Training loss", loss, global_step=step)
step += 1
mean_loss = sum(losses) / len(losses)
# learning rate scheduler 這裡要記得使用
scheduler.step(mean_loss)
# running on entire test data takes a while
score = bleu(test_data[1:100], model, tokenize_zh, zh_vocab, en_vocab, device)
print(f"Bleu score {score*100:.2f}")
這篇文章主要是理解 Pytorch 內建的 transformer 的使用方式,另外同時釐清 transformer 裡面兩個mask 機制,另外因為網路上使用的 torchtext 大部分都為舊版本,而現在torch 主要的都是藉由 DataLoader 來處理batch 資料,因此這邊也直接轉換前處理的程式碼
剩下 Transformer 的細節我們下一篇文章再來談


 iThome鐵人賽
iThome鐵人賽