介紹完梯度下降的改善,就來看學習完成後的模型有哪些方法可以做改善,來達到我們想要的準確度。
一開始說過我們最終是要將未知資料拿來做模型的驗證,所以即便已知資料的訓練集效果很好,未知資料的測試集效果很差也沒有意義。這種學習過頭也就是訓練時的誤差(Train Error)小,但是測試時的誤差(Test Error)大,只對訓練集預測很好的情形我們之前提過叫做過度擬合。但是學習不給力,連訓練誤差都很大,叫做欠擬合。
日文把過度擬合和欠擬合叫做過學習和未學習,我覺得也蠻貼切的。
| 欠擬合 | 理想學習 | 過度擬合 |
|---|---|---|
 |
 |
 |
欠擬合(Underfitting)
訓練誤差和測試誤差都大。
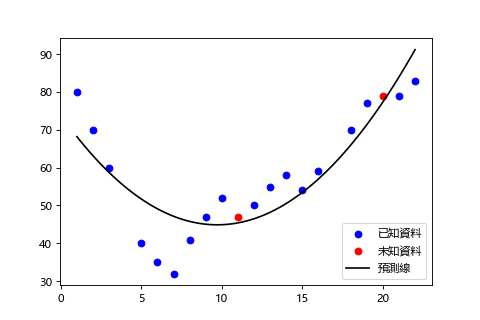
理想學習
訓練誤差和測試誤差都小。
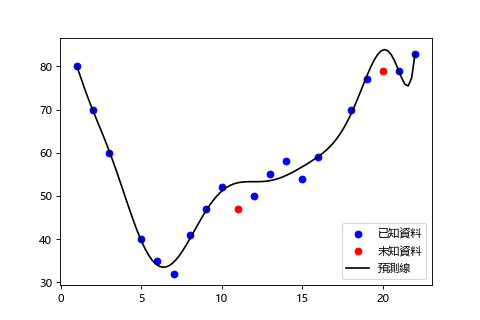
過度擬合(Overfitting)
訓練誤差小,測試誤差大。
高維度我們無法直接看到訓練的狀況,可以透過下面的圖用訓練誤差和測試誤差來判斷是過度擬合還是欠擬合。
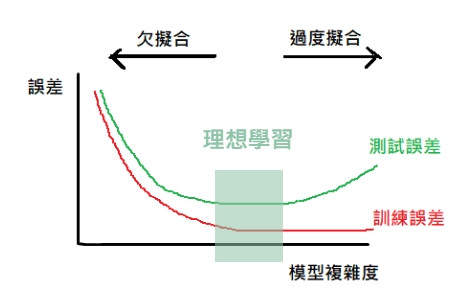
為了防止過度擬合,有一些手法可以使用,其中一種限制學習過程中權重的作用,防止學習結果被權重過大的訓練資料所淹沒。叫做正則化。
正則化通常是針對損失函數的 w(權重) 增加懲罰項(Penalty), 有以下幾種:
Dropout 是每次 epoch 時隨機丟棄一部分感知器的方法。由於每次學習都是不同構成的神經網路,和集成學習有異曲同工之妙。某種程度上也被當成正則化的一種。
避免過度擬合還有一個手法就是提前停止。
也就是在學習的過程中,當測試誤差開始向右上升時停止學習。
由於每個演算法都可以使用這個手法也沒有什麼成本,相對於沒有免費的午餐定理,
Jeffrey Hilton 教授稱這種技術為美麗的免費午餐。(Early stopping (is) beautiful free lunch)
必須注意提前停止的時機,有時候即便是誤差上升,之後會再度發生下降的現象,這種雙重下降現象(double descent phenomenon)導致如果太早停止學習反而會錯過更好的學習成果。像是後面會介紹的 CNN,ResNet,Transformer 等都會發生,通常會使用正則化來避免。
分析不同資料時,特徵有的數值大,有的數值小,單位也彼此不同,比如身高(cm)和體重(kg)。為了排除這些數值上極大的落差,在訓練之前會使用正規化或標準化將數值收斂在一定範圍,所以叫資料前處理。有兩個好處:
加速學習
可以減少梯度下降的學習時間。
提高精準度。
由於數值落差造成的影響,會導致一些演算法的結果失真,標準化後可以使得特徵做出較一致的貢獻。
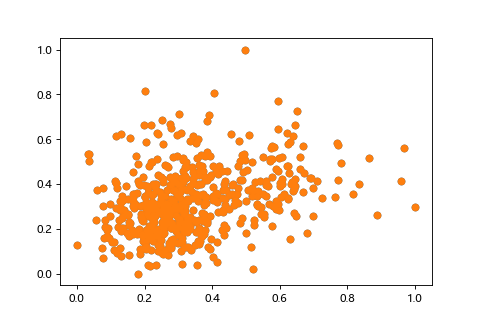
調整輸入資料將每個特徵值照比例轉換為 0 到 1 範圍。
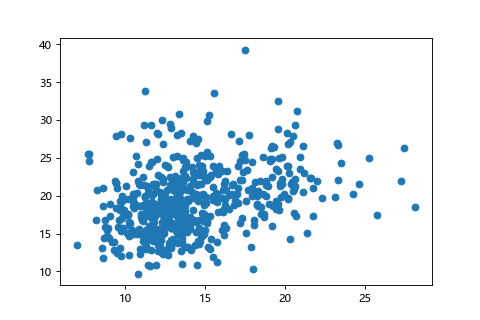
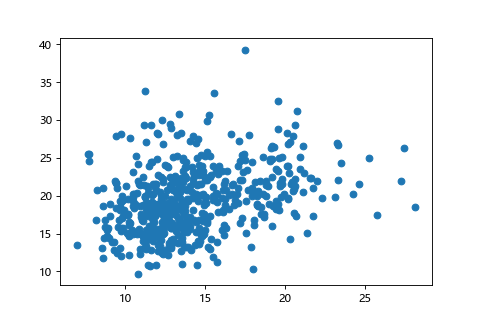
| 正規化前(X:0~30,Y:0~40) | 正規化後(X:0~1,Y:0~1) |
|---|---|
 |
 |
每一層的資料在使用激勵函數之前進行正規化的方法稱為批量正規化。
可以抑制過度擬合。
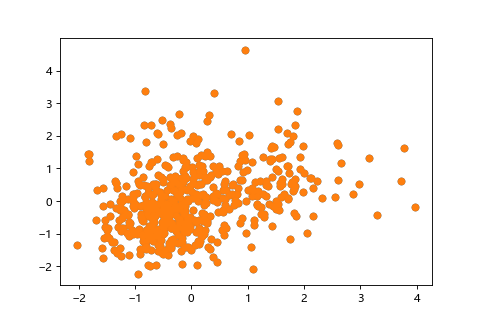
將特徵轉換成平均(mean)為0,方差(又叫變異數,variance)為1,使其遵循常態分佈。
有的書會寫方差為1或標準差為1,都沒有錯,因為標準差的平方就是方差,1的平方還是1。
| 標準化前(X:0~30,Y:0~40) | 標準化後(平均0,方差1) |
|---|---|
 |
 |
類似主成分分析,針對特徵做去相關性後做標準化。
| 白化前(正相關) | 去相關性後 | 標準化後 |
|---|---|---|
 |
 |
 |
由於機器學習只能接受數值資料,像地名或產品名就不適用於數值,會改用 One-hot Encoding。簡單說就是有 n 個類別, m 筆資料就會有一個 n × m 的表格,屬於哪個類別,那個類別欄為 1,其他類別欄為 0。
只能有一個 1 其他為 0 稱為獨熱(One-hot)。
原始資料:
| 國籍 | 年紀 | 收入 |
|---|---|---|
| France | 42 | 100000 |
| Japan | 36 | 80000 |
| Taiwan | 31 | 70000 |
One-hot Encoding:
| France | Japan | Taiwan | 年紀 | 收入 |
|---|---|---|---|---|
| 1 | 0 | 0 | 42 | 100000 |
| 0 | 1 | 0 | 36 | 80000 |
| 0 | 0 | 1 | 31 | 70000 |
One-hot Encoding 目前在 Kaggle 競賽中常被其他替代方案取代,原因是因為 one-hot encoding 會導致特徵數變多,以及資料中出現非常多個0。

