
接著讓我們來講一下看到神經網路模型結果後該怎麼調整。
昨天我們利用了三張自製手寫數字圖片去測試我們實作出的辨識系統,然而只有其中兩張(number_print & number_paint)成功辨識出數字2,寫在紙上拍照的number_handwritten會錯誤辨識成3或6。看了一下辨識結果我們推論可能是因為前處理不夠、照片陰影雜訊讓結果無法辨識等。
而當預測結果不如預期時,除去資料(樣本)本身如收集不全、noise前處理等問題外,對於模型(model)效果不好時,通常我們會先看模型的訓練結果好不好,並同時問 誤差(error)來自哪裡。確定模型訓練ok後,但測試結果不ok,則才會進一步探討它是不是 overfitting。
今天我們會介紹以下幾個概念,包含:
ps.這邊指的測試多是訓練的驗證集,意義劃分可以看 [DAY13] 資料的劃分-訓練集(training set)、驗證集(validation set) 與 測試集(testing set)
當我們說「訓練結果不好」,通常指的是:
如果模型的訓練效果不好,代表它一開始就沒學好(underfitting),沒有 fit 到我們的目標,所以要重新訓練重新學習。
平常我們會問「error 在哪裡 / error 是從哪裡來的」,是因為當我們分析模型誤差結果時,會把它歸類是 bias(偏差/準確度) 或 variance(穩定性) 問題,再去作相對應的處理。
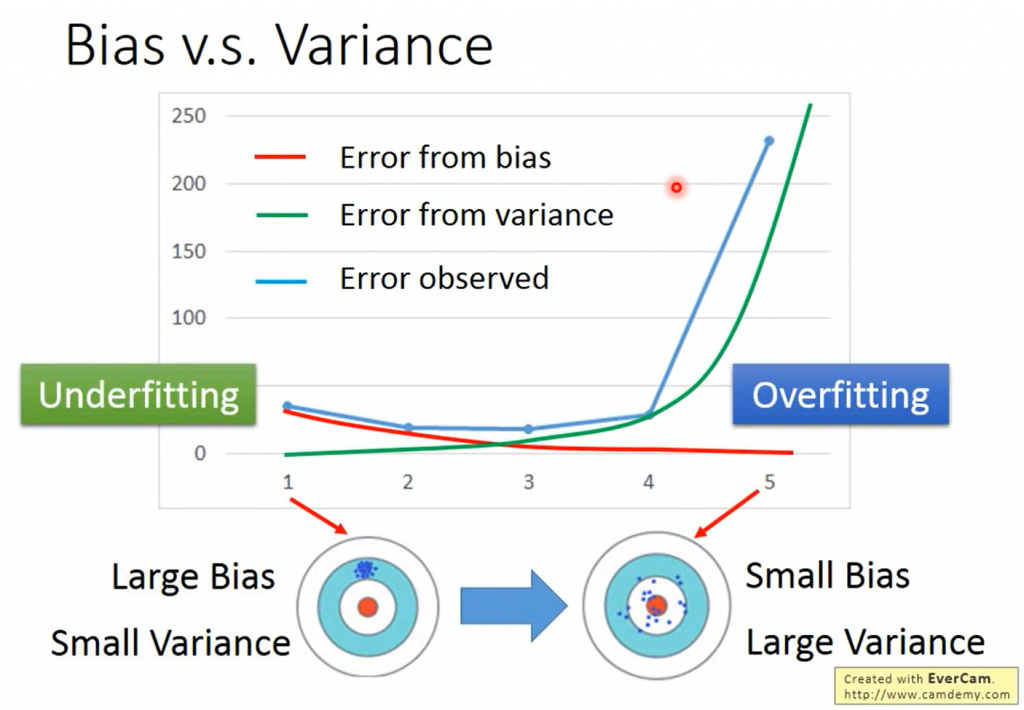
圖片來源: 李宏毅老師機器學習課程(2017)[註1]
我們可以看一下上面這張圖,通常我們 loss function 可以看到的結果(error observed)是結合 Bias 跟 Variance 的。
ps. loss function 的介紹 → [DAY9] 評估 NN model 好壞的指標-損失函數(loss function)

圖片來源: 李宏毅老師機器學習課程(2017)[註1]
若是 bias 偏差大,代表你的模型沒辦法 fit 你的訓練資料(training data),所以增加訓練資料想提高正確率這個舉動是沒有效果的。這就像機器學習三步驟的第一步,你找了一個模型,但你的目標(target)卻不在裡面。若 bias 大,這邊的建議是可以嘗試把 model 變得更複雜一點(redesign your model structure),例如增加網路架構層數及每層 neuro 個數等。
而若你的 bias 小 (target 在你的模型裡了),但 variance 方差大,也就是使用不同資料驗證時,發現有結果誤差很大,穩定性不夠。這時候就可以增加訓練樣本(input more data),或對權重做正規化( regularization, smooth the function)等。上面提到的兩種方法都可以增加新資料的適應能力,讓資料在幾何意義上更平滑集中在你的funciton set,但做這些動作的同時,bias可能就變大了。
上面 variance 的意義有點文言,簡單來說就是驗證時若發現是 variance大 的問題,那就是 overfitting 了。
overfitting,中文會翻成過擬合,也就是過度學習,與訓練資料過度適配的意思。如果以 day13 大考的例子來比喻,這種在訓練結果很好,測試/驗證結果很差的模型,就像遇到題目完全死記硬背,但考新題目就不行了。
圖片來源:Day 5 / 必備實作知識與工具 / 關於 Training,還有一些基本功(一)
今天我們講了當我們遇到神經網路模型結果時,該怎麼做實作調整的方向介紹。我們會考慮到底是模型訓練部分的問題,還是模型測試部份的問題。也等同 bias 跟 variance 我們該怎麼調整與平衡。
明天來講實務改善步驟與我們手寫辨識系統的結果舉例~
[註1] ML Lecture 2: Where does the error come from?
[註2] Day 5 / 必備實作知識與工具 / 關於 Training,還有一些基本功(一)

 iThome鐵人賽
iThome鐵人賽