語言模型(Language Models)是判斷一定長度的文字出現在句子的機率,生活中的語言模型你一定用過,而且每天有數十億人在用,可以算是最常用的 NLP 應用程式。
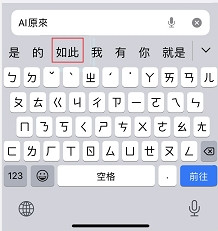
ーー 手機上的輸入法,根據你輸入的單字推測你下一個要輸入的字
自然語言處理(NLP,Natural Language Processing)是指讓機器處理及運用人類的語言。
循環神經網路(RNN,Recurrent Neural Network) 是和 CNN 並列深度學習的兩大基本模型,如果說 CNN 是處理圖像的模型,RNN 可以說是處理語言的模型,主要是處理有序列關係或者說是有時間性質的資料,比如說:
時間順序的數字,例如冰淇淋販賣數量
夏天賣得比冬天好,白天天氣熱賣得比晚上好等等。
文本資料
文章的前後句關係,句子構成的前後單字。
影像或語音
影像也屬於前後連續的圖片,語音也如同文字一樣有時間的前後關係。
剛剛舉的例子,和時間有前後關係的資料我們稱作時間序列資料。
除了本身就是數據的資料,其他資料要怎麼轉成讓電腦看得懂的輸入資料呢?
聲音主要是靠空氣中聲音的震動產生的類比訊號,所以需要轉換成電腦看得懂的數位資料:
透過脈衝編碼調變(PCM,Pulse-code modul)轉換類比訊號到數位資料。
ーー出處:PCM
使用快速傅里葉變換 (FFT,Fast Fourier transform) 將音頻轉換為周波數頻譜(spectrum)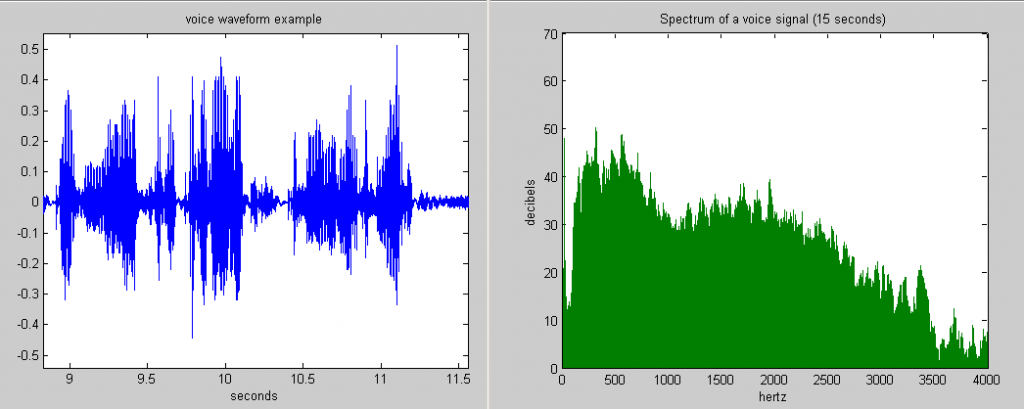
ーー左:音頻信號,右:周波數頻譜。出處:FFT
最後透過梅爾頻率倒譜係數(MFCC,Mel-Frequency Cepstrum
Coefficients) 轉換成特徵向量。
而要將聲音轉換成單詞可以透過隱藏式馬可夫模型(Hidden Markov model,HMM),透過音素(Phoneme)特徵向量,對照著音素列-單詞的字典,找出機率最高的幾種單詞,再根據前後文的順序經由語言模型找出最有可能的單詞。
音素是人類能夠區別意義的最小聲音單位。
附帶一提, DeepMind 創造的 WaveNet,可透過文本(Text)產生語音,不過是透過 CNN 而非 RNN 技術。
連續出現的 n 個單詞叫做 n 元語法,假設有一個句子:「AI 原來如此」。
n-gram 可以拿來預測接下來出現的單詞,比方說 3-gram,「AI 原來__」,如果本系列的文章出現在語料庫的機率夠高,可以知道後面會是「如此」。是一種常見的語言模型。
而 n-gram 可以將其轉成獨熱向量用數字來表示文字。
在 Day 14 有提過只有一個 1 其他為 0 稱為獨熱。
假設我們有3個單詞的詞彙表,其獨熱向量會是這樣:
'AI' = [1 0 0]
'原來' = [0 1 0]
'如此' = [0 0 1]
透過獨熱向量可以做加法計算出每組的出現頻率。
'AI原來如此' = [1 0 0] + [0 1 0] + [0 0 1] = [1 1 1]
'AI原來原來如此' = [1 0 0] + [0 1 0] + [0 1 0] + [0 0 1] = [1 2 1]
像這樣用加總完的向量表示單詞的出現頻率叫做詞袋(BoW,Bag of Words)。
而 2 個連續單詞的詞袋可以稱做 Bag-of-2-grams,以此類推。透過單詞頻率可以看出每個單詞在文章的重要性。而重要性可以透過 TF-IDF (Term Frequency – Inverse Document Frequency)表示。
| 名稱 | 意思 | 計算範例 |
|---|---|---|
| TF | 某文章出現某單詞的機率 | 1篇文章1000個單詞,「AI」出現30次=0.03 |
| DF | 某單詞出現在各文章的機率 | 100篇文章有25篇出現 「AI」=0.25 |
| IDF | DF 倒數的對數 | |
| TF-IDF | TF 和 IDF相乘 |
早期透過 one-hot vector 可以當作 RNN 的輸入,但是 one-hot vector 和 之前提過的 one-hot encoding 一樣,文章的句子一多,詞彙表的單詞數就增加,one-hot vector會變得非常巨大,產生非常多個 0 (資料稀疏,Data sparsity)並造成維度的詛咒,而且每個單詞獨立存在,看不出和其他單詞的相關性。
單詞的數目多=特徵的數目多=維度的數目多=非常高維
那要怎麼解決這種高維度的問題呢?2013年由 Google 的 Tomas Mikolov 提出的 Word2Vec(word to vector),透過 CBOW 和 Skip-gram ,不只解決高維度的問題,還可以用向量的的距離和位置關係表示出單詞的意思。
CBOW(Continuous Bag-of-Words)
用周邊的字預測某個字。
AI 原來 __ 互助 就此 開始。
如左圖:用前後字預測 w(t)。
Skip-gram
用某個字預測周邊的字。
__ __ 如此 __ __ __
如右圖:用 w(t) 預測前後字。
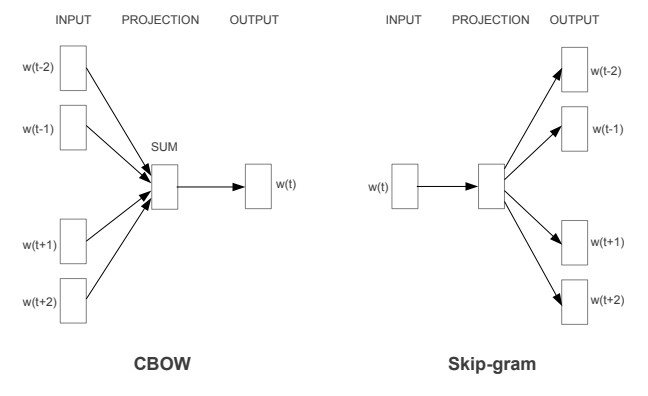
ーー出處:Word2Vec 論文
有沒有覺得這個圖似曾相似?沒錯,就是做神經網路的分類問題!以 Skip-gram 為例,拿 w(t) 的 one-hot vector 當輸入去找出其他詞句的出現機率(分類)當輸出。
所以只需要大一點的語料庫,就可以透過文本的分布直接做無監督式學習!實際上拿大量新聞做訓練的 word2vec,將取得的單字關係做主成分分析(PCA)投射到 2 維的話可以呈現下圖單詞之間的關係。
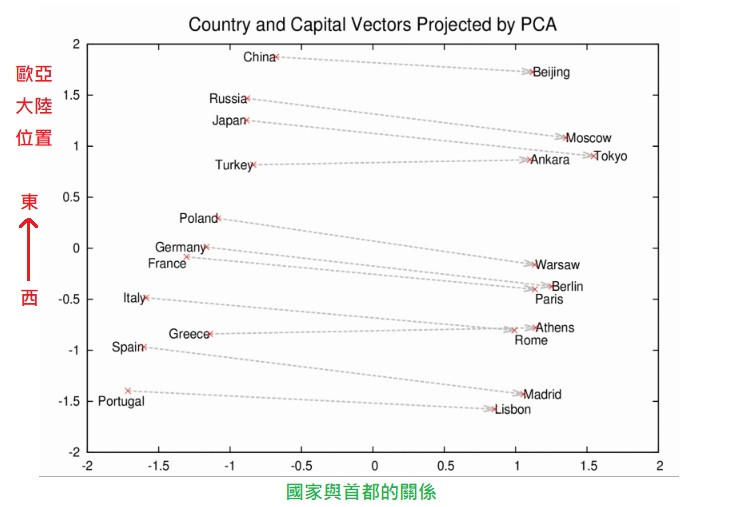
ーー原圖出處:Google Open Source Blog
這種將所有單詞的高維空間嵌入到一個較低維度的連續向量空間(例如上圖的 2 維空間),就叫做詞嵌入,詞嵌入向量是預先訓練好的資料可以作為 RNN 的輸入層。
而透過上圖,還可以藉由向量的加減去捕捉到單詞之間的關係,比方說
巴黎 - 法國 + 波蘭 = 華沙 (Paris - France + Poland = Warsaw)
找到相對於巴黎,波蘭對應的首都是華沙。類似的例子還有鼎鼎有名的
國王 - 男人 + 女人 = 王后 (King - Man + Woman = Queen)
嚴格講起來並沒有完全相等,只是最近的單詞是王后。
另外兩個單詞的相似性可以透過計算兩個向量的餘弦角度(cosine) ,接近 1 代表相似。圖片的特徵向量也可以透過這樣的計算去看圖片相似度。
fastText
2013年 Tomas Mikolov 使用 word2vec為基礎開發出來的手法,
即便訓練集裡面沒有的單字(OOV,Out Of Vocabulary)也能對應。
ELMo(embeddings from language models)
word2vec 雖然可以看出和其他詞的相關性,卻無法表現出一詞多義的性質,ELMo 透過之後會介紹的 bi-LSTM(雙向 LSTM)可以理解上下文的分布,同一個詞根據不同語意可以有不同的詞嵌入向量。
今天說完了作為輸入的時間序列資料,明天就來介紹 RNN 具體是怎麼做這些資料處理。


 iThome鐵人賽
iThome鐵人賽