From Scratch 就是從頭開始的意思,所以這張主要是要講 Transformer , Transformer 的每個元件開始講起,所以會很多技術的細節,如果沒辦法講得很清楚的話,請搭配這個大神的說明 The Illustrated Transformer 講得十分清楚,我也是從這邊來去理解 Transformer 的整個架構,再搭配以下的code 慢慢推敲其運作的原理,因此我們就來開始吧
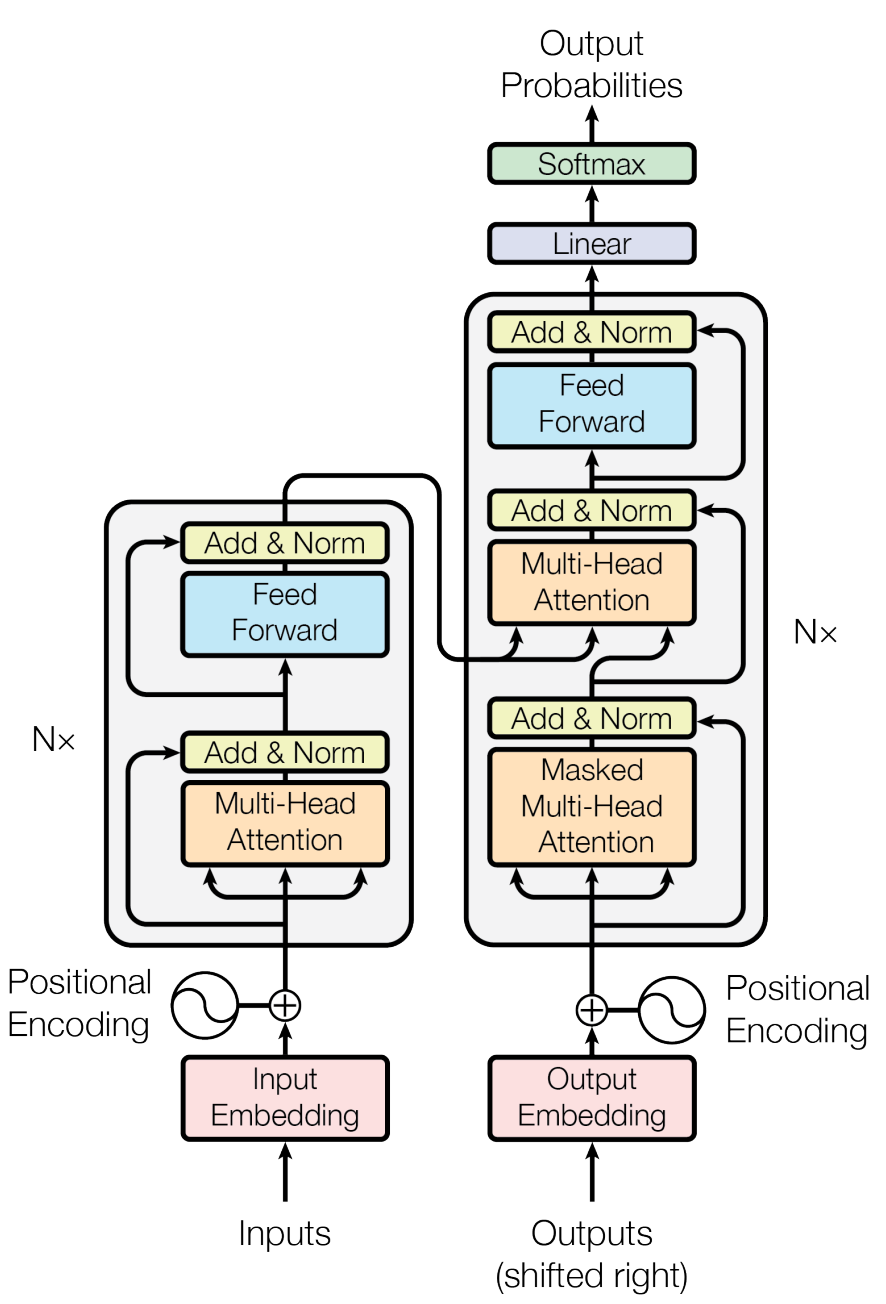
首先這是一個 Transfomer 的架構看圖就大概知道,左邊的為 decoder 的架構,右邊的為encoder 的架構,重要的是有一個 Multi-Head Attention 這一塊等等會獨立出來說明,然後decoder 的 Multi-Head Attention 多一個 Masked 的步驟,所以會把 Masked 的需求寫進去 Attention Class 裡面,接下來就一點一點慢慢講
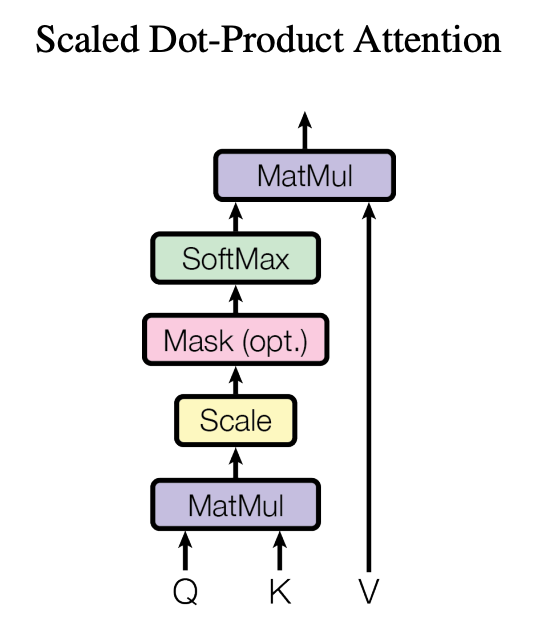
因為 Decoder 跟 Encoder 都需要 Attention ,畢竟 Transformer 的霸氣標題就是 『Attention is all you need』 的關係,所以這一塊 Attention 是真的很重要
首先這個是 Attention 的計算架構圖,中間有看到一個 Mask 的部分後面會講 , 而 Mask 有分兩個一個是 encoder 層面的 padding Mask,decoder 的 Masked Multi-Head attention
class SelfAttention(nn.Module):
def __init__(self, embed_size, heads):
super(SelfAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
assert (
self.head_dim * heads == embed_size
), "Embedding size needs to be divisible by heads"
self.values = nn.Linear(embed_size, embed_size)
self.keys = nn.Linear(embed_size, embed_size)
self.queries = nn.Linear(embed_size, embed_size)
self.fc_out = nn.Linear(embed_size, embed_size)
def forward(self, values, keys, query, mask):
# Get number of training examples
N = query.shape[0]
value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]
values = self.values(values) # (N, value_len, embed_size)
keys = self.keys(keys) # (N, key_len, embed_size)
queries = self.queries(query) # (N, query_len, embed_size)
# Split the embedding into self.heads different pieces
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
queries = queries.reshape(N, query_len, self.heads, self.head_dim)
# Einsum does matrix mult. for query*keys for each training example
# with every other training example, don't be confused by einsum
# it's just how I like doing matrix multiplication & bmm
energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])
# queries shape: (N, query_len, heads, heads_dim),
# keys shape: (N, key_len, heads, heads_dim)
# energy: (N, heads, query_len, key_len)
# Mask padded indices so their weights become 0
if mask is not None:
energy = energy.masked_fill(mask == 0, float("-1e20"))
# Normalize energy values similarly to seq2seq + attention
# so that they sum to 1. Also divide by scaling factor for
# better stability
attention = torch.softmax(energy / (self.embed_size ** (1 / 2)), dim=3)
# attention shape: (N, heads, query_len, key_len)
out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(
N, query_len, self.heads * self.head_dim
)
# attention shape: (N, heads, query_len, key_len)
# values shape: (N, value_len, heads, heads_dim)
# out after matrix multiply: (N, query_len, heads, head_dim), then
# we reshape and flatten the last two dimensions.
out = self.fc_out(out)
# Linear layer doesn't modify the shape, final shape will be
# (N, query_len, embed_size)
return out
說明: padding mask 就是因為batch input 的seqence length 不一致(有長有短),所以需要使用 <pad> 填充到後面的跟,而這些 <pad> 不需要計算 attention 所以就用 Mask(這邊使用-inf),然後在 softmax 的時候會直接變成0所以就不會有 attention score 。
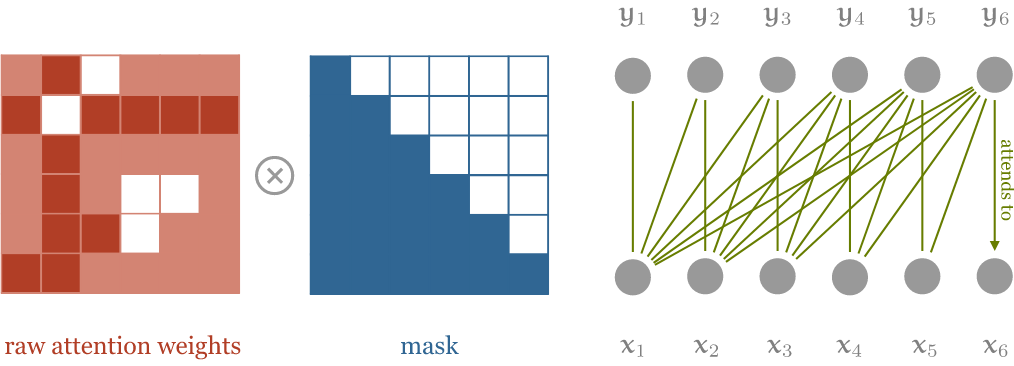
說明:因為不能看到後面的答案,所以會是用 Masked ,以下面的圖來說,計算y1 的時候考慮的只有 x1 , 而計算 y2 的時候考慮的只有 x1 跟 x2
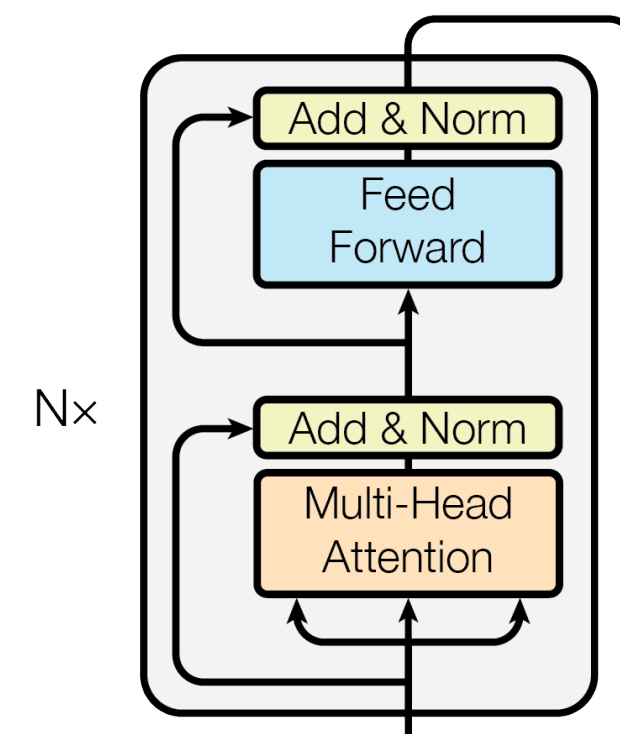
接著要把 Attention 跟 Add & Norm 還有 Feed Forward 拼起來,所以接下來的要生出來的架構如下
class TransformerBlock(nn.Module):
def __init__(self, embed_size, heads, dropout, forward_expansion):
super(TransformerBlock, self).__init__()
self.attention = SelfAttention(embed_size, heads)
self.norm1 = nn.LayerNorm(embed_size)
self.norm2 = nn.LayerNorm(embed_size)
self.feed_forward = nn.Sequential(
nn.Linear(embed_size, forward_expansion * embed_size),
nn.ReLU(),
nn.Linear(forward_expansion * embed_size, embed_size),
)
self.dropout = nn.Dropout(dropout)
def forward(self, value, key, query, mask):
attention = self.attention(value, key, query, mask)
# Add skip connection, run through normalization and finally dropout
x = self.dropout(self.norm1(attention + query))
forward = self.feed_forward(x)
out = self.dropout(self.norm2(forward + x))
return out
Encoder Block 跟上面唯一的差別就是在於下方的 position encoding 還有 input embedding 這兩個區塊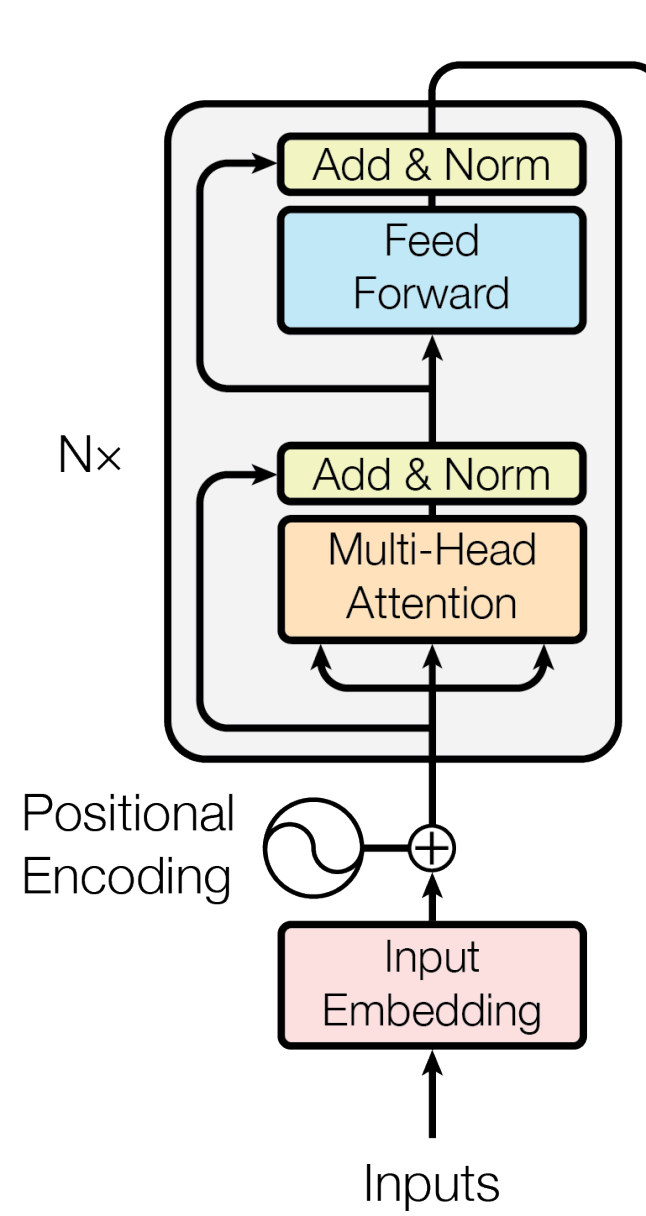
class Encoder(nn.Module):
def __init__(
self,
src_vocab_size,
embed_size,
num_layers,
heads,
device,
forward_expansion,
dropout,
max_length,
):
super(Encoder, self).__init__()
self.embed_size = embed_size
self.device = device
self.word_embedding = nn.Embedding(src_vocab_size, embed_size)
self.position_embedding = nn.Embedding(max_length, embed_size)
self.layers = nn.ModuleList(
[
TransformerBlock(
embed_size,
heads,
dropout=dropout,
forward_expansion=forward_expansion,
)
for _ in range(num_layers)
]
)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
N, seq_length = x.shape
positions = torch.arange(0, seq_length).expand(N, seq_length).to(self.device)
out = self.dropout(
(self.word_embedding(x) + self.position_embedding(positions))
)
# In the Encoder the query, key, value are all the same, it's in the
# decoder this will change. This might look a bit odd in this case.
for layer in self.layers:
out = layer(out, out, out, mask)
return out
會用Decoder block 主要的原因是因為是要先處理 Decoder 的部分,而在最後的output 的部分可以依據解決的問題不同來做不同的輸出,不同的輸出會放在下一階段再講decoder ,這邊主要先來講 Decoder Block ,如下方圖片所示
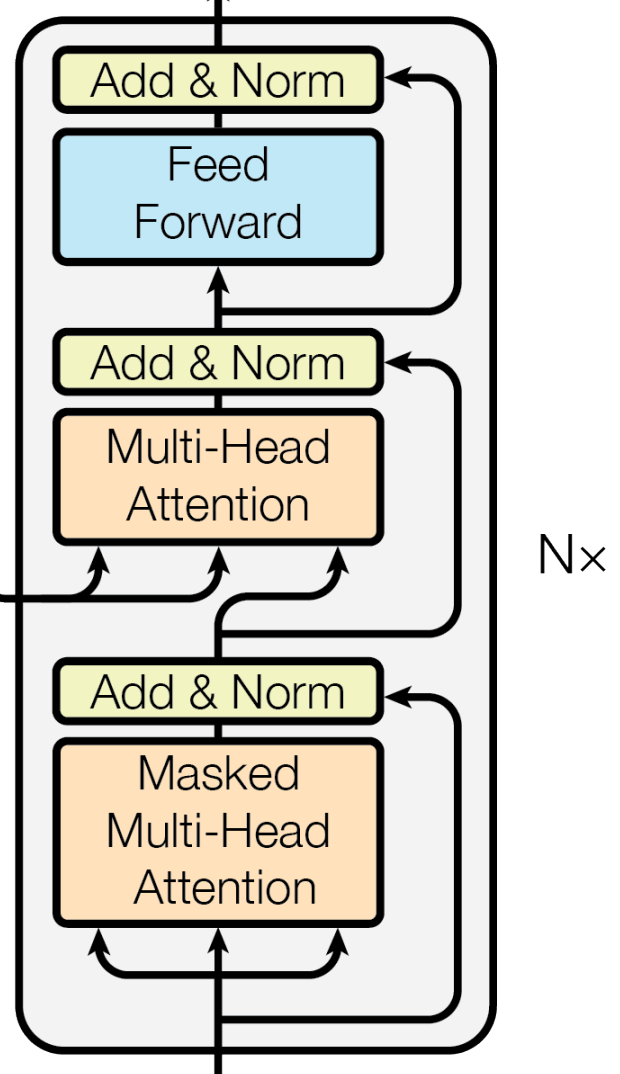
class DecoderBlock(nn.Module):
def __init__(self, embed_size, heads, forward_expansion, dropout, device):
super(DecoderBlock, self).__init__()
self.norm = nn.LayerNorm(embed_size)
self.attention = SelfAttention(embed_size, heads=heads)
self.transformer_block = TransformerBlock(
embed_size, heads, dropout, forward_expansion
)
self.dropout = nn.Dropout(dropout)
def forward(self, x, value, key, src_mask, trg_mask):
attention = self.attention(x, x, x, trg_mask)
query = self.dropout(self.norm(attention + x))
out = self.transformer_block(value, key, query, src_mask)
return out
再來就是我們來做翻譯任務的 Decoder ,因為翻譯任務每一次的Decoder 都是輸出一個機率的分布,代表在所有的 token 的機率為多少,然後挑出機率最大的當作output ,所以這邊後面就是一個Linear 然後再接 Softmax 挑最大的之後,記得要把output 再傳回 input 一直重複到output 為 <eos> 為止。
另外一開始要預測第一個翻譯的 token 就是開始符號 <bos> 就叫做 begin of sentence ,也有人用 <sos> 都可以反正自己知道在做什麼就好XD
而Encoder 的資訊要把 Query 跟 Key 要傳到 Decoder 這裡,而這個行為就是所謂的 cross attention 是encoder 跟 decoder 中間的橋樑,所以相當的重要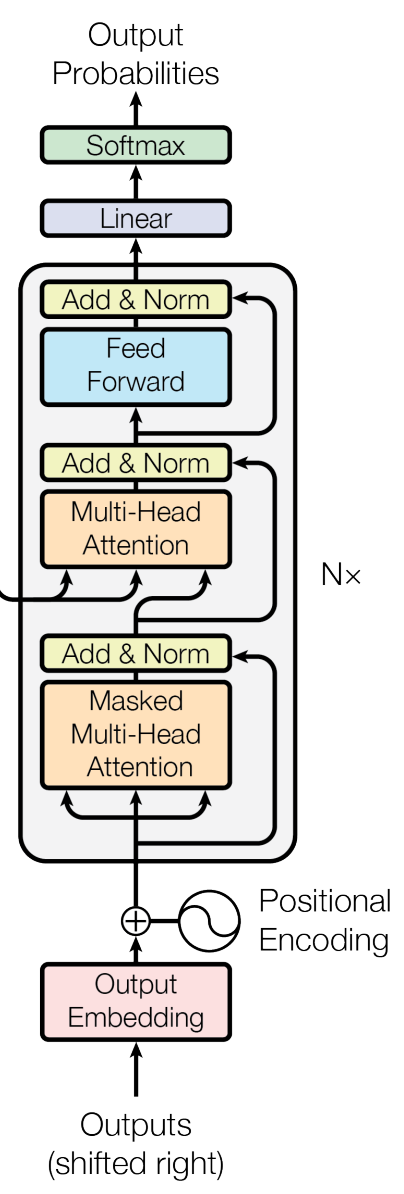
class Decoder(nn.Module):
def __init__(
self,
trg_vocab_size,
embed_size,
num_layers,
heads,
forward_expansion,
dropout,
device,
max_length,
):
super(Decoder, self).__init__()
self.device = device
self.word_embedding = nn.Embedding(trg_vocab_size, embed_size)
self.position_embedding = nn.Embedding(max_length, embed_size)
self.layers = nn.ModuleList(
[
DecoderBlock(embed_size, heads, forward_expansion, dropout, device)
for _ in range(num_layers)
]
)
self.fc_out = nn.Linear(embed_size, trg_vocab_size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, enc_out, src_mask, trg_mask):
N, seq_length = x.shape
positions = torch.arange(0, seq_length).expand(N, seq_length).to(self.device)
x = self.dropout((self.word_embedding(x) + self.position_embedding(positions)))
for layer in self.layers:
x = layer(x, enc_out, enc_out, src_mask, trg_mask)
out = self.fc_out(x)
return out
把各個元件拆解後要拼起來了,
class Transformer(nn.Module):
def __init__(
self,
src_vocab_size,
trg_vocab_size,
src_pad_idx,
trg_pad_idx,
embed_size=512,
num_layers=6,
forward_expansion=4,
heads=8,
dropout=0,
device="cpu",
max_length=100,
):
super(Transformer, self).__init__()
self.encoder = Encoder(
src_vocab_size,
embed_size,
num_layers,
heads,
device,
forward_expansion,
dropout,
max_length,
)
self.decoder = Decoder(
trg_vocab_size,
embed_size,
num_layers,
heads,
forward_expansion,
dropout,
device,
max_length,
)
self.src_pad_idx = src_pad_idx
self.trg_pad_idx = trg_pad_idx
self.device = device
def make_src_mask(self, src):
src_mask = (src != self.src_pad_idx).unsqueeze(1).unsqueeze(2)
# (N, 1, 1, src_len)
return src_mask.to(self.device)
def make_trg_mask(self, trg):
N, trg_len = trg.shape
trg_mask = torch.tril(torch.ones((trg_len, trg_len))).expand(
N, 1, trg_len, trg_len
)
return trg_mask.to(self.device)
def forward(self, src, trg):
src_mask = self.make_src_mask(src)
trg_mask = self.make_trg_mask(trg)
enc_src = self.encoder(src, src_mask)
# enc_src => 裡面就有 Query and key
out = self.decoder(trg, enc_src, src_mask, trg_mask)
return out
這邊就簡單的呼叫,有興趣的也看把前面幾篇的文件來自己訓練一下機器翻譯的工作
if __name__ == "__main__":
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
x = torch.tensor([[1, 5, 6, 4, 3, 9, 5, 2, 0], [1, 8, 7, 3, 4, 5, 6, 7, 2]]).to(
device
)
trg = torch.tensor([[1, 7, 4, 3, 5, 9, 2, 0], [1, 5, 6, 2, 4, 7, 6, 2]]).to(device)
src_pad_idx = 0
trg_pad_idx = 0
src_vocab_size = 10
trg_vocab_size = 10
model = Transformer(src_vocab_size, trg_vocab_size, src_pad_idx, trg_pad_idx, device=device).to(
device
)
out = model(x, trg[:, :-1])
print(out.shape)
這邊補充一下 Multi-Head Attention 的機制,主要是訓練model 把注意力放置在不同的地方,藉由不同角度看整個句子來充分訓練出要如何來解讀這句子的資訊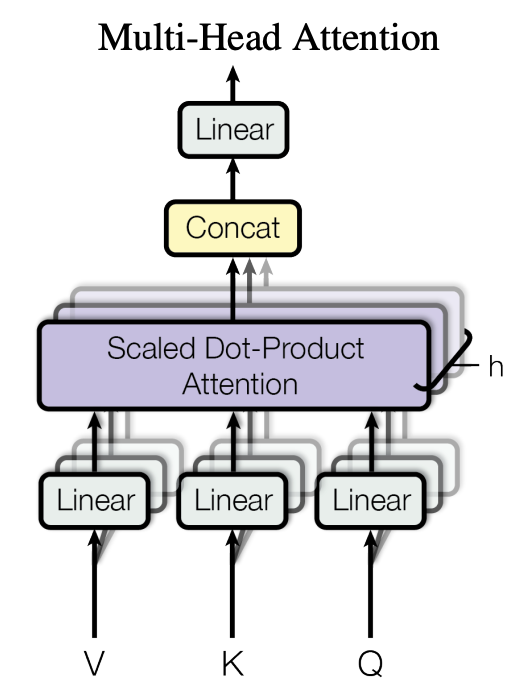
Attention is all you need 其實講的是真實的,因為現在很多關於時間、位置 等等的資訊要去取得的話都會使用 attention 的機制來讀取資料,而這邊的encoder 也可以換成 cnn 的架構,最後把透過幾層架構輸出 Key 跟 Query 再丟給 decoder 去處理他的任務。
因此Transformer 真的是需要好好去探討這中間的架構,對於之後的資料科學之路會比較順利一點


 iThome鐵人賽
iThome鐵人賽