昨天講解完 RNN 的輸入資料是怎麼來的,今天要來介紹 RNN 基本架構和 RNN 具體可以做些什麼。
RNN 之所以可以處理時間序列資料,在於會把過去(前一個單詞)的特徵也傳遞給下一個。一個傳一個帶有循環的網路,讓資料持續存在(有記憶性),所以叫循環神經網路。
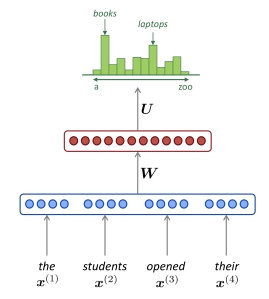
比方說 "the students opened their" (學生們打開他們的...)預測接下來會出現的單詞(書或筆電)。RNN 會將句子的每個單詞轉成詞向量當輸入,將隱藏層狀態傳給下一個詞。
| 一般神經網路 | RNN |
|---|---|
 |
 |
| 輸入必須固定(以文章來說不太實際) | 輸入可隨序列增加,參數是層層傳遞不會增加(很好) |
ーー出處:CS224n: Natural Language Processing with Deep
Learning
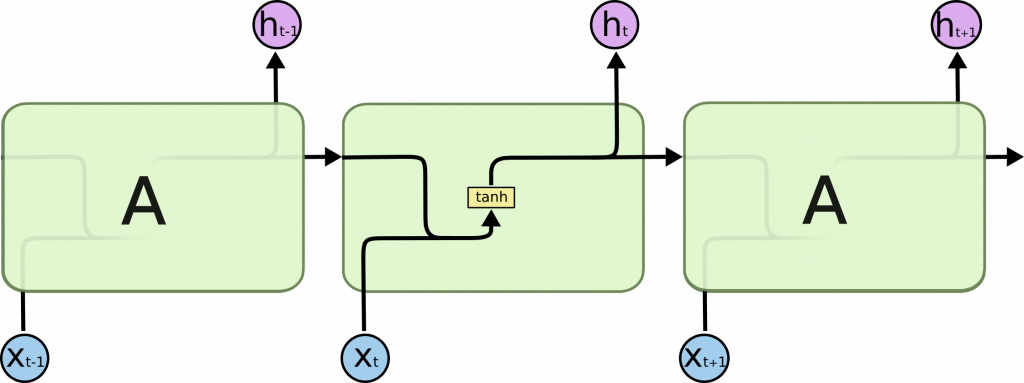
實際上 RNN 的隱藏層內部長這樣:
| 隱藏層 n | 隱藏層 n+1 |
|---|---|
 |
 |
| 上個隱藏層狀態+本層輸入=新的隱藏層狀態 | 新的隱藏層狀態傳給下一層 |
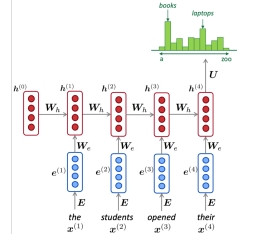
以自然語言處理為例,句子照著單詞順序分成好幾個時間步驟(timestep),每個時間步驟將該單詞轉為詞向量(one hot 向量 或 詞嵌入向量)作為輸入和上一層的結果結合後傳給下一層。激勵函數則是使用 tanh。

ーー 上述動畫出處均為:Illustrated Guide to LSTM’s and GRU’s
用數學式表示的話:
本層狀態=RNN(上層狀態,本層輸入)=tanh(上層狀態的權重和偏差+本層輸入的權重和偏差)
學習(參數調整)則是一樣做反向傳播,只是因為是順著時間軸反著做,所以叫隨著時間反向傳播(BPTT,Backpropagation Through Time)。
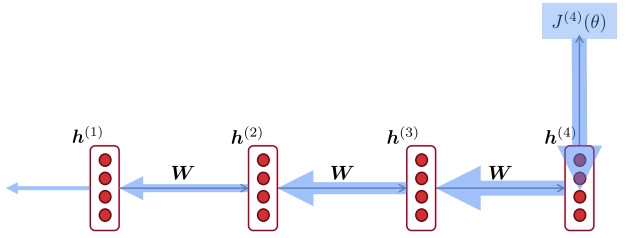
ーーBPTT,出處:CS224n: Natural Language Processing with Deep
Learning
一般的神經網路以及CNN,輸入和輸出的大小是固定的,而 RNN 的優勢在於可以透過序列做一對多,多對一,或者是多對多的應用,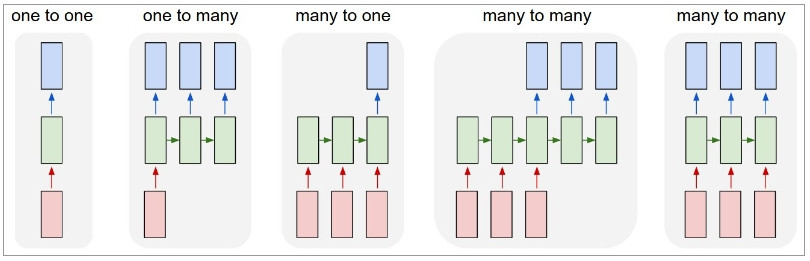
ーー 出處:The Unreasonable Effectiveness of Recurrent Neural Networks


但是這個基本的 RNN 也有幾個需要解決的問題:
梯度消失
隨著時間拉長,反向傳遞越往前面梯度會越來越小,越前面的時間步驟(越早的資料)無法作有效的學習修正,也就是說 RNN 只能短期記憶,太久遠之前的資料無法記住。
輸入權重衝突 (input weight conflict)
一般的神經網路中,不重要的輸入,權重會變小,重要的輸入,權重會變大。但是 RNN 的場合,這個輸入現在不重要,但是將來很重要,同時有著權重應該要變小還是要變大的矛盾存在(輸入權重衝突)。而相對的,這個輸出現在不重要,但是將來很重要這種矛盾叫做輸出權重衝突(output weight conflict)
一般神經網路使用激勵函數 ReLU 來取代 sigmoid 來改善梯度消失,而 RNN 不替換激勵函數而是使用了改善後的模型 LSTM 或 GRU 同時解決上述兩個問題。
它們共通的概念是,忘記不重要的資料,只保留重要訊息來做預測。
比如說下面的文字,只記憶重要的評語「令人讚嘆!」(Amazing!),「肯定再次購買」(buying again),進而推論這是一個好產品。
ーー 出處:Illustrated Guide to LSTM’s and GRU’s: A step by step explanation
| RNN | LSTM |
|---|---|
 |
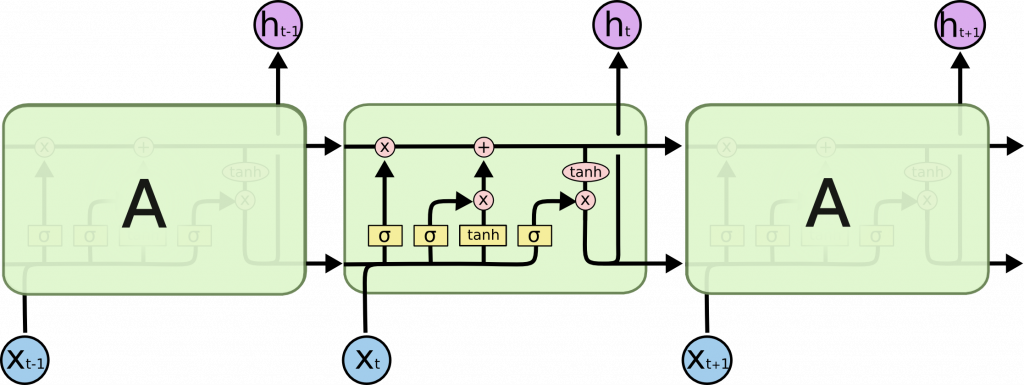 |
LSTM 有以下兩個構成:
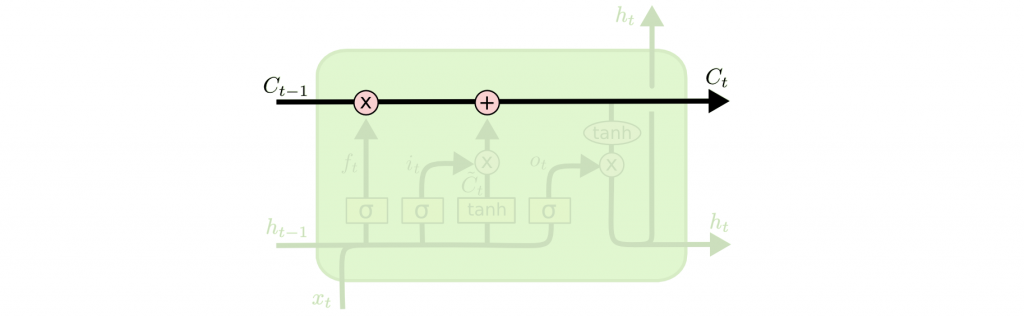
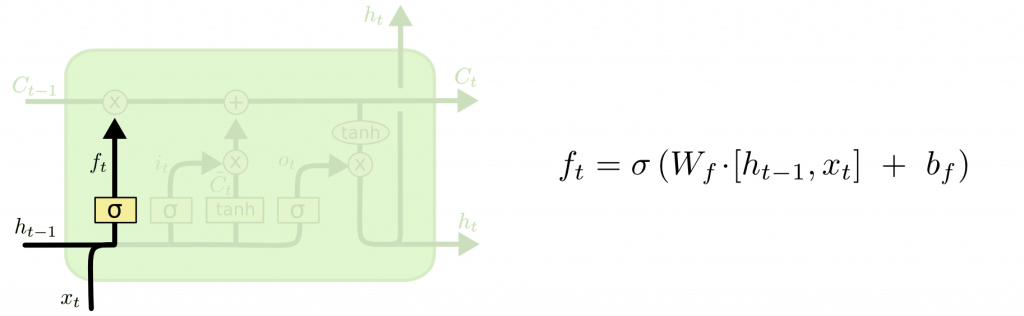
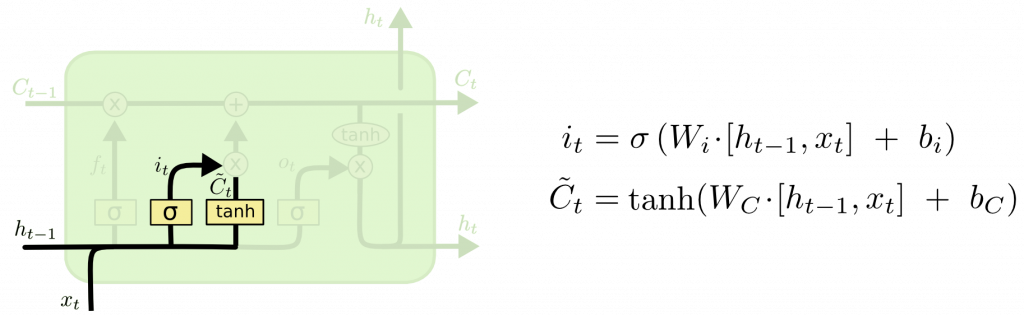
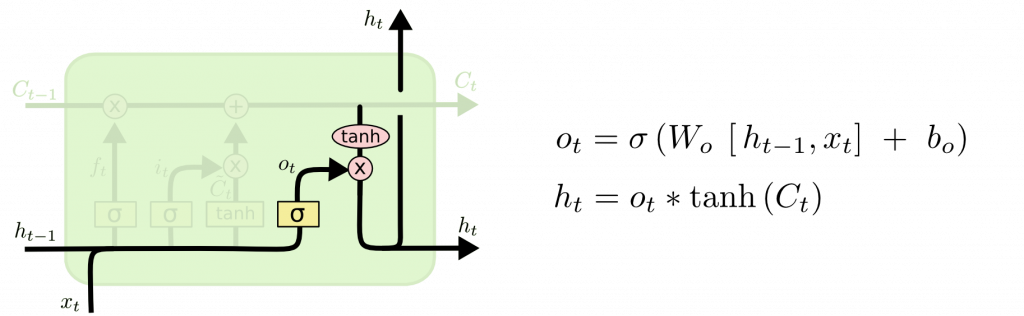
簡化版 LSTM。不使用細胞狀態,而採用了下列兩個門來取代輸入門,輸出門,忘記門。
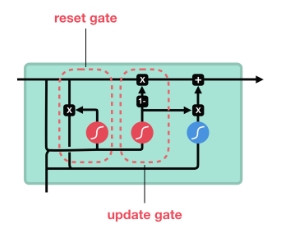
ーー 出處:Illustrated Guide to LSTM’s and GRU’s
比起 LSTM 因為參數較少所以計算較快,但是長期記憶性則是 LSTM 較好。
組合兩個 RNN,一個用過去的資料作預測,一個反向用未來的資料作預測。合併雙方的隱藏狀態當作當前的狀態,透過雙方向的預測可以讓預測準度提高。
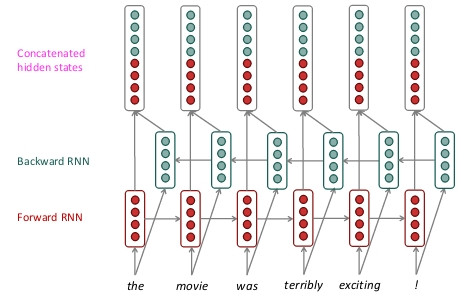
ーー出處:CS224n: Natural Language Processing with Deep
Learning
舉例來說:
我不喜歡你,我愛死你了。
如果照著一般的順序做預測,可能心都要碎了,但是搭配著反過來的預測結合上下文,就會知道重點其實是愛你的。
在程式使用上只需要把 RNN 模型的 Bidirectional 設成 True 就可以了。
目前介紹的 RNN,預測都是單一個輸出,想要預測連續的輸出可以使用 Seq2Seq(Sequence to Sequence)。例如英文句子預測出中文的句子。
Seq2Seq 也是通過組合兩個 RNN,一個當編碼器,一個當解碼器來支持可變數量的輸出。
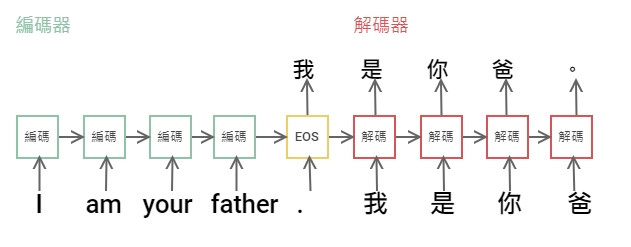
ーー Starwars 經典台詞。EOS = End of sentence
另外,一般說的編碼器-解碼器,不一定都要由 RNN 所組成。例如在圖像摘要中,編碼器是處理輸入圖像的 CNN,而解碼器是生成語言描述(自然語言處理)的 RNN。
Google 翻譯從2016年起捨棄了以往的統計式機器翻譯(SMT)改採用神經網路的神經機器翻譯(NMT,Neural Machine Translation)架構,大幅提升了翻譯的準確度。最初版就是使用 Seq2Seq。


 iThome鐵人賽
iThome鐵人賽