昨天我們介紹了神經網路模型的調整方向,讓手寫辨識系統變的更符合我們預期。我們會考慮到底是模型訓練部分不夠好需要做修正,還是模型測試部份問題,這種狀況也等同 bias 跟 variance 我們該怎麼調整與平衡。
今天講的是神經網路模型調整的一些步驟,這邊推薦看李宏毅老師機器學習課程第九單元,來了解實際是怎麼修正的。
ML Lecture 9-1: Tips for Training DNN (1hr30min) → 修正步驟詳細教學
ML Lecture 9-2: Keras Demo 2 (15min) → 實例 demo 程式示範
ML Lecture 9-3: Fizz Buzz in Tensorflow (sequel) (6min)→ 用 Neural Network 硬 train 一發解經典 FizzBuzz 問題。這集示範了若訓練資料表現不好,可以增加網路架構層數及每層 neuro 個數等,結果會不一樣(超好XD)
而下面是當我遇到模型結果不如預期時會做的一些調整,會根據我遇到問題它需要的目標和有多少時間修正,可以參考看看~
當訓練結果不好的時候,可實行的步驟有:
那如果訓練結果好,但**測試結果不好(overfitting)**的時候,可實行的步驟有(調整看情況使用,沒有順序之分):
停在訓練時驗證的 loss 最小的地方,不要再訓練下去。
上圖來源:李宏毅老師的機器學習課程。下圖為實作情形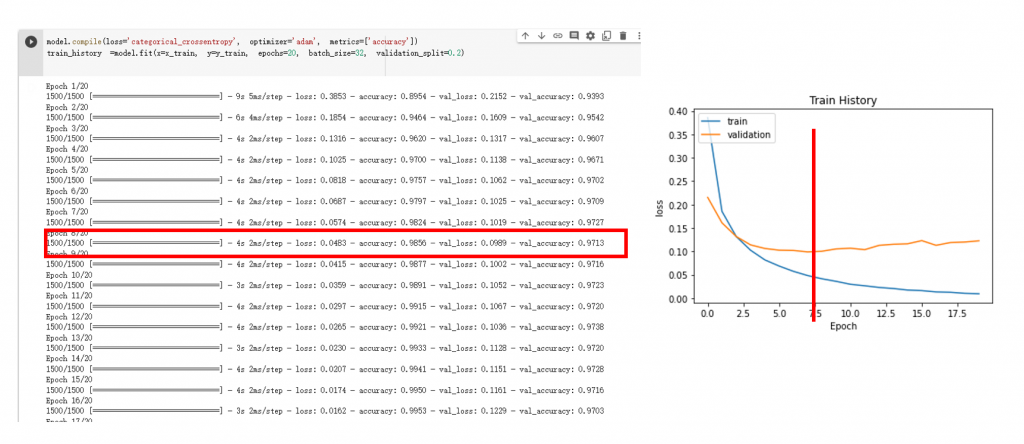
昨天有提到,當發生 overfitting 的情形時,可以對權重做正則化( regularization),讓影響力比較大的權重不要影響那麼大,達到平滑化曲線的目的(smooth the function)。
正則化有分成 L1 跟 L2 兩種,可以看一下莫凡的什麼是L1 L2 正規化 正則化 Regularization 了解它是什麼及怎麼用。不過要注意使用正則化時可能會影響到 bias,讓 bias 變大 → 可見 [DAY17] 實作結果與調整方向-概念介紹(tips) 瞭解更多
這邊附上 Keras 官網加正則化的公式連結,不過較少看到用在入門的神經網路模型就是。
在訓練時加入 dropout 層(ex.model.add(Dropout(’0.5’))),隨機丟掉某些神經元。這個動作雖然會讓訓練結果變差,但反而會讓測試結果變好。
ps. dropout 是什麼請見李宏毅老師的機器學習課程 (1:10:20-1:26:00),影片解釋的很清楚!
樣本越多越能接近問題真實情形,但很多時候我們沒有辦法蒐集到更多樣本,以及要注意蒐集到的更多樣本有沒有樣本類型不均勻等情形。
ps. 這邊我想提一下訓練集的 loss 跟測試集的 loss 可能是會有差距的,所以在 batch size 的選擇上通常我們不會設太大,避免訓練結果跟測試結果差距太大。→ batch 的介紹可見 [DAY11] NN model 的訓練設定-訓練週期(epoch) 與 批次(batch)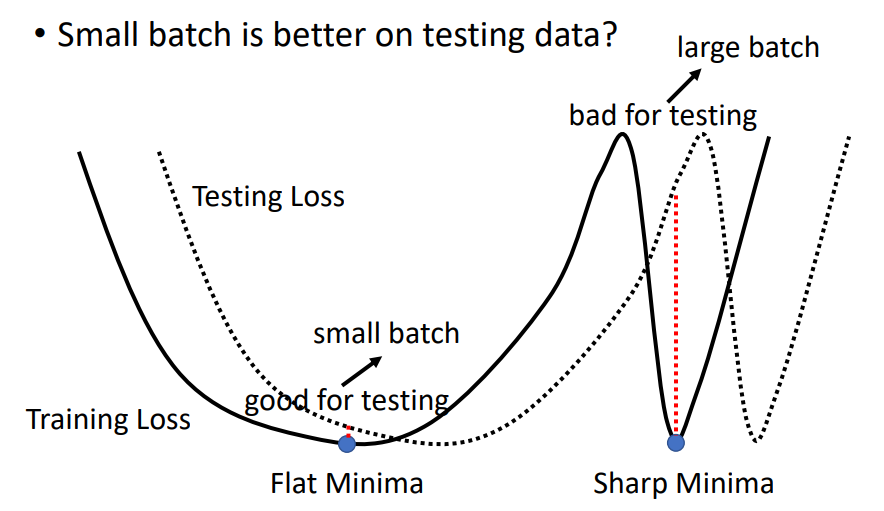
圖片來源:李宏毅老師機器學習課程(2021)
這兩天我們講了修改神經網路的一些方法跟步驟,讓模型變得更符合我們預期。
不過實作機器學習相關模型時,還是會根據我遇到問題它的目標和我有多少時間去改去調,譬如說花多十倍的時間只為了提升 1% 的正確率值得嗎?這要看你的目的來判斷。
接下來我們會來簡單講講神經網路有哪些、他們之間的關係又是怎麼樣,並對用神經網路實作手寫數字辨識系統這一段做個總結。
我們明天見!

