Gan 其實主要就是兩個角色,一個是負責產生資訊或者圖表的 Generator ,另一個則是負責判斷是否為偽造出來的 Discriminator 。
聽起來很有趣,Generator就是負責產生偽造的資訊給然後參雜真實的資訊給 Discriminator 去判斷是否為偽造的機率為多少。
如果Discriminator可以輕易判斷出誰是偽造誰是真實的話,那這樣就是 Generator 太弱了,所以Generator 要換新的產生方式來騙過 Discriminator,所以他又會自己去學習要怎麼產生出更與真實資料相似的資訊出來,來騙過 Discriminator ,而 DIscriminator 被騙過之後(誤判機率變大)就代表說Discriminator 需要在學習怎麼判斷真偽。
因此如此的反覆循環,理想上 Generator 會越做越真實,而 Discrimintor 則會越來越會判斷,但是Gan 其實不好訓練,理想上雖然很美好,但是訓練卻是會碰到很多問題,不過這邊就是簡單利用GAN的概念來展示GAN 運作
如果需要詳細的GAN說明可以參考這篇作者寫的,講得非常詳細
小學生談『生成對抗網路』(Generative Adversarial Network,GAN
因為要看他訓練的狀況如何,因此直接用tensorboard 在上面看訓練的結果
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.datasets as datasets
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from torch.utils.tensorboard import SummaryWriter # to print to tensorboard
在colab 上面開啟colab 之前的文章有提到
# 外部載入 Tensorboard
%load_ext tensorboard
# 打開 Tensorboard 的版面,然後需要執行下面才會有
%tensorboard --logdir=runs
在開始拆解 Discrimonator 和 Generator 之前可以謹記這個架構模型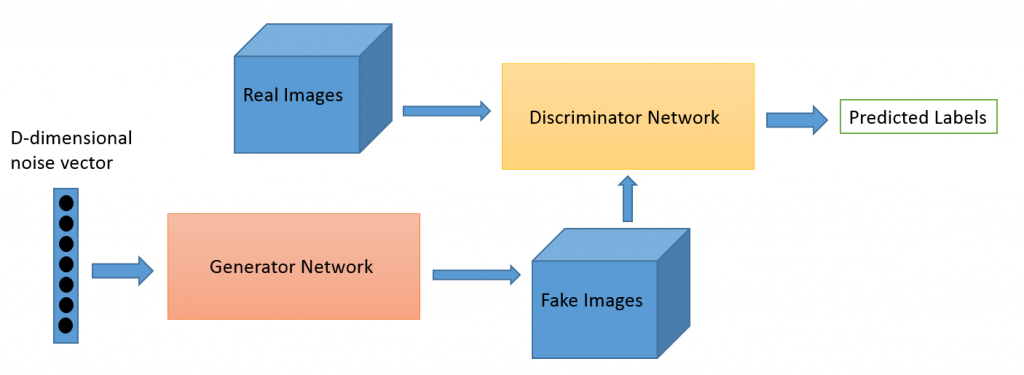
圖片來源:generative-adversarial-networks
Discriminator 通常都是用來判斷是不是偽造的,所以這邊的input 就是圖片的大小
#
class Discriminator(nn.Module):
def __init__(self, in_features):
super().__init__()
self.disc = nn.Sequential(
nn.Linear(in_features, 128),
nn.LeakyReLU(0.01), # paper 上面就是直接使用 LeakyReLu
nn.Linear(128, 1),
nn.Sigmoid(), # 最後用 sigmoid 輸出為yes or no
)
def forward(self, x):
return self.disc(x)
Generator 就是用來產生圖片,因為資料集是使用MNIST(這是手寫黑白的數字) ,因此後面加一個 Tanh 把裡面的數值降到 -1 ~ 1
class Generator(nn.Module):
def __init__(self, z_dim, img_dim):
super().__init__()
self.gen = nn.Sequential(
nn.Linear(z_dim, 256),
nn.LeakyReLU(0.01),
nn.Linear(256, img_dim), # 28x28x1
nn.Tanh(), # normalize inputs to [-1, 1] so make outputs [-1, 1]
)
def forward(self, x):
return self.gen(x)
# Hyperparameters etc.
device = "cuda" if torch.cuda.is_available() else "cpu"
lr = 3e-4
z_dim = 126
image_dim = 28 * 28 * 1 # 784
batch_size = 32
num_epochs = 500
需要使用 SummaryWriter 把產生的圖表呈現在 tensorboard 上面
disc = Discriminator(image_dim).to(device)
gen = Generator(z_dim, image_dim).to(device)
fixed_noise = torch.randn((batch_size, z_dim)).to(device)
# compose 先把東西轉成 tensor 之後再正規化
transforms = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,)),]
)
# channel=(channel-mean)/std
opt_disc = optim.Adam(disc.parameters(), lr=lr)
opt_gen = optim.Adam(gen.parameters(), lr=lr)
criterion = nn.BCELoss()
writer_fake = SummaryWriter(f"runs/simpleGAN/fake")
writer_real = SummaryWriter(f"runs/simpleGAN/real")
step = 0
資料集也是使用MNIST的資料集
dataset = datasets.MNIST(root="dataset/", transform=transforms, download=True)
loader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
訓練models的階段,不過要注意的就是訓練model的 loss func,首先
Train Discriminator: max log(D(x)) + log(1 - D(G(z)))
Train Generator: min log(1 - D(G(z))) <-> max log(D(G(z))
D(x)表示D判斷真實資料的機率,越高越好代表越有信心是真實的,所以D(x)越高越好,D(G(z))越低越好。z 這就是 noise 的概念。而利用z來產生的圖片就是G(z),
for epoch in range(num_epochs):
for batch_idx, (real, _) in enumerate(loader):
# real = image , 然後省略 label . image = 28 * 28 = 784
real = real.view(-1, 784).to(device)
batch_size = real.shape[0]
### Train Discriminator: max log(D(x)) + log(1 - D(G(z)))
noise = torch.randn(batch_size, z_dim).to(device)
fake = gen(noise)
disc_real = disc(real).view(-1)
lossD_real = criterion(disc_real, torch.ones_like(disc_real))
disc_fake = disc(fake).view(-1)
lossD_fake = criterion(disc_fake, torch.zeros_like(disc_fake))
lossD = (lossD_real + lossD_fake) / 2
disc.zero_grad()
lossD.backward(retain_graph=True)
opt_disc.step()
### Train Generator: min log(1 - D(G(z))) <-> max log(D(G(z))
# where the second option of maximizing doesn't suffer from
# saturating gradients
output = disc(fake).view(-1)
lossG = criterion(output, torch.ones_like(output))
gen.zero_grad()
lossG.backward()
opt_gen.step()
# 下面接著就是跑 tensorboard
if batch_idx == 0:
print(
f"Epoch [{epoch}/{num_epochs}] Batch {batch_idx}/{len(loader)} \
Loss D: {lossD:.4f}, loss G: {lossG:.4f}"
)
with torch.no_grad():
fake = gen(fixed_noise).reshape(-1, 1, 28, 28)
data = real.reshape(-1, 1, 28, 28)
img_grid_fake = torchvision.utils.make_grid(fake, normalize=True)
img_grid_real = torchvision.utils.make_grid(data, normalize=True)
writer_fake.add_image(
"Mnist Fake Images", img_grid_fake, global_step=step
)
writer_real.add_image(
"Mnist Real Images", img_grid_real, global_step=step
)
step += 1
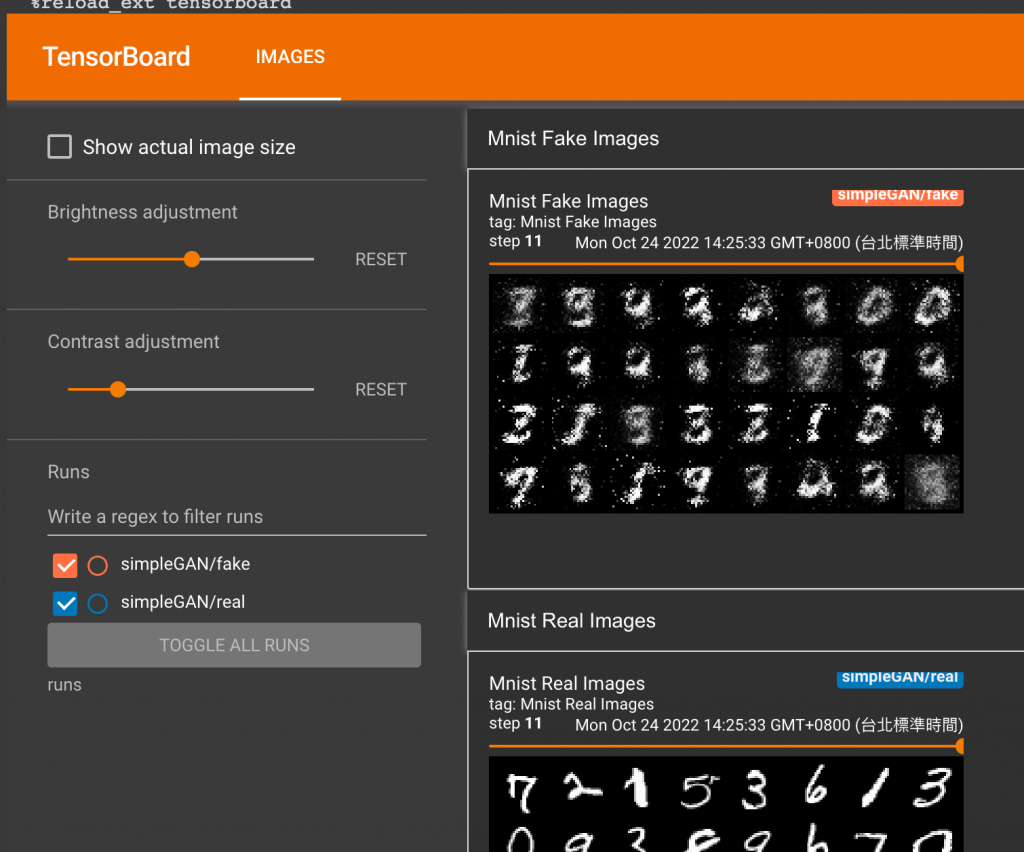
這是一開始訓練11次的狀況
訓練33次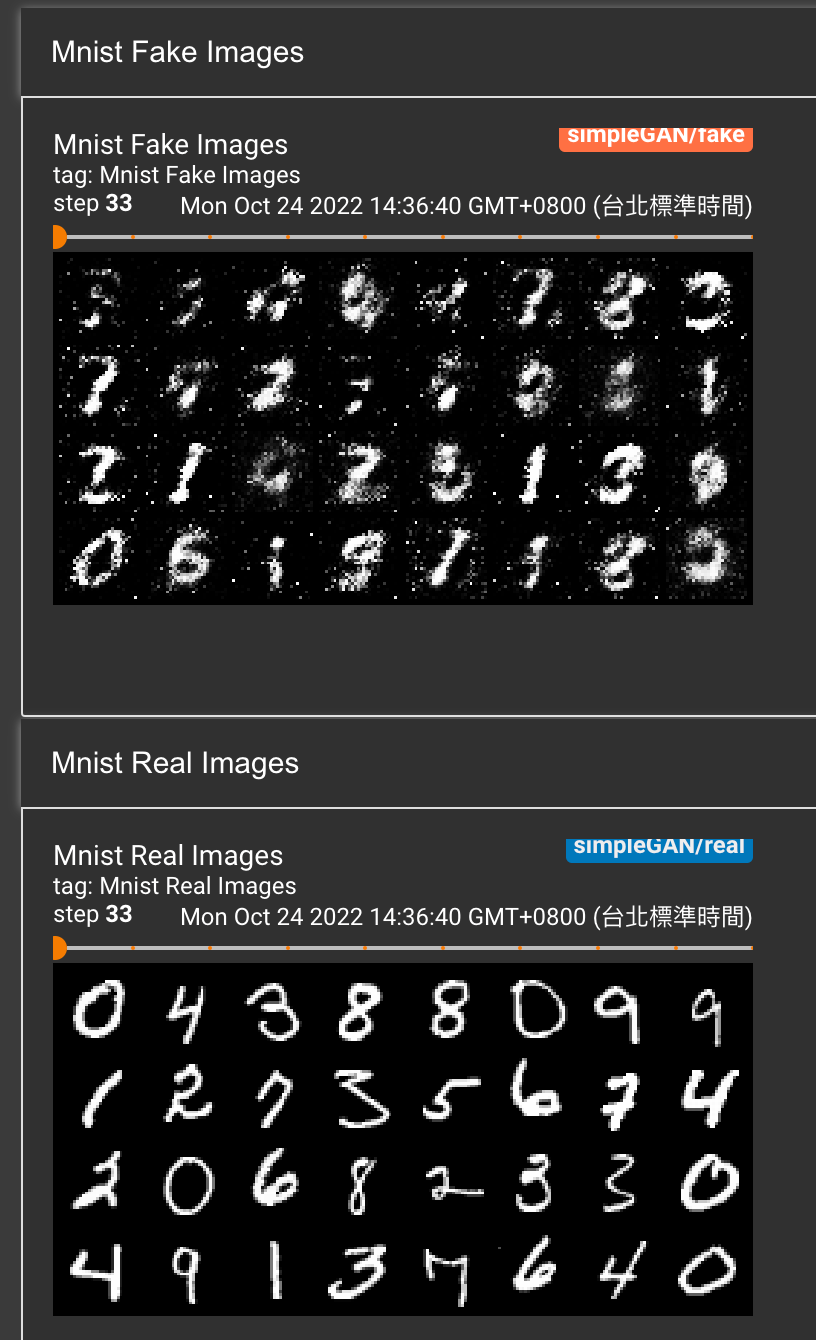
這是訓練302次 其實輪廓就很明顯了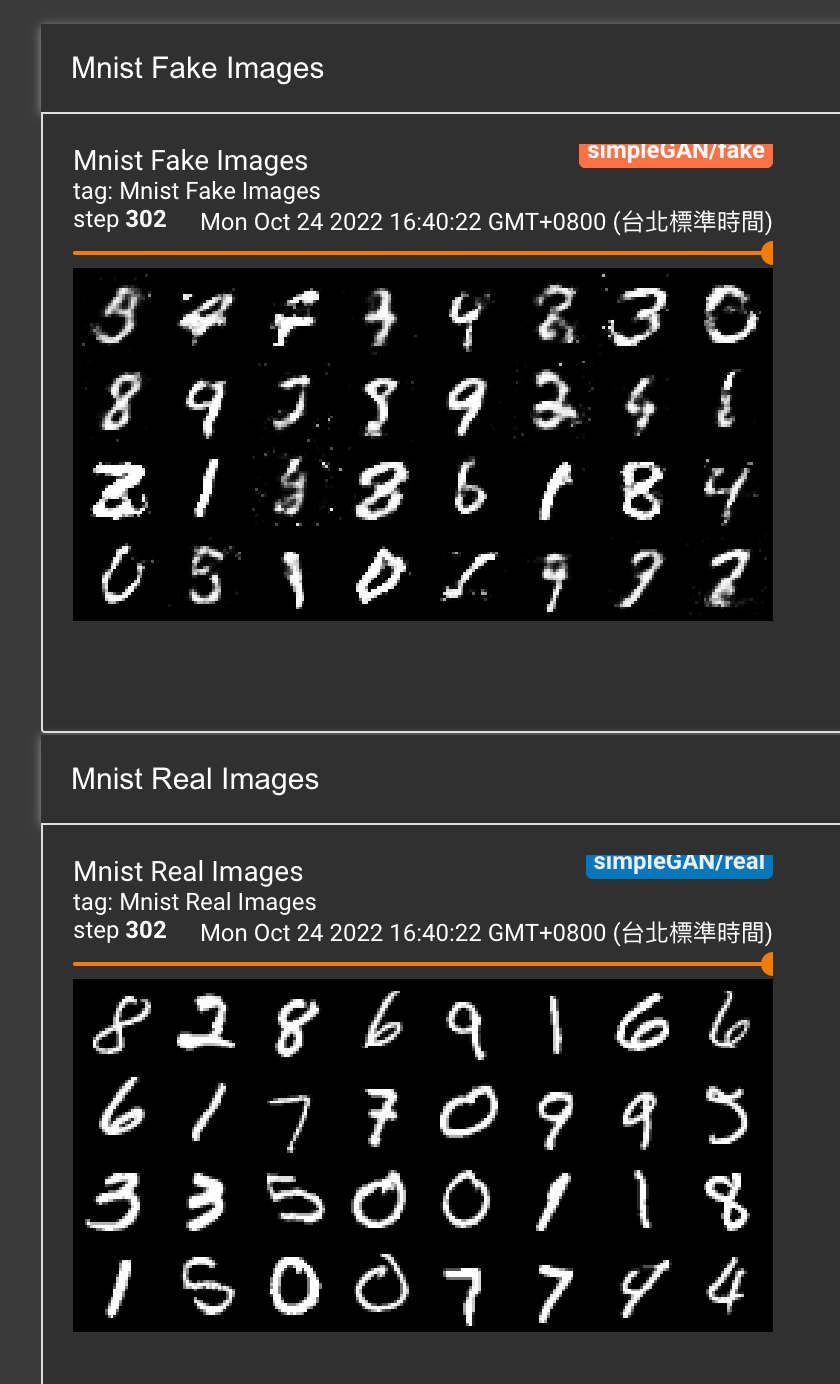
圖片就是利用 TensorBoard 看一下 Train的結果,其實一開始的訓練效果很快就可以看出有點東西,但是到後面會越來越難訓練,因為又要更精準跟細緻,所以model 在後面的改善的成效就相較於一開始沒有顯著的改變,但是訓練到最後面還是有不錯的成果


 iThome鐵人賽
iThome鐵人賽